Awesome Efficient LLM
1.0.0
Куратор для эффективных крупных языковых моделей
Если вы хотите включить свою статью или вам нужно обновить какие -либо данные, такие как информация о конференции или URL -адреса кода, пожалуйста, не стесняйтесь отправить запрос на вытяжку. Вы можете генерировать необходимый формат маркировки для каждой статьи, заполнив информацию в generate_item.py и выполнить python generate_item.py . Мы тепло ценим ваш вклад в этот список. В качестве альтернативы, вы можете написать мне по ссылкам на вашу статью и код, и я бы добавил вашу статью в список с моим ранним удобством.
Для каждой темы мы курировали список рекомендуемых документов, которые собрали много звезд или цитат GitHub.
| Название и авторы | Введение | Ссылки |
|---|---|---|
SPARSEGPT: массивные языковые модели могут быть точно обрезаны в одном выстреле Элиас Франтар, Дэн Алистарх | 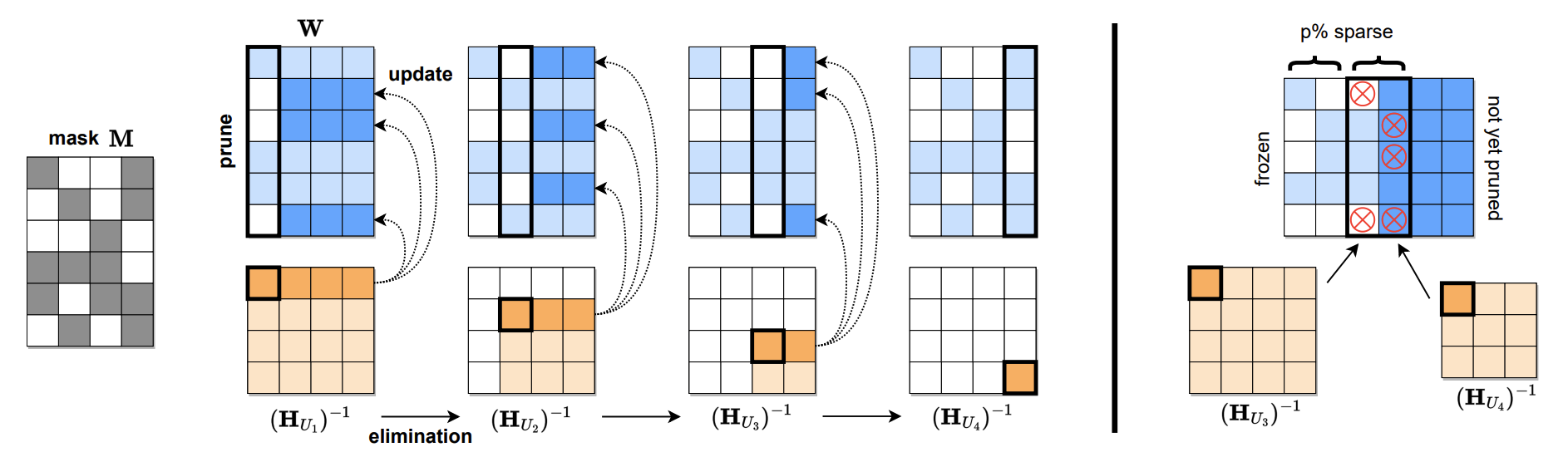 | Github Paper |
LLM-Pruner: О структурной обрезке больших языковых моделей Синьин М.А., Гонгфан Фанг, Синчао Ван | 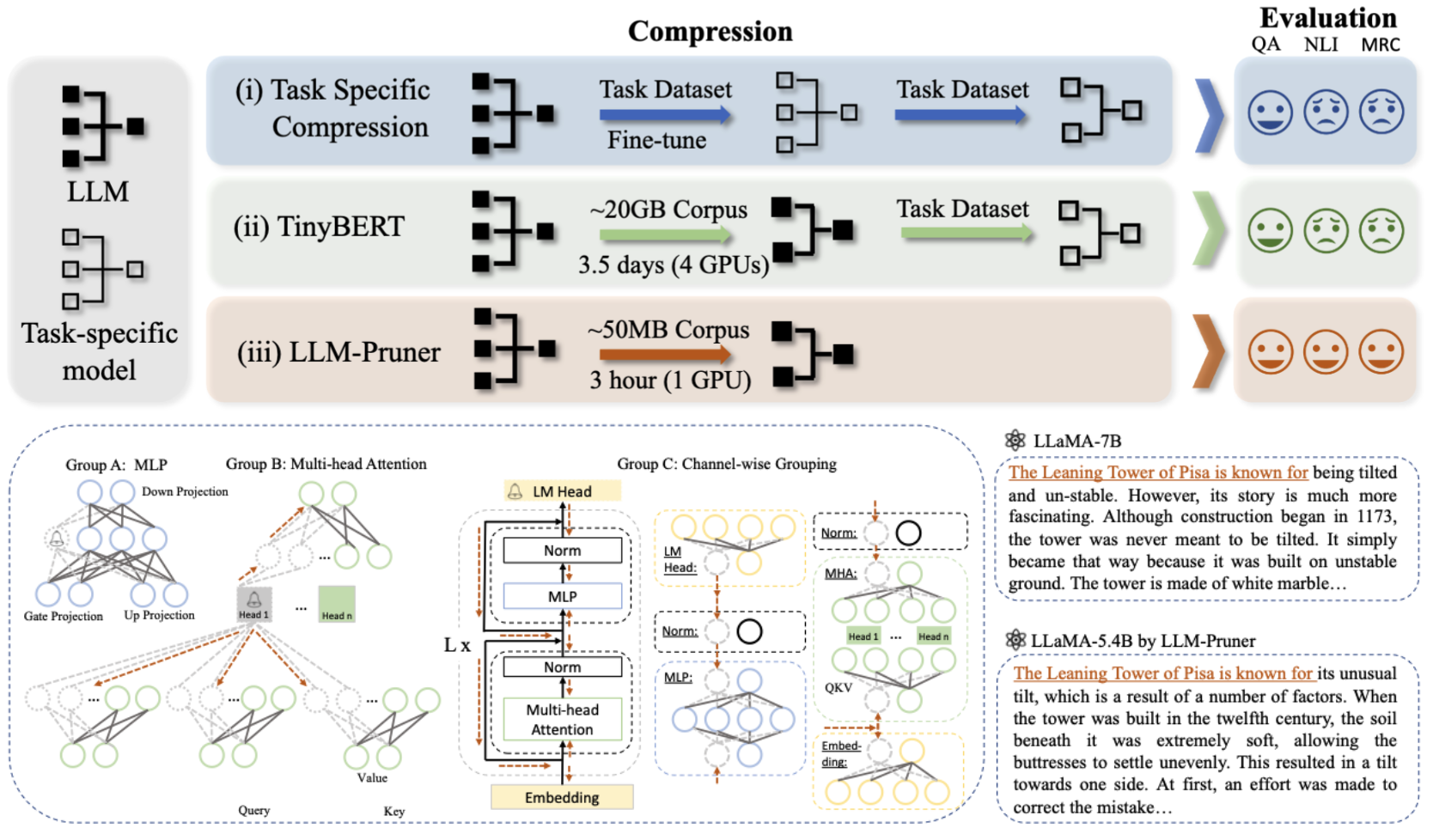 | Github Paper |
Простой и эффективный подход обрезки для больших языковых моделей Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter | 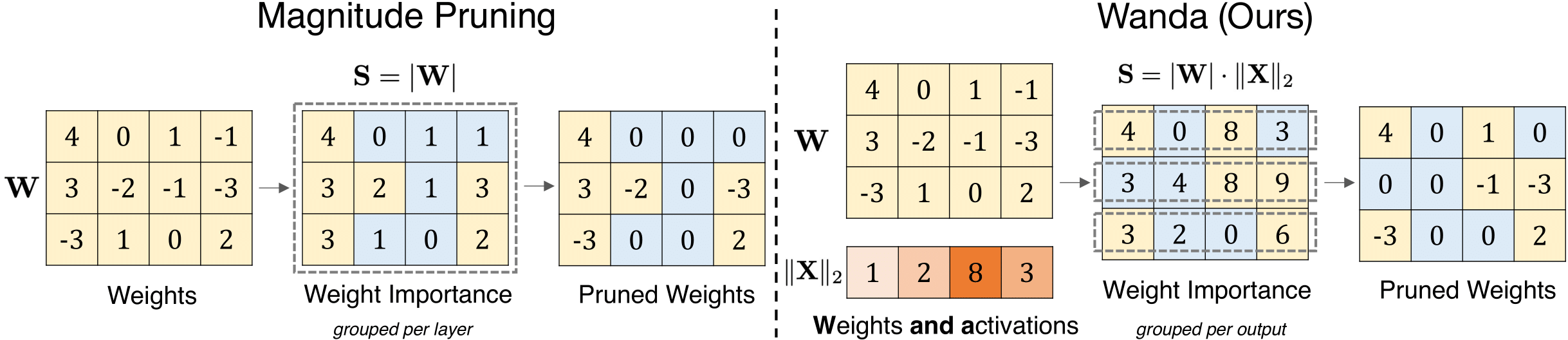 | GitHub Бумага |
Сдвиг лама: ускоряющая языковая модель предварительной тренировки через структурированную обрезку Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen | 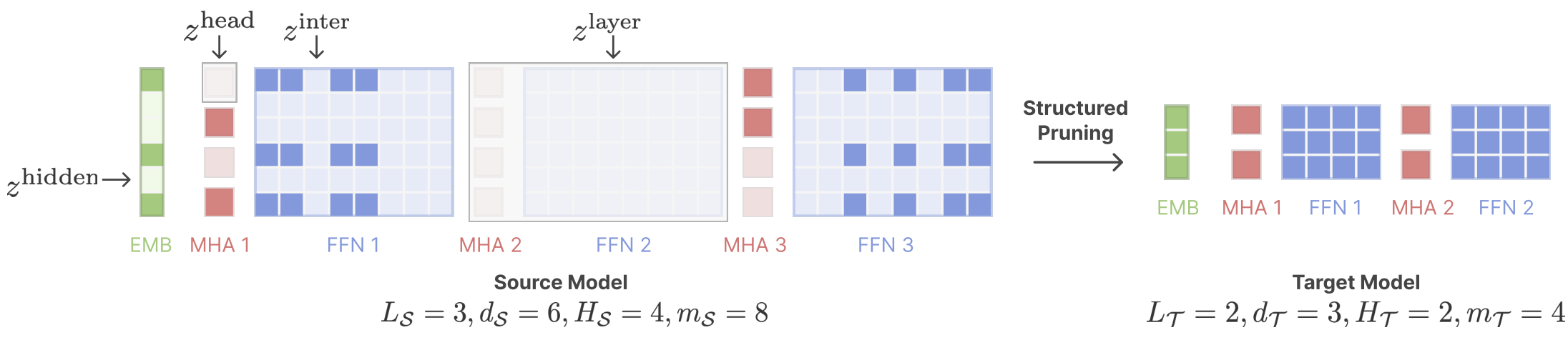 | GitHub Бумага |
| Эффективный вывод LLM с использованием динамического обрезки ввода и маскировки с учетом кэша Марко Федеричи, Давиде Белли, Март Ван Баален, Амир Джалалирад, Андрие Склиар, Бенс Майор, Маркус Нагель, Пол Уайтмо | Бумага | |
| Головоломка: NAS на основе дистилляции для вывода, оптимизированных LLMS Ахиад Беркович, Томер Ронен, Талор Абрамович, Нир Айлон, Нав Асаф, Мохаммад Даббах и др. | Бумага | |
Переоценка обрезки слоя в LLMS: новые идеи и методы Yao Lu, Hao Cheng, Yujie Fang, Zeyu Wang, Jiaheng Wei, Dongwei Xu, Qi Xuan, Xiaoniu Yang, Zhaowei Zhu |  | GitHub Бумага |
| Важность слоя и анализа галлюцинации в моделях крупных языков с помощью расширенной дисперсии активации Zichen Song, Sitan Huang, Yuxin Wu, Zhongfeng Kang | Бумага | |
AMOEBALLM: построение моделей крупных языков в форме для эффективного и мгновенного развертывания Yonggan Fu, Zhongzhi Yu, Junwei Li, Jiayi Qian, Yongan Zhang, Xiangchi Yuan, Dachuan Shi, Roman Yakunin, Yingyan Celine Lin | GitHub Бумага | |
| Закон о масштабировании после тренировки после обрезки модели Сяодон Чен, Юксуан Ху, Цзин Чжан, Сяоканг Чжан, Куипинг Ли, Хонг Чен | Бумага | |
DRPRUNING: Эффективная обрезка модели большой языка посредством дистрибуции устойчивой оптимизации Hexuan Deng, Wenxiang Jiao, Xuebo Liu, Min Zhang, Zhaopeng Tu |  | GitHub Бумага |
Законодательство о разрешении: к крупным языковым моделям с большей разрешением активации Yuqi Luo, Chenyang Song, Xu Han, Yingfa Chen, Chaojun Xiao, Zhiyuan Liu, Maosong Sun |  | GitHub Бумага |
| AVSS: Оценка важности слоя в моделях крупных языков с помощью анализа дисперсии активации-сходства Zichen Song, Yuxin Wu, Sitan Huang, Zhongfeng Kang | Бумага | |
| Анализованная лама: оптимизация нескольких выстрелов в моделях обрезки Llama с конкретными подсказками Даньяль Афтаб, Стивен Дэви | Бумага | |
LLMCBENCH: сравнение сжатия модели с большим языком для эффективного развертывания Ge Yang, Changyi He, Jinyang Guo, Jianyu Wu, Yifu Ding, Aishan Liu, Haotong Qin, Pengliang Ji, Xianglong Лю |  | GitHub Бумага |
| За пределами 2: 4: Изучение V: N: M Sparsity для эффективного вывода трансформатора на графических процессорах Кан Чжао, Тао Юань, Хан Бао, Чженфенг Су, Чанг Гао, Чжаофенг Солнца, Зичен Лян, Липинг Цзин, Цзянфэй Чен | Бумага | |
Evopress: к оптимальному сжатию динамической модели с помощью эволюционного поиска Оливер Зиберлинг, Денис Кузнеделев, Эльдар Куртик, Дэн Алистарх |  | GitHub Бумага |
| Fedspallm: федеративная обрезка моделей крупных языков Гуанджи Бай, Йицзян Ли, Зилингхан Ли, Лян Чжао, Кибаке Ким | Бумага | |
Модели обрезки фундамента для высокой точности без переподготовки Пу Чжао, Фей Сан, Сюань Шен, Пинруи Ю, Чжэнлун Конг, Яньчхи Ван, Сюэ Лин | GitHub Бумага | |
| Самостоятельное использование для квантования и обрезки языковой модели и обрезки Майлз Уильямс, Джордж Крайсостому, Николаос Алетрас | Бумага | |
| Остерегайтесь данных калибровки для обрезки больших языковых моделей Yixin Ji, Yang Xiang, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, Min Zhang | Бумага | |
Alphapruning: Использование теории самостоятельной регуляризации для улучшения обрезки слоя больших языковых моделей Хайкан Лу, Йефан Чжоу, Шивей Лю, Чжангьян Ван, Майкл В. Махони, Яоцинг Ян | GitHub Бумага | |
| За пределами линейных приближений: новый подход обрезки для внимания Yingyu Liang, Jiangxuan Long, Zhenmei Shi, Zhao Song, Yufa Zhou | Бумага | |
Disp-LLM: независимая от размера структурная обрезка для моделей крупных языков Shangqian Gao, Chi-Heng Lin, Ting Hua, Tang Zheng, Yilin Shen, Hongxia Jin, Yen-Chang HSU | Бумага | |
Дистилляция для самостоятельной дистилляции для восстановления качества в обрезанных крупных языковых моделях Виттурсан Тангараса, Ганеш Венкатеш, Ниш Синнадурай, Шон лжи | Бумага | |
| LLM-Rank: теоретический подход графика к обрезке больших языковых моделей Дэвид Хоффманн, Кайлаш Будхатоки, Матхей Клейндесснер | Бумага | |
Является ли наборы данных C4 оптимальным для обрезки? Исследование данных калибровки для обрезки LLM Абхинав Бандари, Лу Инь, Ченг-Ю Сих, Аджай Кумар Джайсвал, Тянлонг Чен, Ли Шен, Ранджай Кришна, Шивей Лю | GitHub Бумага | |
| Смягчение смещения копий в обучении в контексте через обрезку нейронов Амин Али, Лиор Вольф, Иван Титов |  | Бумага |
SQFT: низкая адаптация модели в моделях Sparse Foundation с низким уровнем определения Хуан Пабло Муньос, Джинджи Юань, Нилеш Джайн | 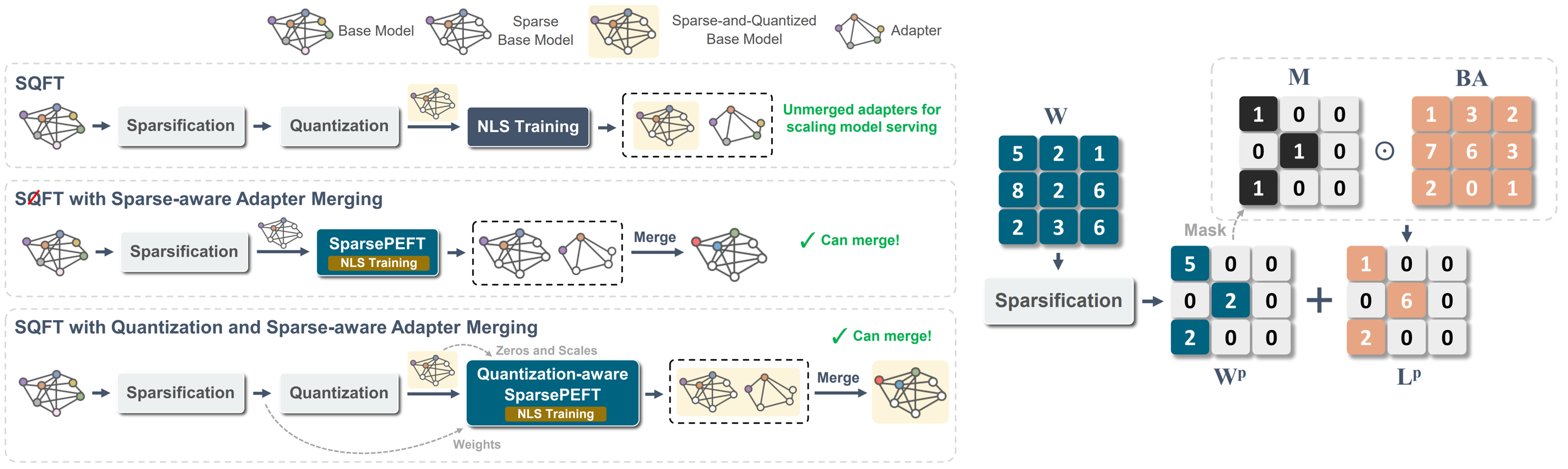 | GitHub Бумага |
Maskllm: Learnable полуструктурированная разреженность для больших языковых моделей Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, Xinchao Wang | 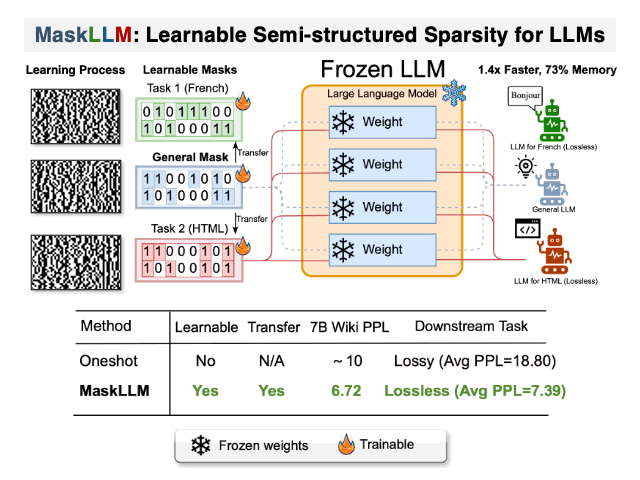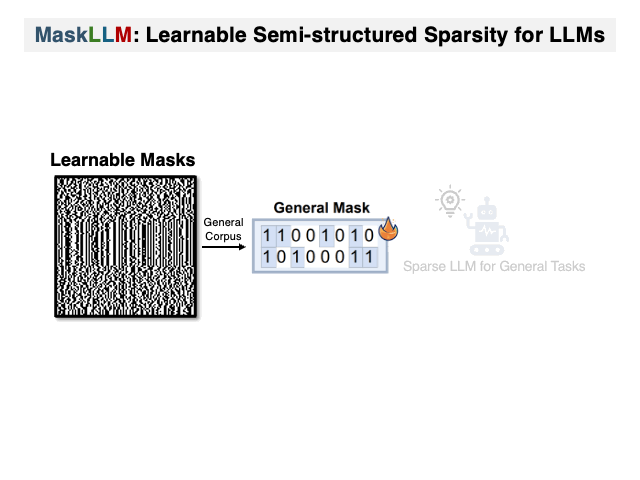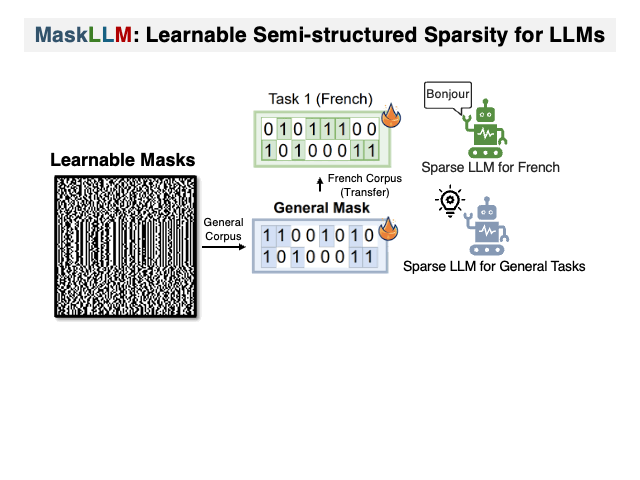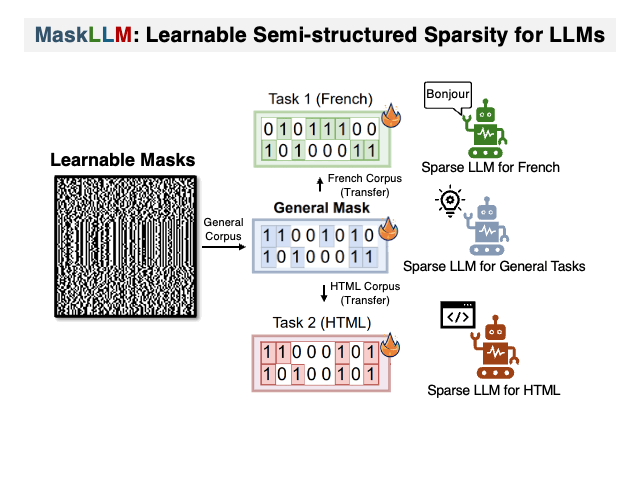 | GitHub Бумага |
Поиск эффективных крупных языковых моделей Сюань Шен, Пу Чжао, Ифан Гонг, Чжэнлун Конг, Чжэн Чжан, Юшу Ву, Мин Лин, Чао Ву, Сюэ Лин, Янчхи Ван | Бумага | |
CFSP: эффективная структурированная структура обрезки для LLMS с информацией об активации с грубым Yuxin Wang, Minghua MA, Zekun Wang, Jingchang Chen, Huiming Fan, Liping Shan, Qing Yang, Dongliang Xu, Ming Liu, Bing Qin | GitHub Бумага | |
| Овес: обрезка с учетом выбросов через разреженное и низкое разложение ранга Стивен Чжан, Вардан Папьян | Бумага | |
| KVPruner: Структурная обрезка для более быстрых и экономичных для памяти моделей крупных языков Бо Л.В., Куан Чжоу, Сюананг Дин, Ян Ван, Земин М.А. | Бумага | |
| Оценка влияния методов сжатия на специфическую задачу производительности крупных языковых моделей Бишваш Ханал, Джеффри М. Капоне | Бумага | |
| STUN: Структурированная и не снятая обрезка для масштабируемой обрезки MOE Jaeseong Lee, Seung-Won Hwang, Aurick Qiao, Daniel F Campos, Zhewei Yao, Yuxiong He | Бумага | |
PAT: настройка обрезки для больших языковых моделей Yijiang Liu, Huanrui Yang, Youxin Chen, Rongyu Zhang, Miao Wang, Yuan Du, Li du |  | GitHub Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
| Растилляция знаний крупных языковых моделей Yuxian Gu, Li Dong, Furu Wei, Minlie Huang |  | GitHub Бумага |
| Улучшение возможностей математических рассуждений малых языковых моделей посредством дистилляции, управляемой обратной связью Скюню Чжу, Цзянь Ли, МА, Вейпинг Ван | Бумага | |
Генеративный контекст дистилляция Хэбин Шин, Лей Джи, Йенун Гонг, Сунгдонг Ким, Юнби Чой, Минджун Сео |  | GitHub Бумага |
| Переключение: обучение с учителем для знаний о перегородке крупных языковых моделей Jahyun Koo, Yerin Hwang, Yongil Kim, Taegwan Kang, Hyunkyung Bae, Kyomin Jung |  | Бумага |
Помимо авторегрессии: быстро Джастин Дешенау, Каглар Гулсер | GitHub Бумага | |
| Предварительная дистилляция для моделей крупных языков: исследование пространства дизайна Хао Пэн, Синь Л.В., Юши Бай, Зиджун Яо, Цзяджи Чжан, Лей Хоу, Хуанзи Ли | Бумага | |
Miniplm: дистилляция знаний для моделей до тренировок. Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, Minlie Huang | 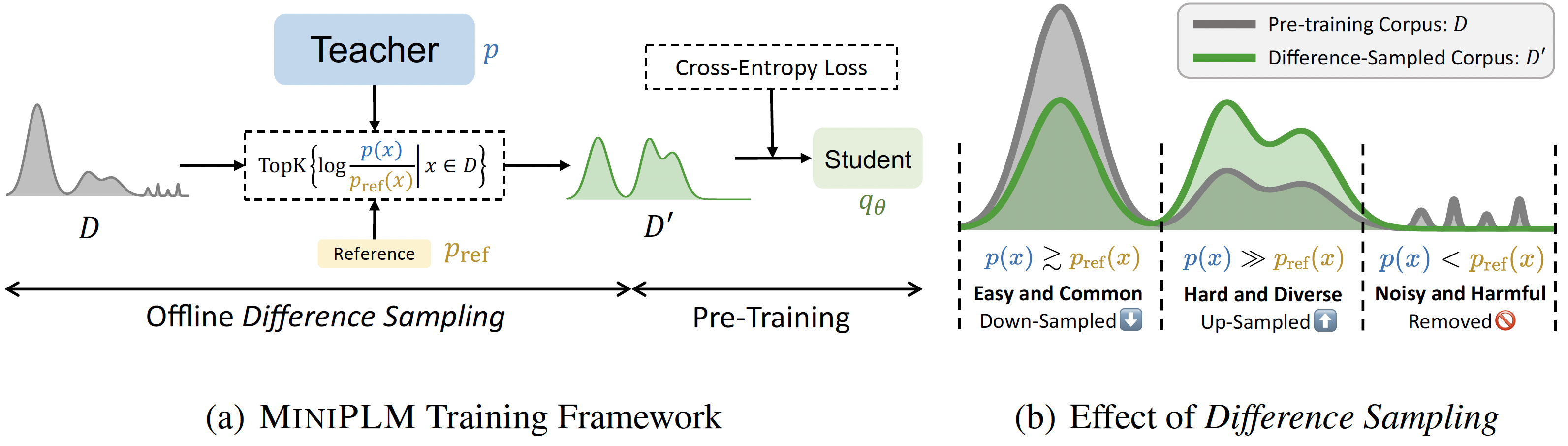 | GitHub Бумага |
| Спекулятивная дистилляция знаний: преодоление пробела учителя-студента посредством чередованной выборки Венда Сюй, Рудзюн Хан, Зифенг Ванг, Лонг Т. Ле, Дхрув Мекка, Лей Ли, Уильям Ян Ван, Ришабх Агарвал, Чен-Ю Ли, Томас Пфистер | Бумага | |
| Эволюционная контрастная дистилляция для выравнивания языковой модели Джулиан Кац-Самуэльс, Чжэн Ли, Хёкун Юн, Приянка Нигам, И Сюй, валав Петрикерк, Бинг Инь, Тришул Чилимби | Бумага | |
| Babyllama-2: модели, посвященные ансамбле, постоянно превосходят учителей с ограниченными данными Жан-лап вкусовое, inar timiryasov | Бумага | |
| Echoatt: посещать, копировать, а затем приспособиться для более эффективных моделей больших языков Хоссейн Раджабзаде, Ареф Джафари, Аман Шарма, Бениамин Джами, Хайок Джу Квон, Али Годси, Бокс Чен, Мехди Резагхолизадех | Бумага | |
Skintern: интернализующие символические знания для перегонки лучших возможностей для котенок в модели мелких языков Huanxuan Liao, Shizhu He, Yupu Hao, Xiang Li, Yuanzhe Zhang, Kang Liu, Jun Zhao | GitHub Бумага | |
LLMR: дистилляция знаний с большой языковой моделью вознаграждением Dongheng Li, Yongchang Hao, Lili Moun |  | GitHub Бумага |
| Изучение и усиление передачи распространения в дистилляции знаний для моделей авторегрессии языка Jun Rao, Xuebo Liu, Zepeng Lin, Liang Ding, Jing Li, Dacheng Tao | Бумага | |
| Эффективная дистилляция знаний: расширение возможностей малых языковых моделей с помощью модели учителя Мохамад Баллаут, Ульф Крюммак, Гюнтер Хейдеманн, Кай-Уве Кюнбергер | Бумага | |
Мамба в ламе: дистилляция и ускорение гибридных моделей Junxiong Wang, Daniele Paliotta, Avner May, Александр М. Раш, Tri Dao | GitHub Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
GPTQ: точное квантование после тренировки для генеративных предварительно обученных трансформаторов Элиас Франтар, Салех Ашкбус, Торстен Хофлер, Дэн Алистарх | 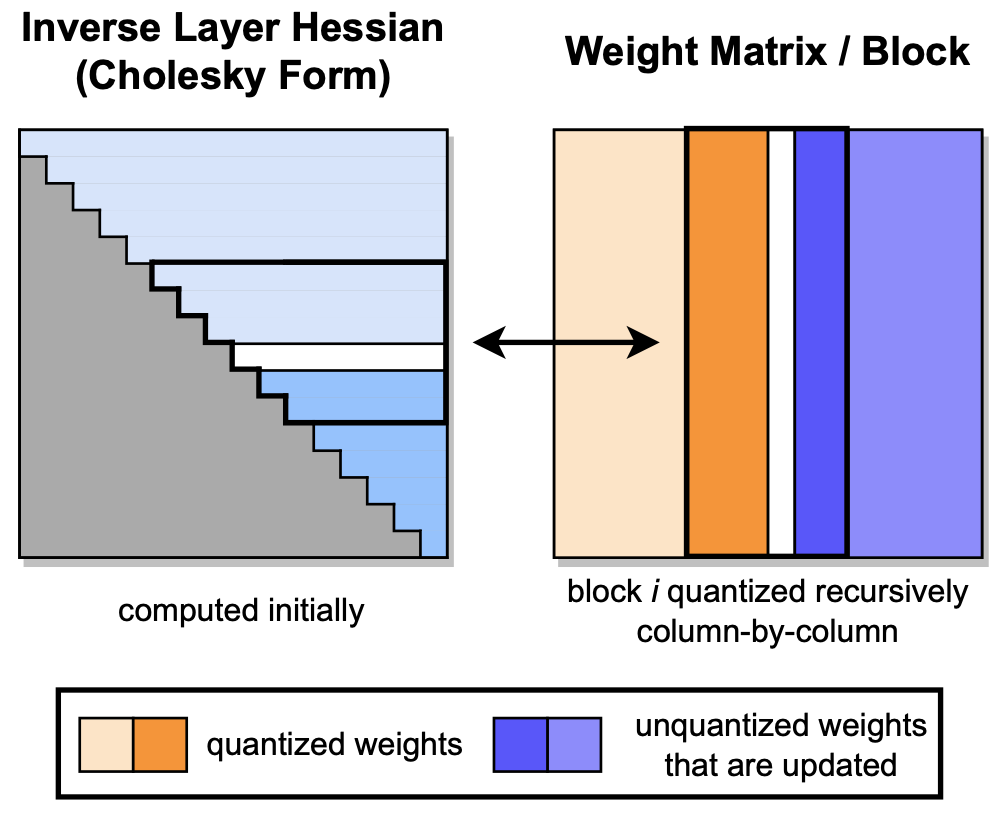 | GitHub Бумага |
Сквозь: точное и эффективное квантование после тренировки для крупных языковых моделей Гуанксуань Сяо, Джи Лин, Микаэль Сезнек, Хао Ву, Жюльен Демут, Сонг Хан | 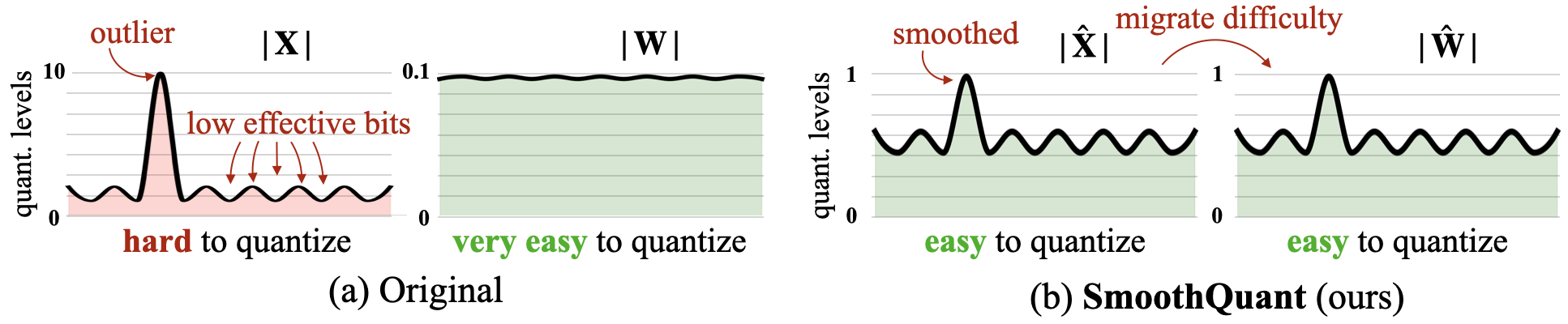 | GitHub Бумага |
AWQ: квантование веса с активацией для сжатия и ускорения LLM Джи Лин, Джиамин Тан, Хаотиан Тан, Шан Ян, Синью Данг, Сонг Хан | 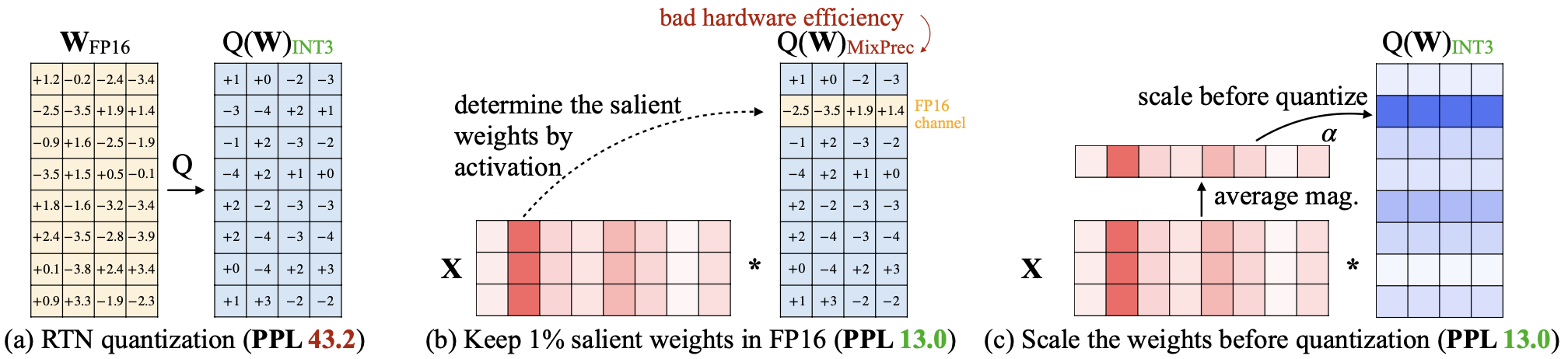 | GitHub Бумага |
Omniquant: вседидиально калиброванное квантование для больших языковых моделей Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo | 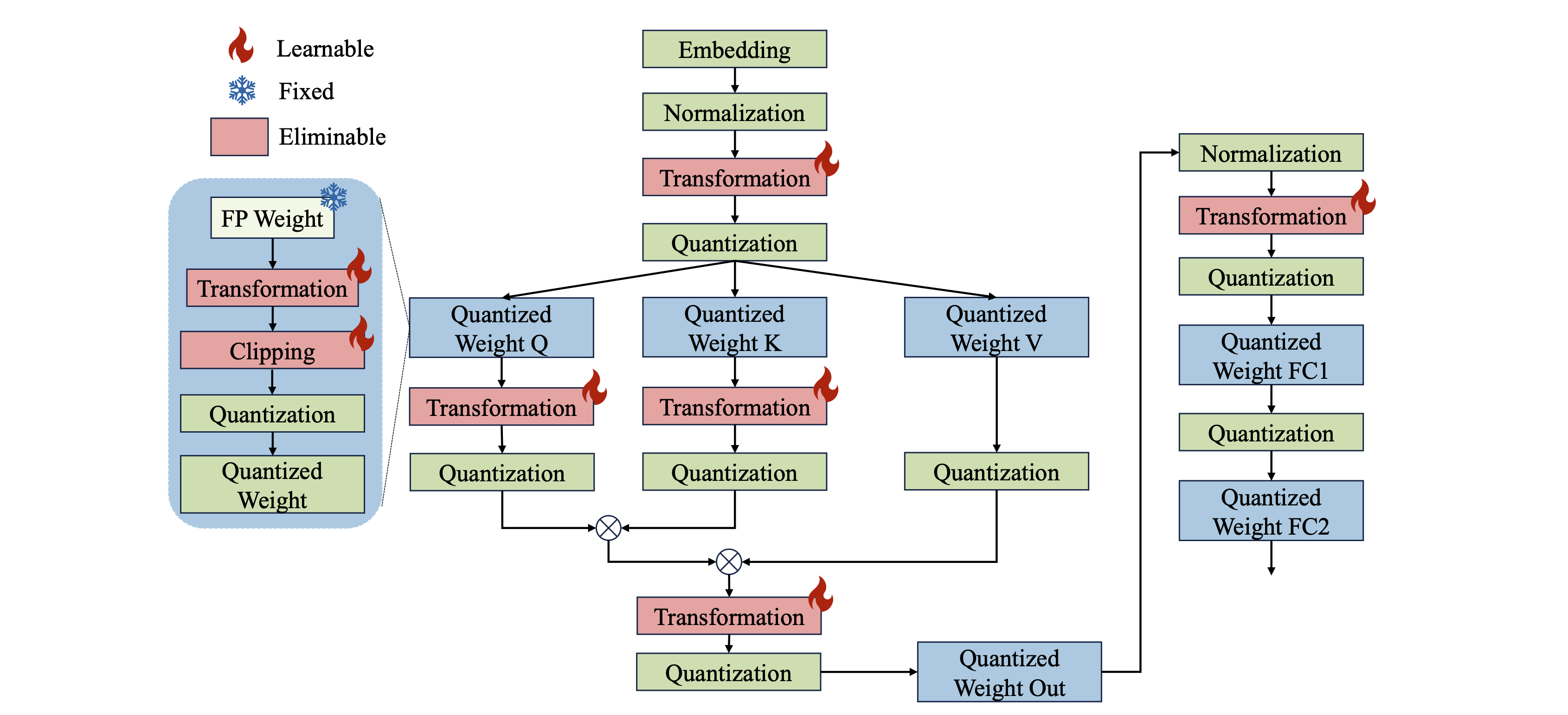 | GitHub Бумага |
| Skim: Any-Bit квантование, раздвигающие пределы квантования после тренировки Раншенг Бай, Цянь Лю, Бо Лю | Бумага | |
| CPTQUANT-новые методы квантования пост-тренировок Амиташ Нанда, Шри Бхаргави Балиджа, Дебашис Саху | Бумага | |
ANDA: разблокировка эффективного вывода LLM с помощью формата данных с группировкой переменной длины Chao Fang, Man Shi, Robin Geens, Arne Symons, Zhongfeng Wang, Marian Verhelst | Бумага | |
| Mixpe: квантование и оборудование для эффективного вывода LLM Ю Чжан, Мингзи Ванг, Ланхенг Зу, Вулонг Лю, Ху-Линг Жен, Мингсуань Юань, Бей Ю. | Бумага | |
Bitmod: битовая смеси с датипа LLM Ускорение Юзонг Чен, Ахмед Ф. Абуэлхамайед, Ксилай Дай, Ян Ванг, Марта Андроник, Джордж А. Константинид, Мохамед С. Абдельфатта. | GitHub Бумага | |
| AMXFP4: укрощение выбросов активации с асимметричной микромасляной плавающей точкой для 4-битного вывода LLM Janghwan Lee, Jiwoong Park, Jinseok Kim, Yongjik Kim, Jungju Oh, Jinwook Oh, Jungwook Choi | 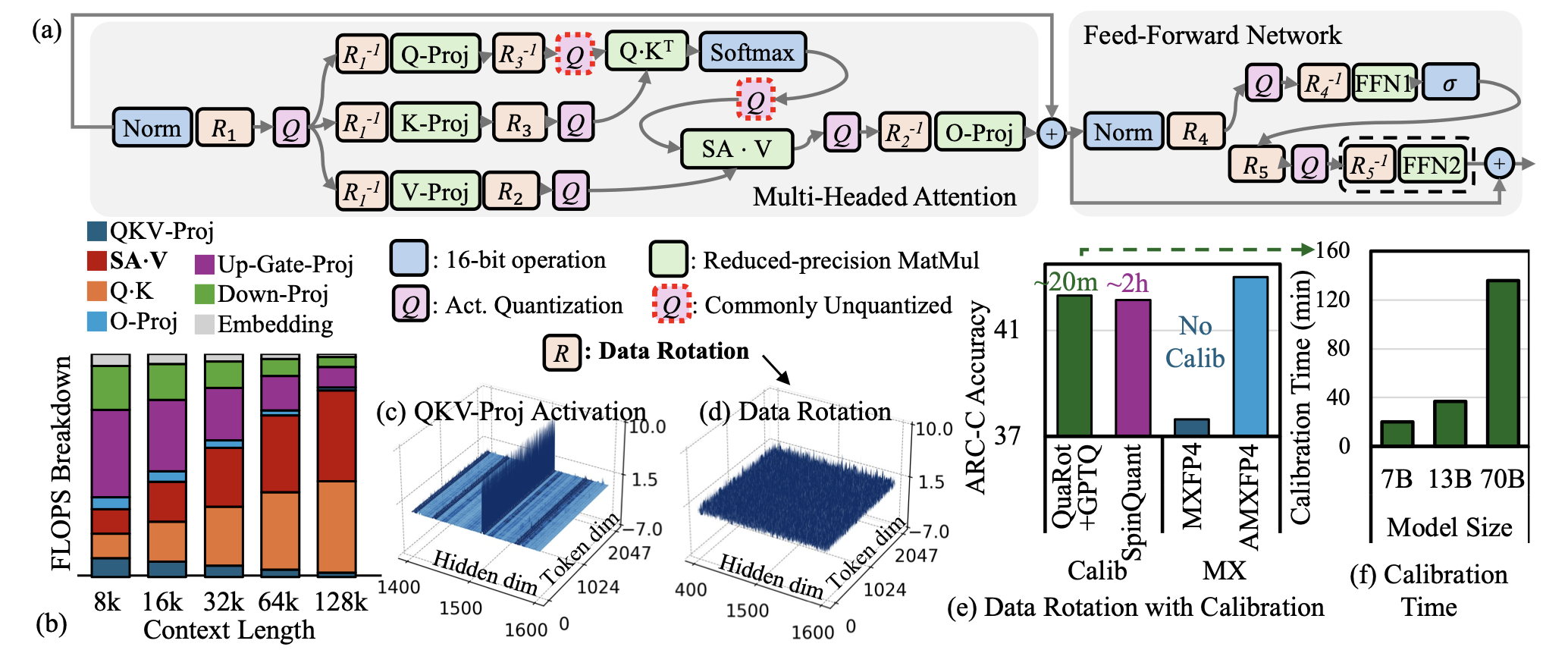 | Бумага |
| Би-мамба: к точным 1-битным моделям пространства состояний Shengkun Tang, Liqun MA, Haonan Li, Mingjie Sun, Zhiqiang Shen | Бумага | |
| «Дай мне BF16 или дайте мне смерть»? Компромиссные компромиссы в области точности в квантовании LLM Эльдар Куртик, Александр Маркес, Шубхра Пандит, Марк Курц, Дэн Алистарх | Бумага | |
| Gwq: квантование веса с градиентом для больших языковых моделей Yihua Shao, Siyu Liang, Xiaolin Lin, Zijian Ling, Zixian Zhu et al. | Бумага | |
| Комплексное исследование методов квантования для крупных языковых моделей Цинонг Ланг, Чжехао Го, Шую Хуанг | Бумага | |
| Bitnet A4.8: 4-битная активация для 1-битных LLMS Hongyu Wang, Shuming MA, Furu Wei | Бумага | |
Tesseraq: Ultra Low-Bit LLM квантование после тренировки с реконструкцией блока Юханг Ли, Приядаршини Панда | 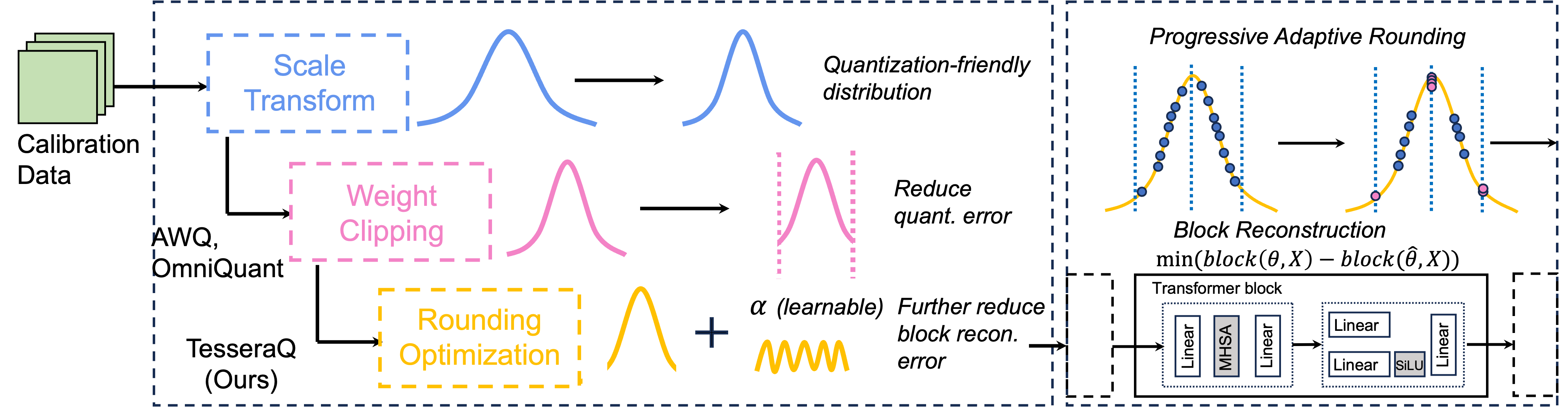 | GitHub Бумага |
Bitstack: мелкозернистый контроль размера для сжатых больших языковых моделей в средах переменной памяти Синхао Ванг, Пенгью Ван, Бо Ван, Донг Чжан, Юнхуа Чжоу, Скюэнг Цю | 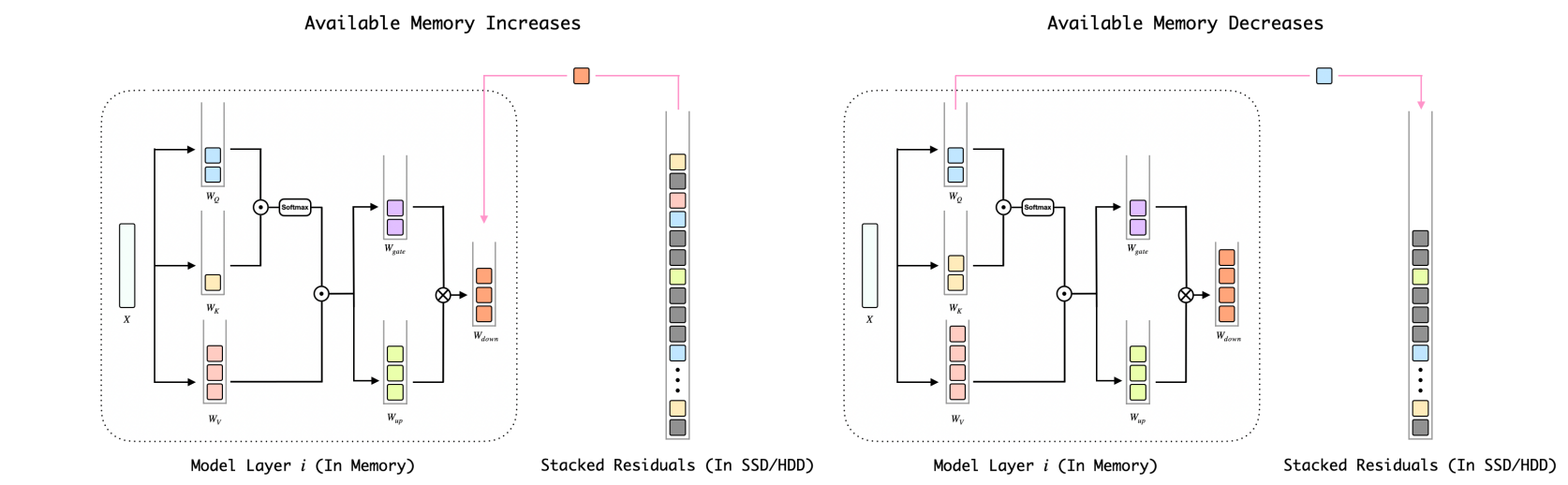 | GitHub Бумага |
| Влияние стратегий ускорения вывода на смещение LLMS Элизабет Кирстен, Иван Хабернал, Ведант Нанда, Мухаммед Билал Зафар | Бумага | |
| Понимание сложности низкоквалифицированного пост-тренировочного квантования крупных языковых моделей Zifei Xu, Sayeh Sharify, Wanzin Yazar, Tristan Webb, Синь Ван | Бумага | |
1-битный AI Infra: Часть 1.1, быстрый и без потерь Bitnet B1.58. Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming MA, Hongyu Wang, Yan Xia, Furu Wei | GitHub Бумага | |
| Quailora: инициализация с квантованием для Lora Нил Лоутон, Айшвария Падмакумар, Джудит Гасперс, Джек Фицджеральд, Аноп Кумар, Грег Вер Стиг, Арам Галстиан | Бумага | |
| Оценка квантованных крупных языковых моделей для генерации кода на языковых показателях с низким разрешением Энхлолд Ньямсурен | Бумага | |
Squeezellm: квантование с плотным и спадом Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer | 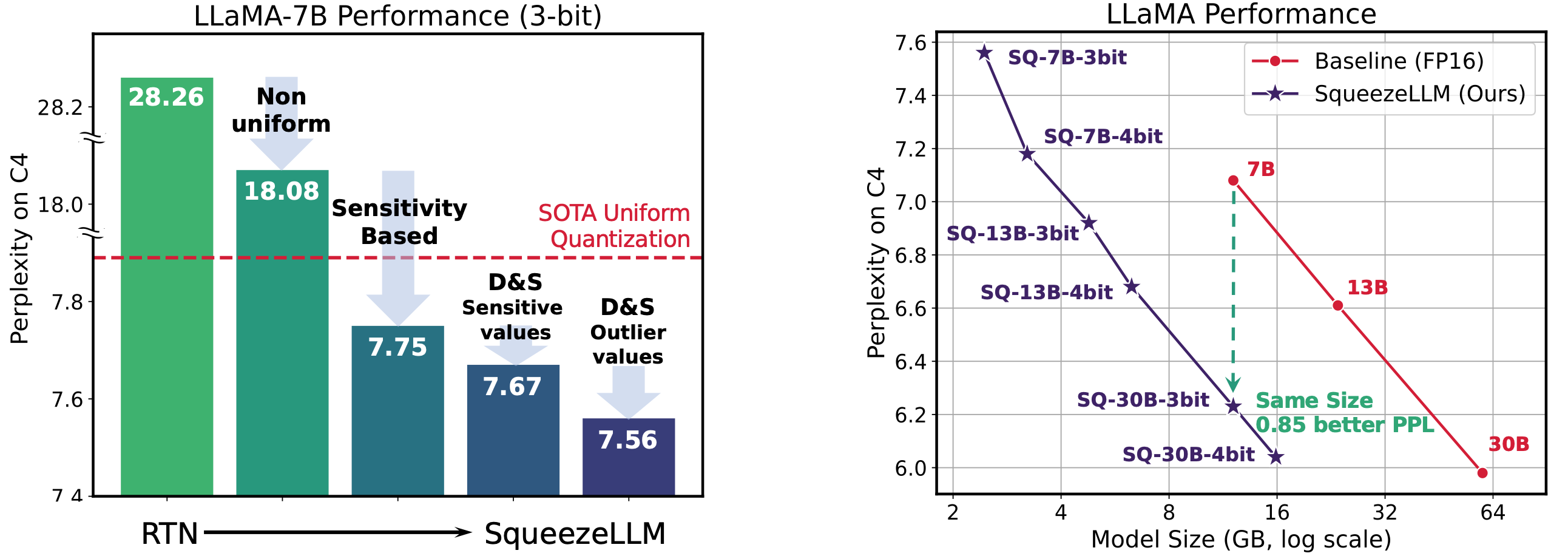 | GitHub Бумага |
| Квантование вектора пирамидного вектора для LLMS Tycho fa van der Ouderaa, Maximilian L. Croci, Agrin Hilmkil, James Hensman | Бумага | |
| SEADLM: сжатие весов LLM в семена псевдолупиточных генераторов Расул Шафипур, Дэвид Харрисон, Максвелл Хортон, Джеффри Маркер, Хоуман Бедэйт, Сачин Мехта, Мохаммад Растегари, Махьяр Наджиби, Саман Надерипаризи | Бумага | |
Плоский: плоскостность имеет значение для квантования LLM Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, Jun Yao | GitHub Бумага | |
Слим: одноразовый квантовый редкий плюс приблизительный приближение LLMS Мохаммед Мозаффари, Марьям Мехри Дехнави | GitHub Бумага | |
| Законы масштабирования для пост-тренировочных квантованных больших языковых моделей Zifei Сюй, Александр Лан, Ванзин Язар, Тристан Уэбб, Сэйе Шарифи, Синь Ван | Бумага | |
| Непрерывные приближения для улучшения обучения квантованию, осведомленных о LLMS Он Ли, Цзяньхан Хонг, Юаньхуо Ву, Снегал Адбол, Зонглин Ли | Бумага | |
DAQ: квантование только по пост-тренировке для LLMS. Yingsong Luo, Ling Chen | GitHub Бумага | |
Quamba: рецепт квантования после тренировки для селективных космических моделей состояния Хунг-юэ Чиан, Чи-Чих Чанг, Наталья Фрумкин, Кай-Чиан Ву, Диана Маркулеску | GitHub Бумага | |
| AsyMKV: включение 1-битного квантования кэша KV с помощью слоя асимметричных конфигураций квантования Цянь Тао, Вениуан Ю, Цзинрен Чжоу | Бумага | |
| Квантование в промежуточном режиме на канале для больших языковых моделей Зихан Чен, Байк Се, Джундонг Ли, Конг Шен | Бумага | |
| Прогрессивная декодирование смешанной режиссера для эффективного вывода LLM Хао Марк Чен, Фувен Тан, Александрос Коурис, Ройсон Ли, Фан Хонсин, Стилиайан И. Веньерис | Бумага | |
Exaq: квантование знакомых с показателями для ускорения LLMS Моран Школьник, Максим Фишман, Брайан Чмил, Хилла Бен-Яаков, Рон Баннер, Кфир Йегуда Леви |  | GitHub Бумага |
Префикс -кванк: статическое квантование побеждает динамическую через префиксированные выбросы в LLMS Mengzhao Chen, Yi Liu, Jiahao Wang, Yi Bin, Wenqi Shao, Ping luo | GitHub Бумага | |
Чрезвычайное сжатие моделей крупных языков с помощью аддитивного квантования Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh | 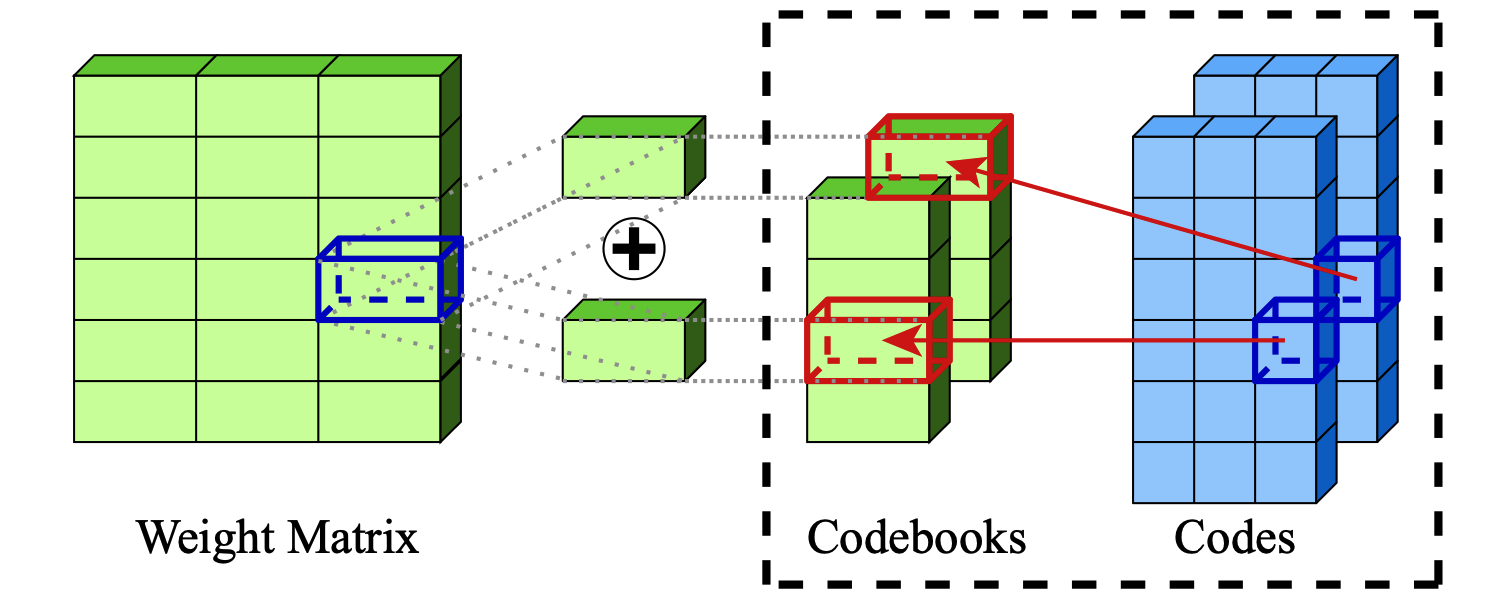 | GitHub Бумага |
| Масштабирование законов для смешанного квантования в моделях крупных языков Зейу Цао, Ченг Чжан, Педро Гименес, Цзяньцяо Лу, Цзяньи Ченг, Ирен Чжао | 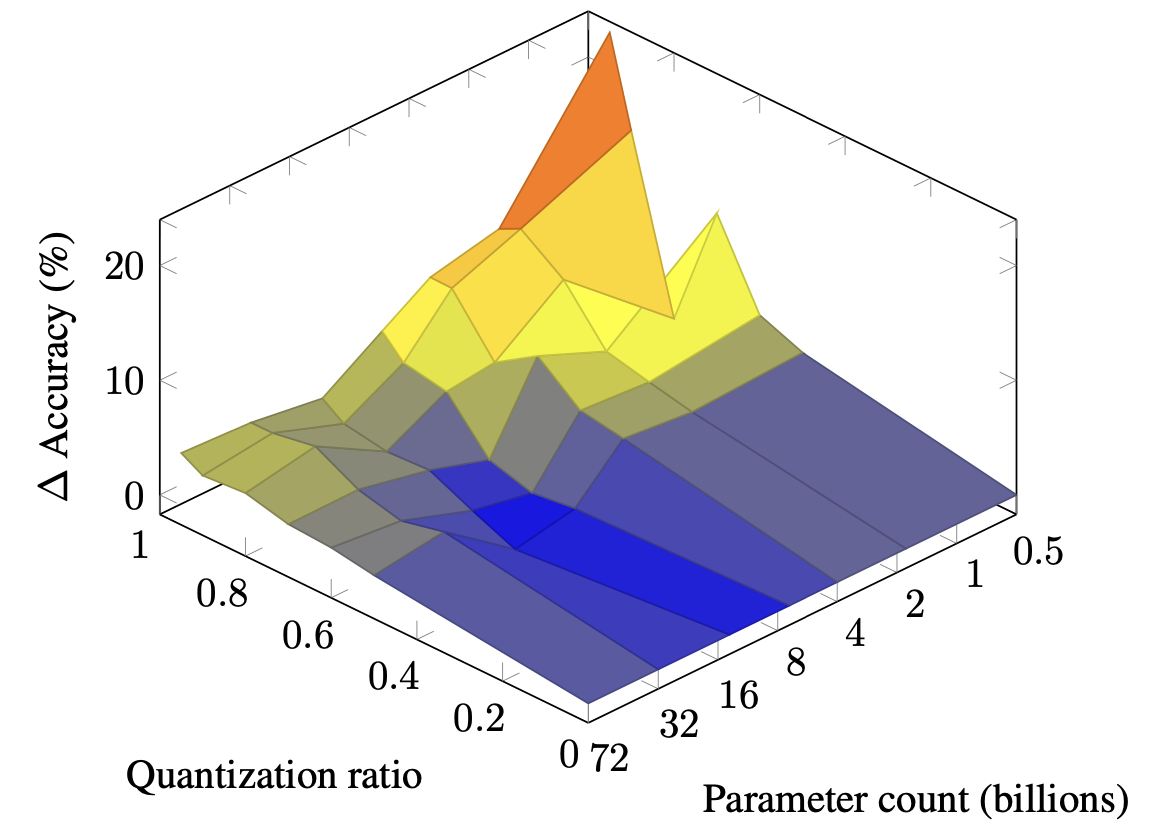 | Бумага |
| Palmbench: комплексный эталон сжатых крупных языковых моделей на мобильных платформах Yilong Li, Jingyu Liu, Hao Zhang, M Badri Narayanan, Utkarsh Sharma, Shuai Zhang, Pan Hu, Yijing Zeng, Jayaram Raghuram, Suman Banerjee | 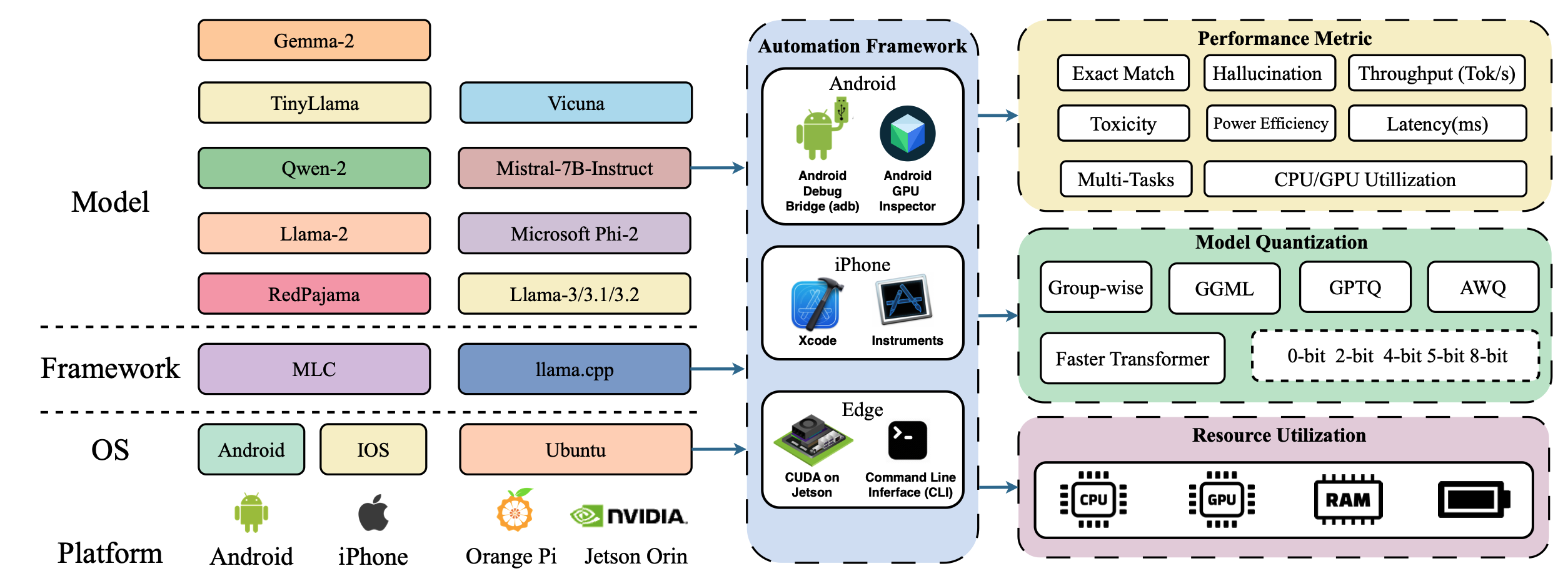 | Бумага |
| Crossquant: метод квантования после тренировки с меньшим ядром квантования для точного сжатия модели большой языка Вениуан Лю, Синдиан М.А., Пенг Чжан, Ян Ван | Бумага | |
| SAGEATTENTUTION: точное 8-битное внимание для ускорения вывода подключения и игры Jintao Zhang, Jia Wei, Pengle Zhang, Jun Zhu, Jianfei Chen | Бумага | |
| Дополнение-это все, что вам нужно для энергоэффективных языковых моделей Хонгин Луо, Вэй Сан | Бумага | |
VPTQ: экстремальный векторный векторный векторный векторный квант Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, Mao Yang | 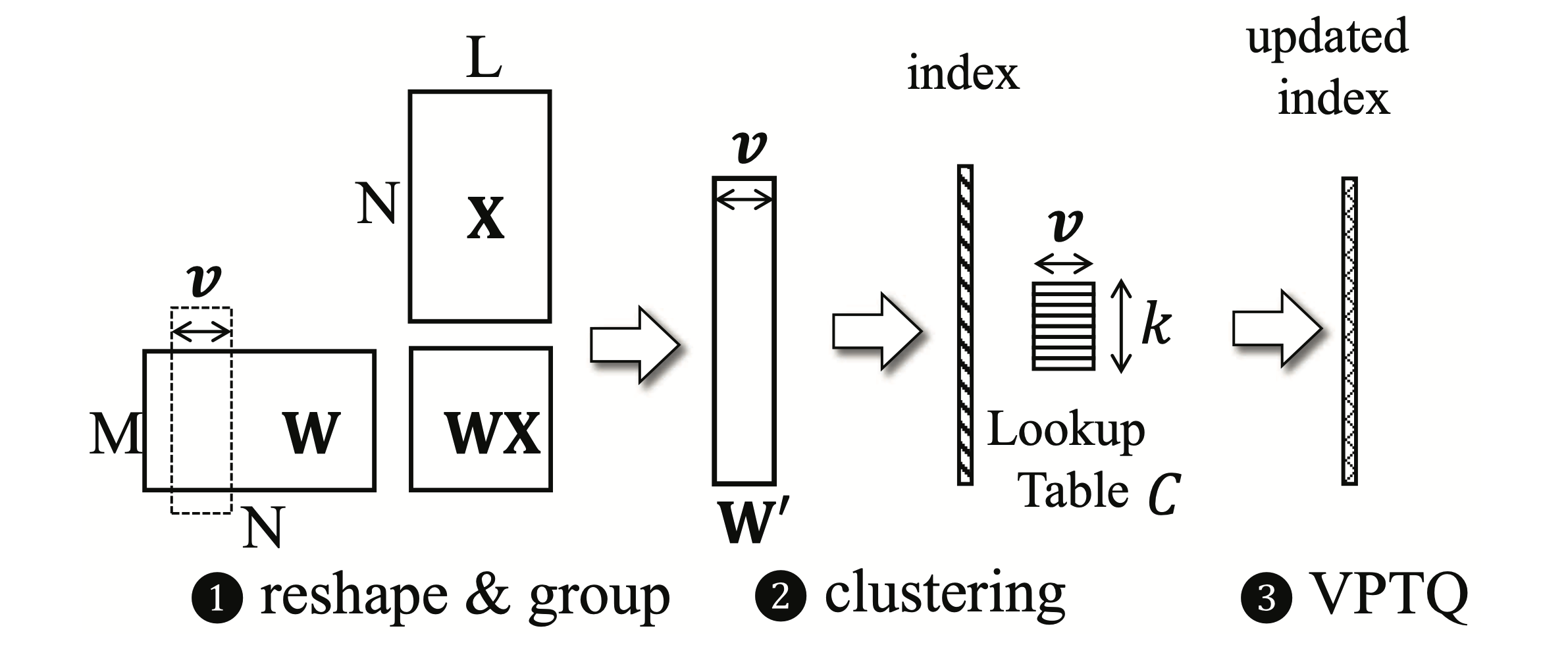 | GitHub Бумага |
Int-flashattunction: включение флэш-внимания к квантованию Int8 Shimao Chen, Zirui Liu, Zhiying Wu, Ce Zheng, Peizhuang Cong, Zihan Jiang, Yuhan Wu, Lei Su, Tong Yang | GitHub Бумага | |
| Аккумулятор с квантованием после тренировки Ян Колберт, Фабиан Гроб, Джузеппе Франко, Джинджи Чжан, Райан Сааб | Бумага | |
Duquant: распределение выбросов через двойное преобразование делает более сильные квантовые LLMS Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, Ying Wei | 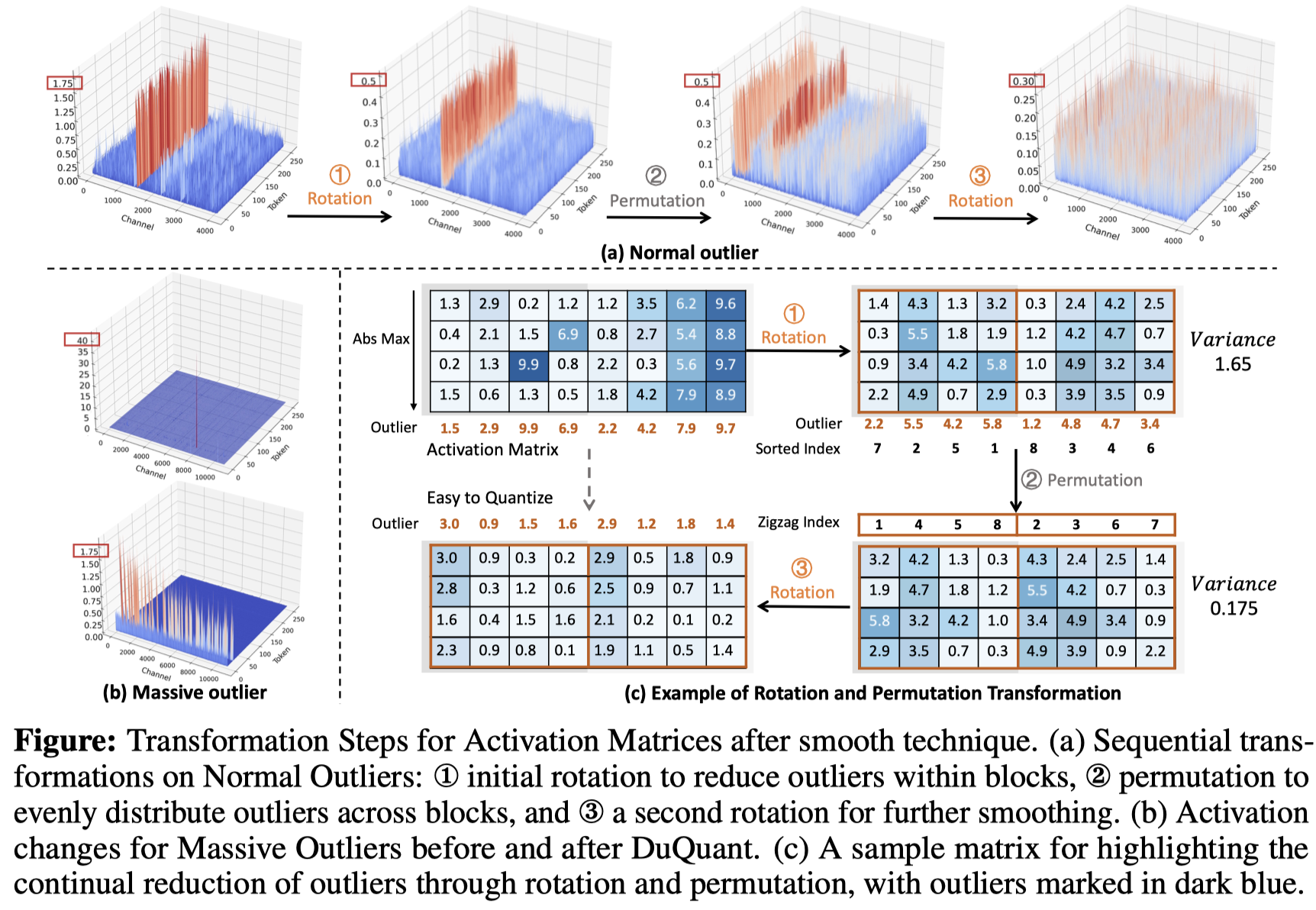 | GitHub Бумага |
| Комплексная оценка квантованных моделей с большими языками, настроенными на инструкции: экспериментальный анализ до 405B Джемин Ли, парк Сихион, Джинсе Квон, Джихун О, Юнгин Квон | Бумага | |
| Уникальность Llama3-70B с квантованием для каждого канала: эмпирическое исследование Мингхай Цин | Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
Deja Vu: контекстуальная редкость для эффективных LLM во время вывода Зиханг Лю, Юэ Ван, Три Дао, Тиани Чжоу, Бинханг Юань, Чжао Сонг, Аншумали Шривастава, Се Чжан, Юандонг Тянь, Кристофер Р., Бейди Чен | 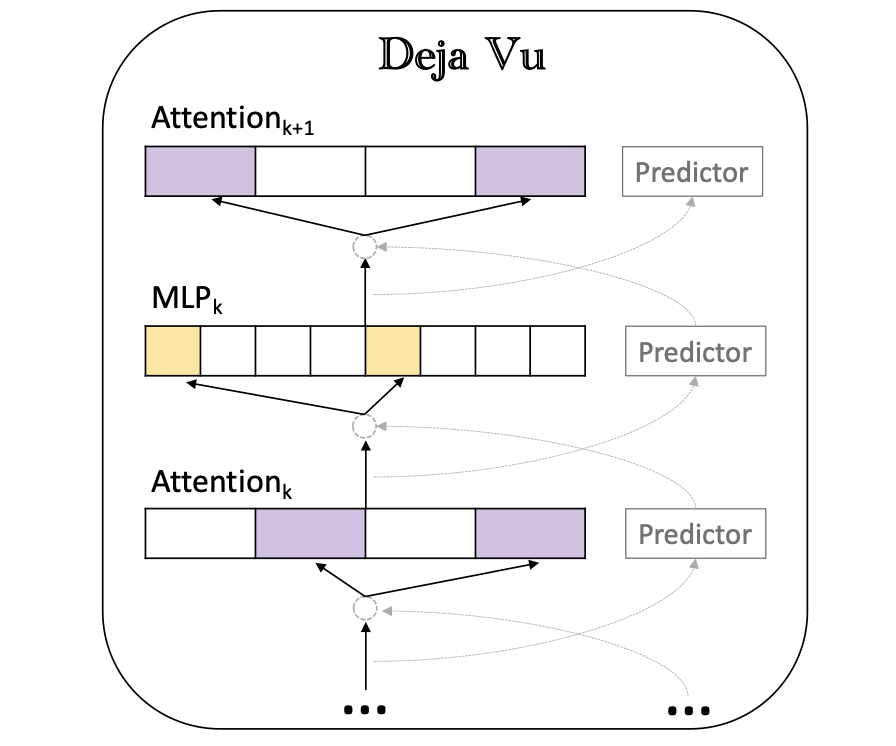 | GitHub Бумага |
Specinfer: ускорение генеративного LLM служащего с спекулятивным выводом и проверкой дерева токенов Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia | 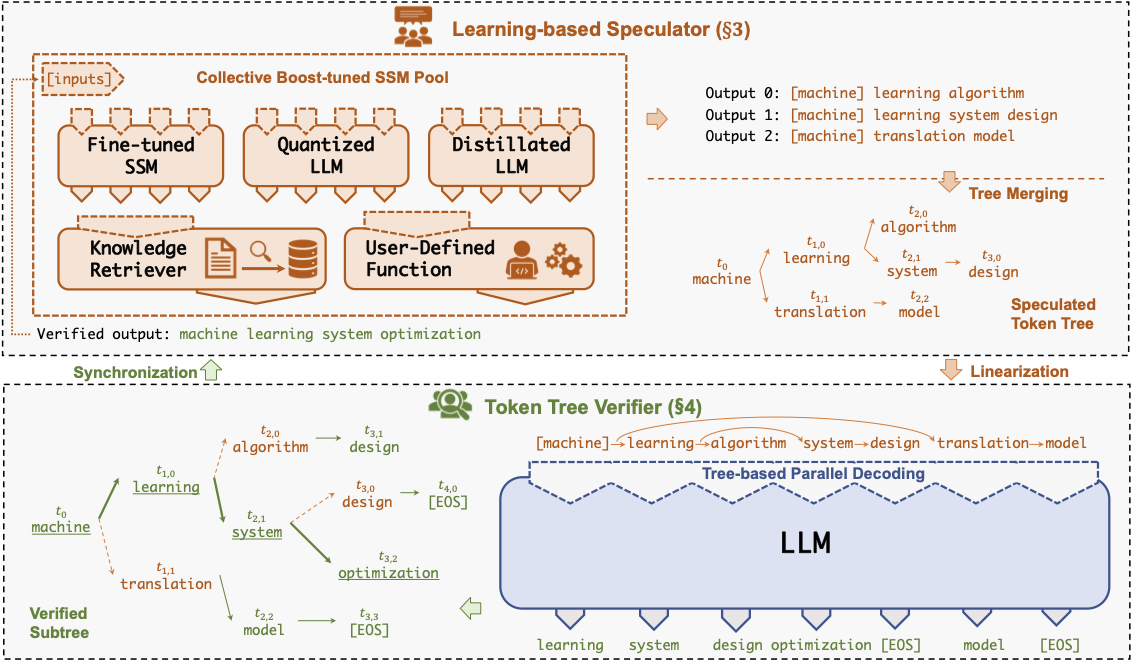 | GitHub бумага |
Эффективные потоковые языковые модели с утоплениями внимания Гуанксуань Сяо, Юандонг Тянь, Бейди Чен, Сонг Хан, Майк Льюис | 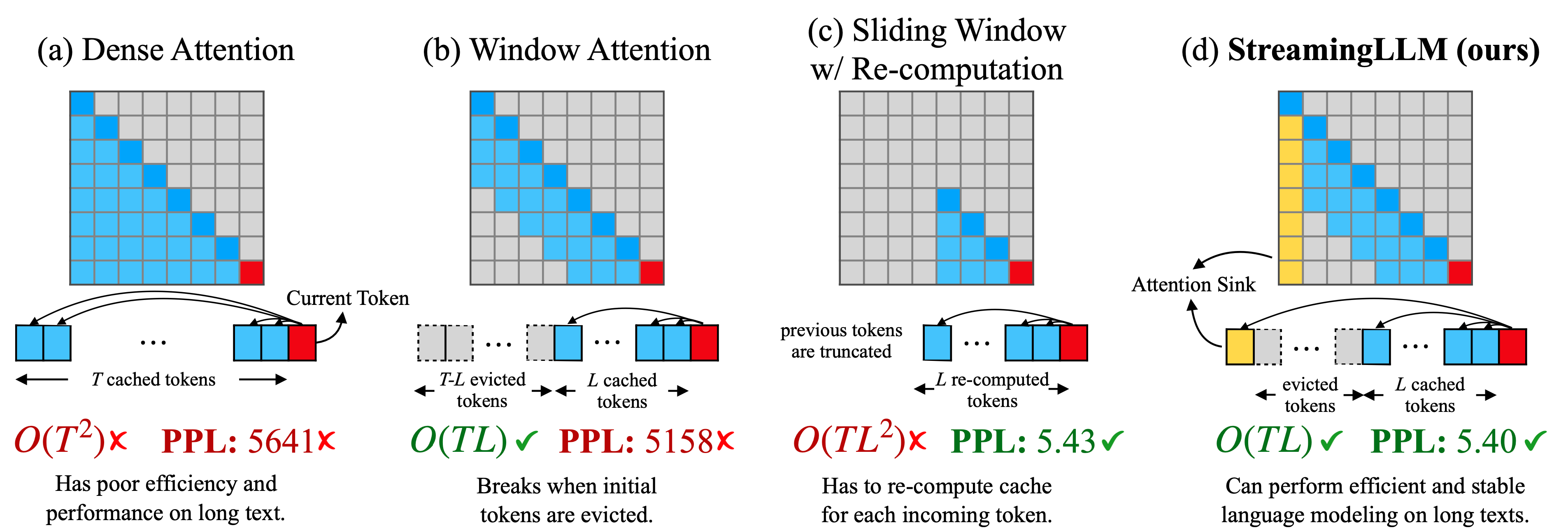 | GitHub Бумага |
Орел: без потерь ускорение декодирования LLM путем экстраполяции функции Юхуи Ли, Чао Чжан и Хонгьян Чжан | 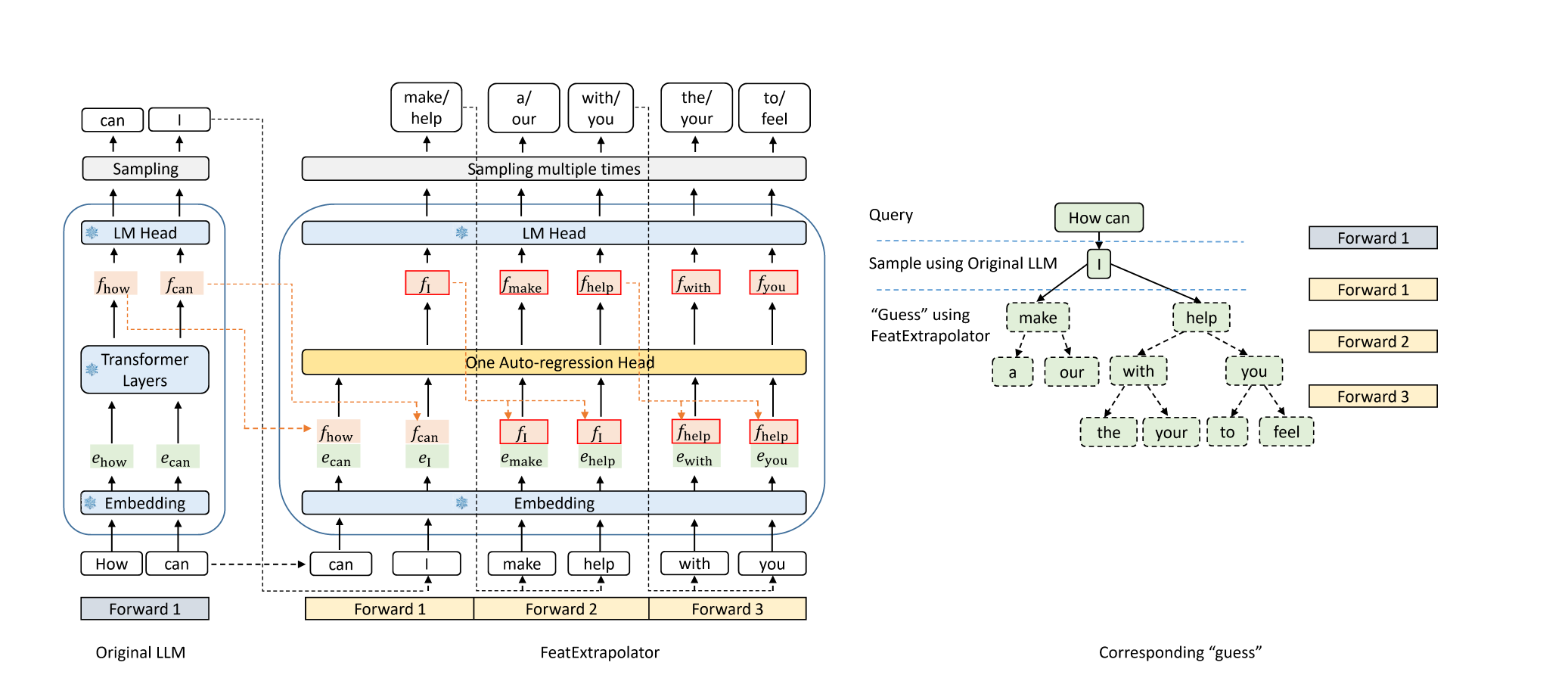 | GitHub Блог |
Medusa: Простая структура ускорения вывода LLM с несколькими декодирующими головками Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, Tri Dao | GitHub Бумага | |
| Спекулятивное декодирование с помощью черновой модели на основе CTC для ускорения вывода LLM Zhuofan Wen, Shangtong Gui, Yang Feng | Бумага | |
| PLD+: Ускорение вывода LLM, используя артефакты модели языка Shwetha Somasundaram, Anirudh Phukan, Apoorv Saxena | Бумага | |
FASTDRAFT: как тренировать проект Офир Зафрир, Игорь Маргулис, Дорин Штиман, Гай Будух | Бумага | |
SMOA: улучшение многоагентных крупных языковых моделей с редкой смесей агентов Dawei Li, Zhen Tan, Peijia Qian, Yifan Li, Kumar Satvik Chaudhary, Lijie Hu, Jiayi Shen | 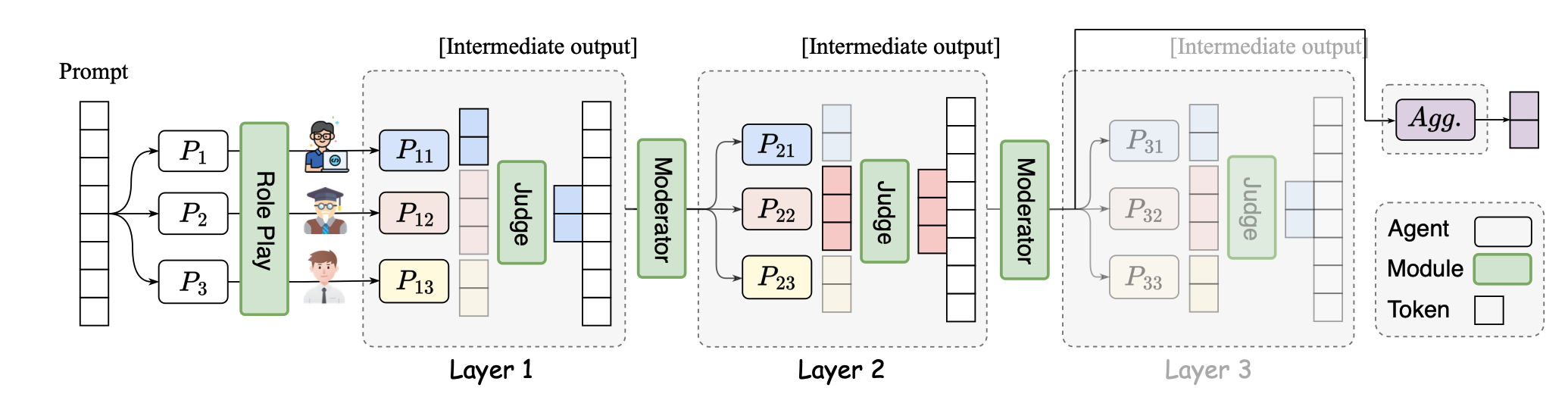 | GitHub Бумага |
| N-Grammys: ускорение авторегрессивного вывода с помощью пакетных спекуляций без обучения. Лоуренс Стюарт, Мэтью Трагер, Суджан Кумар Гонгундла, Стефано Соатто | Бумага | |
| Ускоренный вывод искусственного интеллекта с помощью методов динамического выполнения Хаим Барад, Джаша Ахтерберг, Тен Пей Чоу, Жан Ю | Бумага | |
| Суффикс-разделение: беззаботный подход к ускорению вывода с большой языком модели. Габриэле Олиаро, Чжихао Цзя, Даниэль Кампос, Аурик Цяо | Бумага | |
| Планирование динамического стратегии для эффективного ответа на вопрос с большими языковыми моделями Танмей Парех, Прадиот Пракаш, Александр Радович, Акшай Шехер, Денис Савенков | Бумага | |
MagicPig: выборка LSH для эффективной генерации LLM Чжуминг Чен, Ранаджой Садхухан, Зихао Йе, Ян Чжоу, Цзянью Чжан, Никлас Нолте, Юандонг Тянь, Маттийс Дуз, Леон Ботту, Чжихао Цзя, Бейди Чен | GitHub Бумага | |
| Более быстрые языковые модели с лучшим предсказанием с несколькими точками с использованием декомпозиции тензора Артем Башарин, Андрей Чертков, Иван Ослеклет |  | Бумага |
| Эффективный вывод для дополненных крупных языковых моделей Рана Шахут, Конг Лян, Шиджи Синь, Цяньру Лао, Юн Куи, Минлан Ю, Майкл Митценмахер | Бумага | |
Динамическая обрезка словаря в ранних EXIT LLMS Джорт Винсенти, Карим Абдель Садек, Джоан Велджа, Маттео Нулли, Метод Джазбек |  | GitHub Бумага |
COREINFER: Ускорение вывода с большой языком с помощью семантики, вдохновленной адаптивной разреженной активацией Qinsi Wang, Saeed Vahidian, Hancheng Ye, Jianyang Gu, Jianyi Zhang, Yiran Chen | GitHub Бумага | |
Duoattention: эффективный вывод LLM с длинным контекстом с помощью поиска и потоковых голов Гуанксуань Сяо, Джиамин Тан, Джингвей Зуо, Джунсиан Го, Шан Ян, Хаотиан Тан, Яо Фу, Сонг Хан | 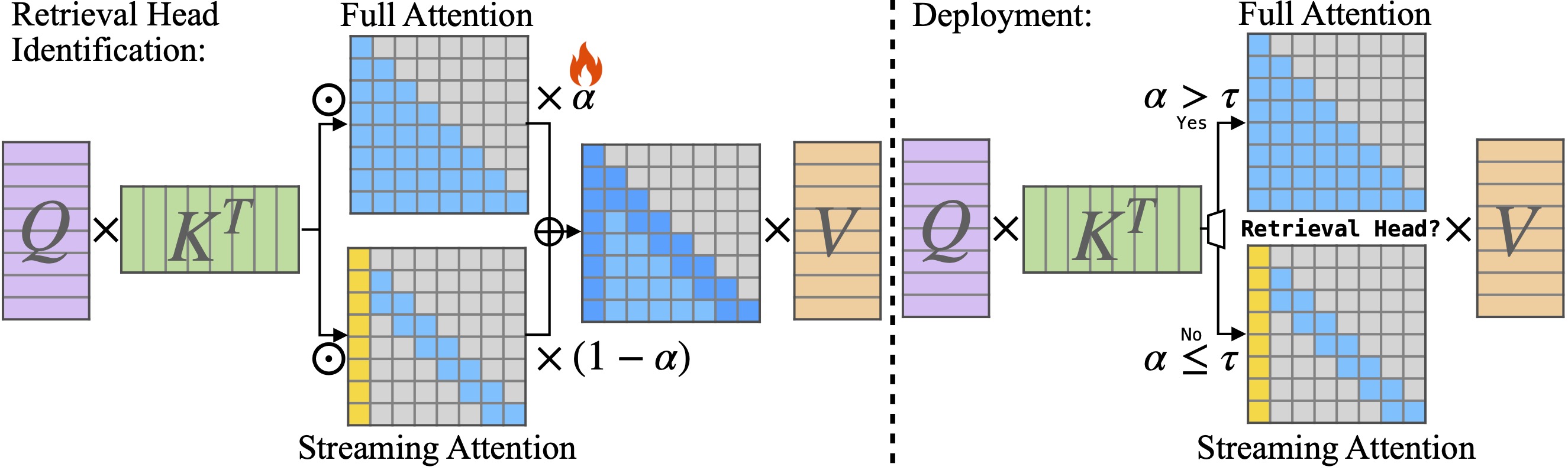 | GitHub Бумага |
| Одышка: более быстрое спекулятивное декодирование с динамической структурой дерева токенов Юнфан Сионг, Руою Чжан, Янзенг Ли, Тянхао Ву, Лей Зоу | Бумага | |
| Qspec: спекулятивное декодирование с помощью дополнительных схем квантования Juntao Zhao, Wenhao Lu, Sheng Wang, Lingpeng Kong, Chuan Wu | Бумага | |
| TidaldeCode: быстрый и точный декодирование LLM с постоянным Лиджи Ян, Чжихао Чжан, Чжуофу Чен, Зикун Ли, Чжихао Цзяя | Бумага | |
| Parallelspec: параллельный состав для эффективного спекулятивного декодирования Зилин Сяо, Хонминг Чжан, Тао Г.Е., Сиру Уян, Висенте Ордонез, Донг Ю. | Бумага | |
Swift: Самопрокулятивное декодирование на лету для ускорения вывода LLM Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, Wenjie Li |  | GitHub Бумага |
Turborage: Ускорение поколения из поиска с предварительно вычисленными кВевыми кешами для кусочка текста Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, Yaohua Tang | 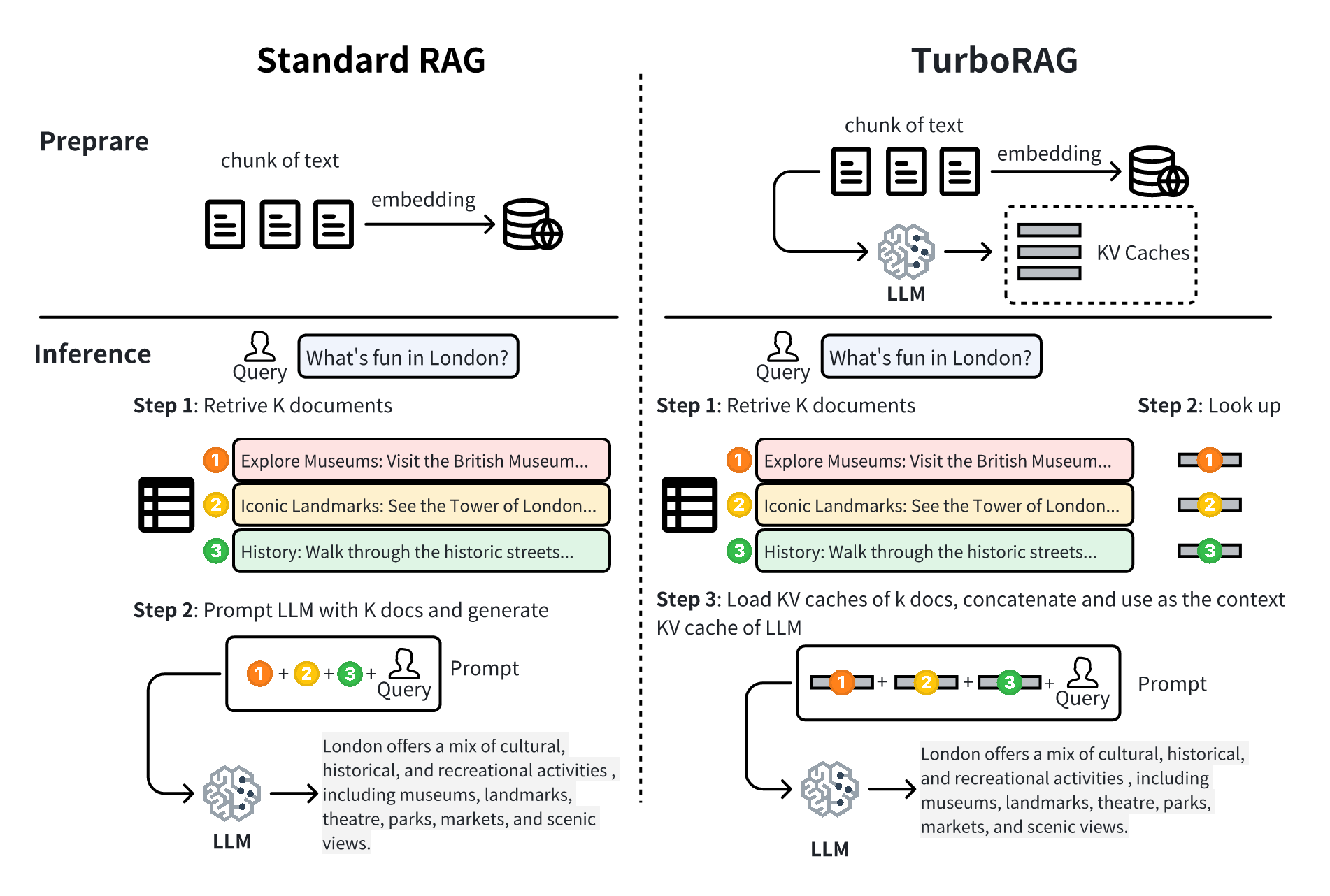 | GitHub Бумага |
| Немного проходит долгий путь: эффективная длинная контекстная тренировка и вывод с частичным контекстом Suyu GE, Xihui Lin, Yunan Zhang, Jiawei Han, Hao Peng | Бумага | |
| Мнемосин: стратегии параллелизации для эффективного обслуживания многомиллионной длины контекста. Эми Агравал, Джунда Чен, íñigo Goiri, Рамачандран Рамджи, Чаоджи Чжан, Алексей Туманов, Эша Чуксе | Бумага | |
Обнаружение драгоценных камней в ранних слоях: ускорение LLMS с длинным контекстом с 1000x входным уменьшением токена Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, Shafiq joty | GitHub Бумага | |
| Декодирование спекулятивного луча динамической ширины для эффективного вывода LLM Zongyue Qin, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun | Бумага | |
CritipRefill: подход, основанный на сегменте, для предварительного ускорения в LLMS Джунлин Л.В., Юань Фенг, Xike Xie, Синь Цзяя, Циронг Пенг, Гиминг Си | GitHub Бумага | |
| Понимание: ускорение вывода LLM с длинным контекстом с помощью векторного поиска Di Liu, Meng Chen, Baotong Lu, Huiqiang jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, Lili qiu | Бумага | |
Сириус: контекстуальная разреженность с коррекцией для эффективных LLMS Ян Чжоу, Чжуминг Чен, Чжаоооооооо Сюй, Виктория Лин, Бейди Чен | GitHub Бумага | |
OneGen: эффективное однопроходное объединенное поколение и поиск для LLMS Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, Ningyu Zhang | 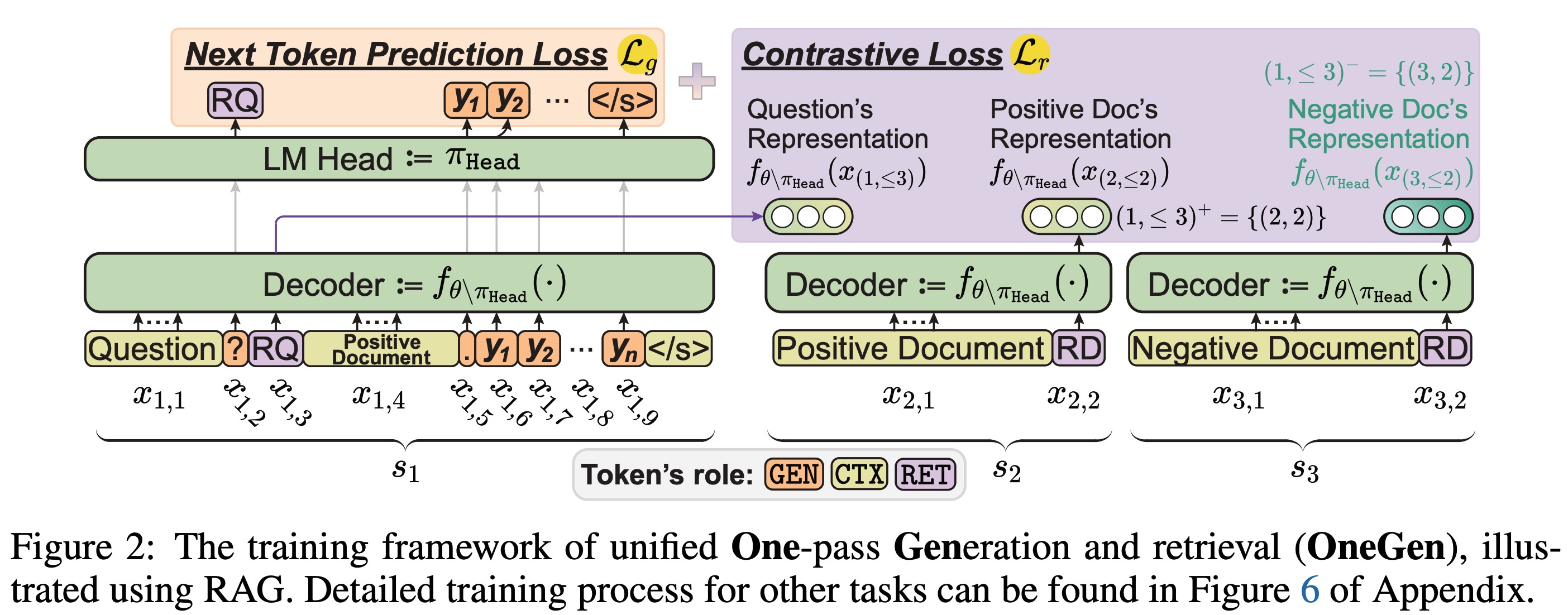 | GitHub Бумага |
| Консистентация пути: усиление префикса для эффективного вывода в LLM Jiace Zhu, Yingtao Shen, Jie Zhao, Zou | Бумага | |
| Увеличение спекулятивного декодирования без потерь с помощью выборки функций и частичного выравнивания дистилляции Lujun Gui, Bin Siao, Lei Su, Weipeng Chen | Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
Быстрый вывод смесей языковых моделей с разгрузкой с разгрузкой Artyom Eliseev, Denis Mazur |  | GitHub Бумага |
Конденсируется, не просто обрезка: повышение эффективности и производительности в обрезке Moe Layer Mingyu Cao, Gen Li, Jie Ji, Jiaqi Zhang, Xiaolong MA, Shiwei Liu, Lu Yin | GitHub Бумага | |
| Смесь экспертов по кондиционированию кэша для эффективного вывода мобильных устройств Андрия Склиар, связывание Ван Розендаала, Ромена Леперта, Тодора Боновского, Марта Ван Баалена, Маркуса Нагеля, Пола Уотмо, Бабака Эхтешами Бежнорди | Бумага | |
Монта: Ускорение обучения смеси с экспертами с параллельной оптимизацией с сетью-трейфом. Jingming Guo, Yan Liu, Yu Meng, Zhiwei Tao, Banglan Liu, Gang Chen, Xiang Li | GitHub Бумага | |
MOE-I2: сжатие смеси моделей экспертов через межпромежуточную обрезку и внутрипертовую декомпозицию с низким уровнем ранга Ченг Ян, Ян Суй, Джинки Сяо, Линги Хуанг, Ю Гун, Юанлин Дуан, Венки Цзя, Миао Инь, Ю Ченг, Бо Юань | GitHub Бумага | |
| Hobbit: система разгрузки смешанной точности для быстрого вывода MOE Пенг Тан, Цзячэн Лю, Сяофенг Хоу, Йифеи Пу, Цзин Ван, Фенг-Энн Хенг, Чао Ли, Миньи Го Гоо | Бумага | |
| Промо: быстрое обслуживание LLM на основе MOE с использованием проактивного кэширования Сенг Сяониу, Зиханг Чжун, Ронг Чен | Бумага | |
| Expertflow: оптимизированная активация экспертов и распределение токенов для эффективного вывода смеси экспертов Синь Хе, Шуканг Чжан, Юксин Ванг, Хайян Инь, Зихао Зенг, Шаохуай Ши, Чжэнхенг Тан, Сяоуэн Чу, Ивор Цанг, Онг Юс Скоро | Бумага | |
| EPS-ME: экспертный планировщик трубопровода для экономического вывода MOE Yulei Qian, Fengcun Li, Siangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai | Бумага | |
MC-ME: смесь компрессор для смеси Experts LLMS получает больше Вэй Хуанг, Юэ Ляо, Цзяньхуи Лю, Руайфей Хе, Хару Тан, Шиминг Чжан, Хонгшенг Ли, Си Лю, Сяоджуань Ци |  | GitHub Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
Mobillama: к точному и легкому полностью прозрачному GPT Омкар Тавакар, Ашмал Ваяни, Салман Хан, Хишам Чолакал, Рао М. Анвер, Майкл Фелсберг, Тим Болдуин, Эрик П. Син, Фахад Шахбаз Хан |  | GitHub Бумага Модель |
Мегалодон: эффективная предварительная подготовка и вывод LLM с неограниченной длиной контекста Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou | 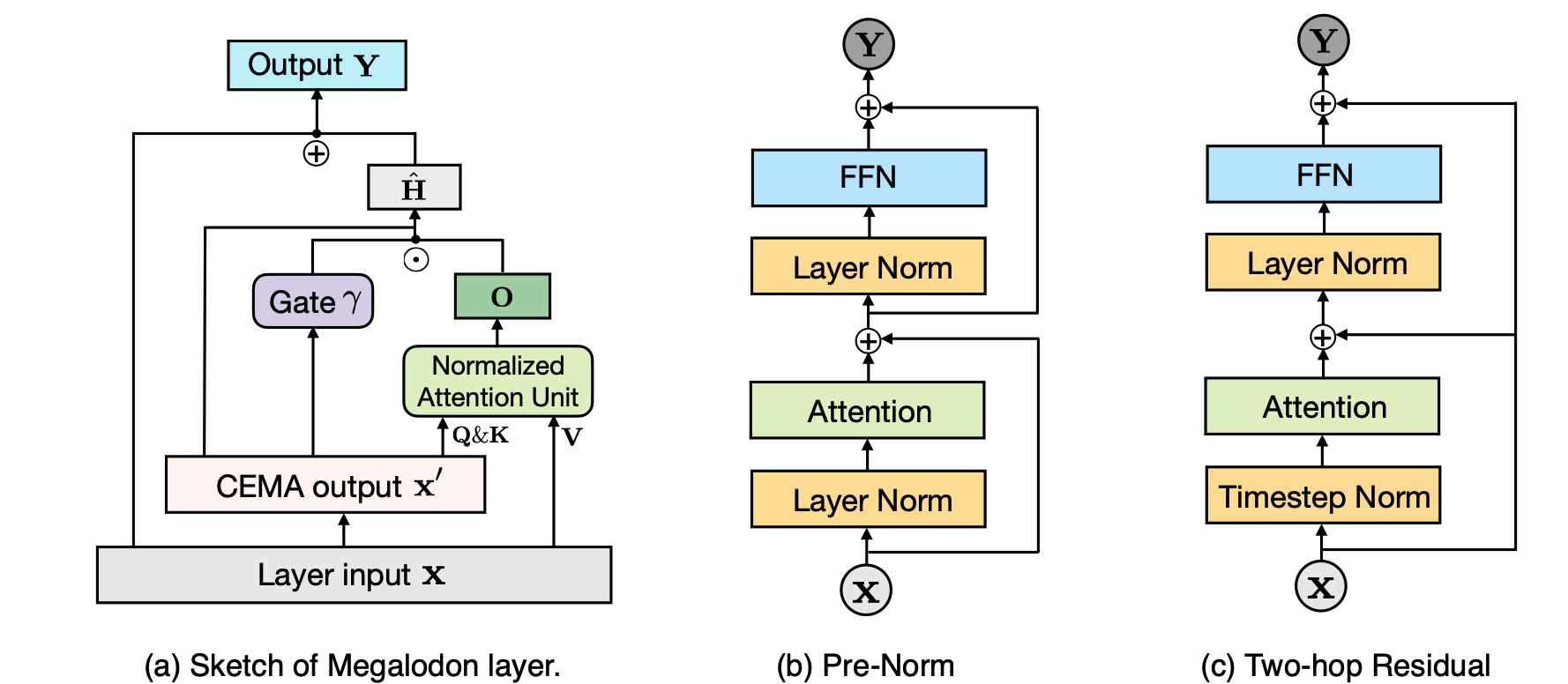 | GitHub Бумага |
| Тайпан: эффективные и выразительные модели космического языка состояния с селективным вниманием Chien van Nguyen, Huy Huu Nguyen, Thang M. Pham, Ruiyi Zhang, Hanieh Deilamsaley, Punet Mathur, Ryan A. Rossi, Trung Bui, Viet Dac Lai, Franck Dernoncourt, Thien Hu Nguyen | Бумага | |
Проглавляя: обучение внутреннему редкому вниманию в ваших LLMS Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang | GitHub Бумага | |
Обмен базисными базисными работами: совместное использование параметров для сжатия модели с большим языком Джингкун Ван, Ю-Гуан Чен, Инг-Чао Лин, Бинг Ли, Грейс Ли Чжан | GitHub Бумага | |
| Родимус*: нарушение компромисса эффективности с точностью с эффективным вниманием Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin | Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
| Модель рассказывает вам, что выбрасывать: адаптивное сжатие кэша кв для LLMS Suyu GE, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao |  | Бумага |
| ClusterKV: манипулирование кэшем LLM KV в семантическом пространстве для отзывного сжатия Гуанда Лю, Ченгвей Ли, Джиеру Чжао, Ченки Чжан, Миньи Го | Бумага | |
| Объединение сжатия кэша KV для больших языковых моделей с LeanKV Янки Чжан, Ювеи Ху, Рунеуан Чжао, Джон К.С. Луи, Хайбо Чен | Бумага | |
| Сжатие кв кэша для вывода LLM с длинным контекстом с сходством внимания межслойного внимания Da Ma, Lu Chen, Situo Zhang, Yuxun Miao, Su Zhu, Zhi Chen, Hongshen Xu, Hanqi Li, Shuai Fan, Lei Pan, Kai Yu | Бумага | |
| Minikv: выдвижение пределов вывода LLM с помощью 2-битного дискриминационного кв-кэша слоя. Akshat Sharma, Hangliang Ding, Jianping Li, Neel Dani, Minjia Zhang | Бумага | |
| Tokenselect: эффективная экстраполяция вывода и длины с длинным контекстом для LLMS с помощью динамического выбора кэша на уровне динамического токена Вэй Ву, Чжуоши Пан, Чао Ван, Ли -Чен, Юнбу Бай, Кун Фу, Чжэн Ван, Хуэй Сионг | Бумага | |
Не все головы. Ю Фу, Зефан Цай, Абеделькадир Аси, Уэйн Сионг, Юэ Донг, Вэнь Сяо |  | GitHub Бумага |
Buzz: Структурированный улей-структурированный квэш с сегментированными тяжелыми нападающими для эффективного вывода LLM Junqi Zhao, Zhijin Fang, Shu Li, Shaohui Yang, Shichao He | GitHub Бумага | |
Систематическое исследование межслойного распределения KV для эффективного вывода LLM Ты у, хайи у, кевей Ту |  | GitHub Бумага |
| Сжатие кэша без потерь до 2% Жен Ян, Джанхан, Кан Ву, Рубинг Си, Ан Ван, Синву Сан, Чжанхуй Кан | Бумага | |
| Matryoshkakv: адаптивное сжатие KV через обучаемую ортогональную проекцию Бокай Лин, Зихао Зенг, Зипенг Сяо, Сики Коу, Тяньки Хоу, Сяофенг Гао, Хао Чжан, Чжиджи Денг | Бумага | |
Остаточное квантование вектора для сжатия кэша квара в модели большого языка Анкур Кумар | GitHub Бумага | |
KVSharer: эффективный вывод с помощью уровня разнородного кеша KV Yifei Yang Yang, Zouing Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, Zhi Chen |  | GitHub Бумага |
| LORC: сжатие с низким рейтингом для кэша LLMS с стратегией прогрессивного сжатия Ронгжи Чжан, Куанг Ван, Лиюань Лю, Шуоханг Ван, Хао Ченг, Чао Чжан, Йелонг Шен | 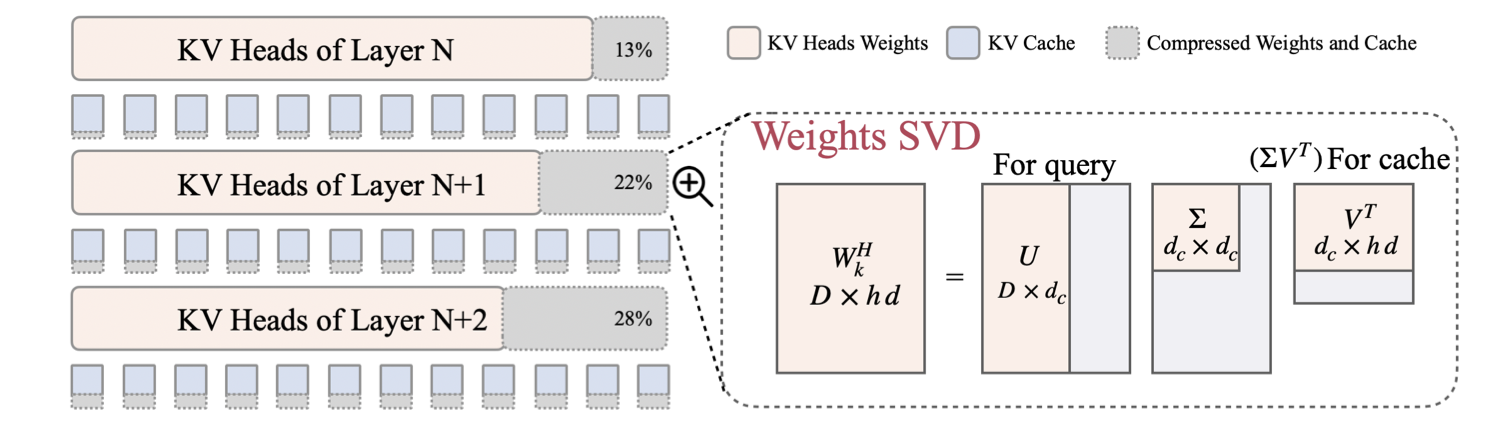 | Бумага |
| Swiftkv: Быстрый оптимизированный вывод с преобразованием модели обеспечения знаний Аурик Цяо, Жевей Яо, Самьям Раджбандари, Yuxiong He | Бумага | |
Динамическое сжатие памяти: модернизация LLMS для ускоренного вывода Петр Наврот, Адриан Ганкуки, Марцин Чохивски, Дэвид Тарджан, Эдоардо М. Понти | 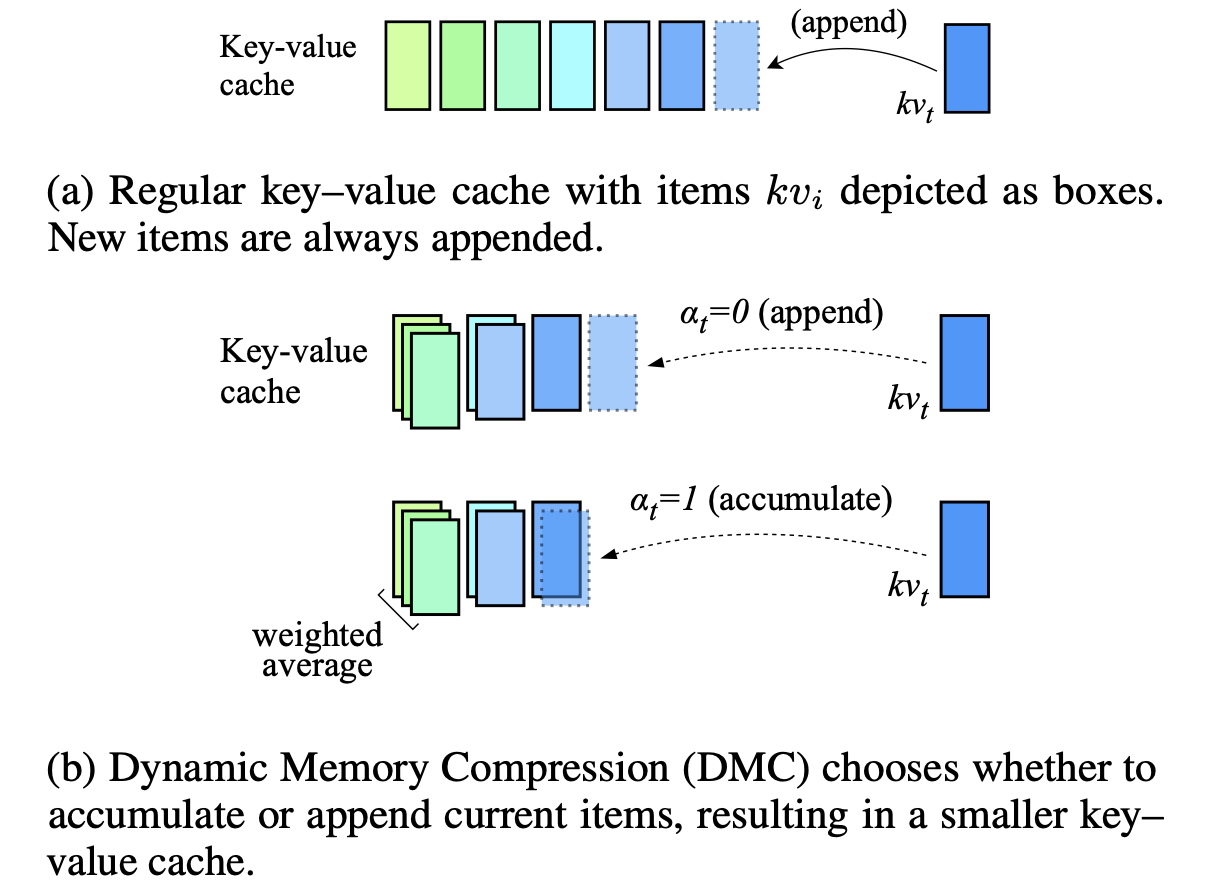 | Бумага |
| KV-Compress: сжатие кв-кэша на странице с переменной скоростью сжатия на головку внимания Исаак Регг | Бумага | |
ADA-KV: оптимизация выселения кэша KV путем адаптивного распределения бюджета для эффективного вывода LLM Юань Фэн, Джунлин Л.В., Юкун Цао, Xike Xie, С. Кевин Чжоу | 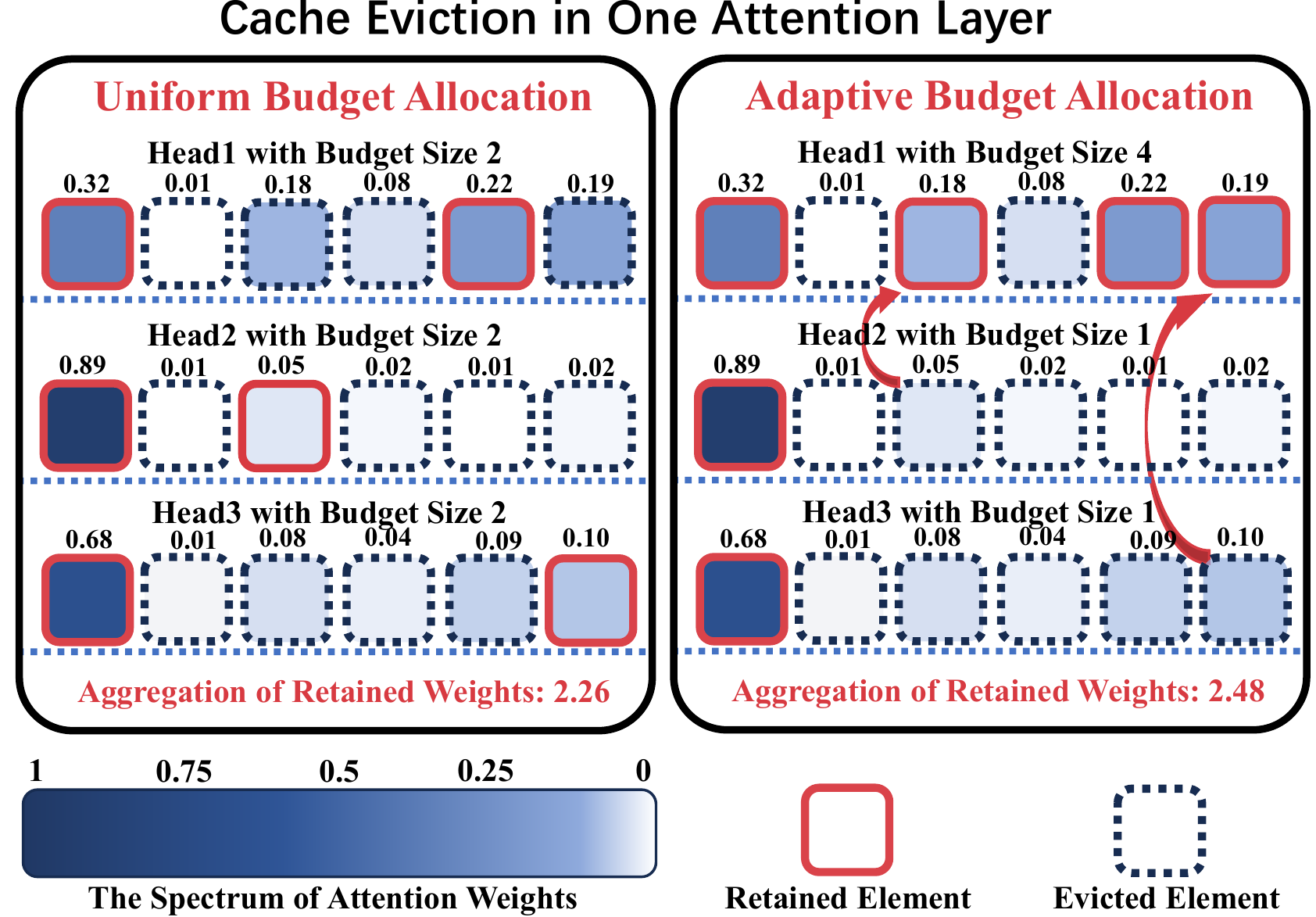 | GitHub Бумага |
AlignedKV: уменьшение доступа к памяти к KV-кэше с квантованием с выравниванием точности Йифан Тан, Хаоз Ван, Чао Ян, Яндонг Денг | GitHub Бумага | |
| CSKV: эффективное обучение каналов для кеша KV в сценариях с длинным контекстом Luning Wang, Shiyao Li, Xuefei Ning, Zhihang Yuan, Shengen Yan, Guohao Dai, Yu Wang | Бумага | |
| Первый взгляд на эффективный и безопасный вывод LLM на расстоянии от утечки KV Хуан Ян, Дейю Чжан, Юдонг Чжао, Юнэнчн Ли, Юньсин Лю | Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
Llmlingua: сжатие подсказок для ускоренного вывода моделей крупных языков Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu | 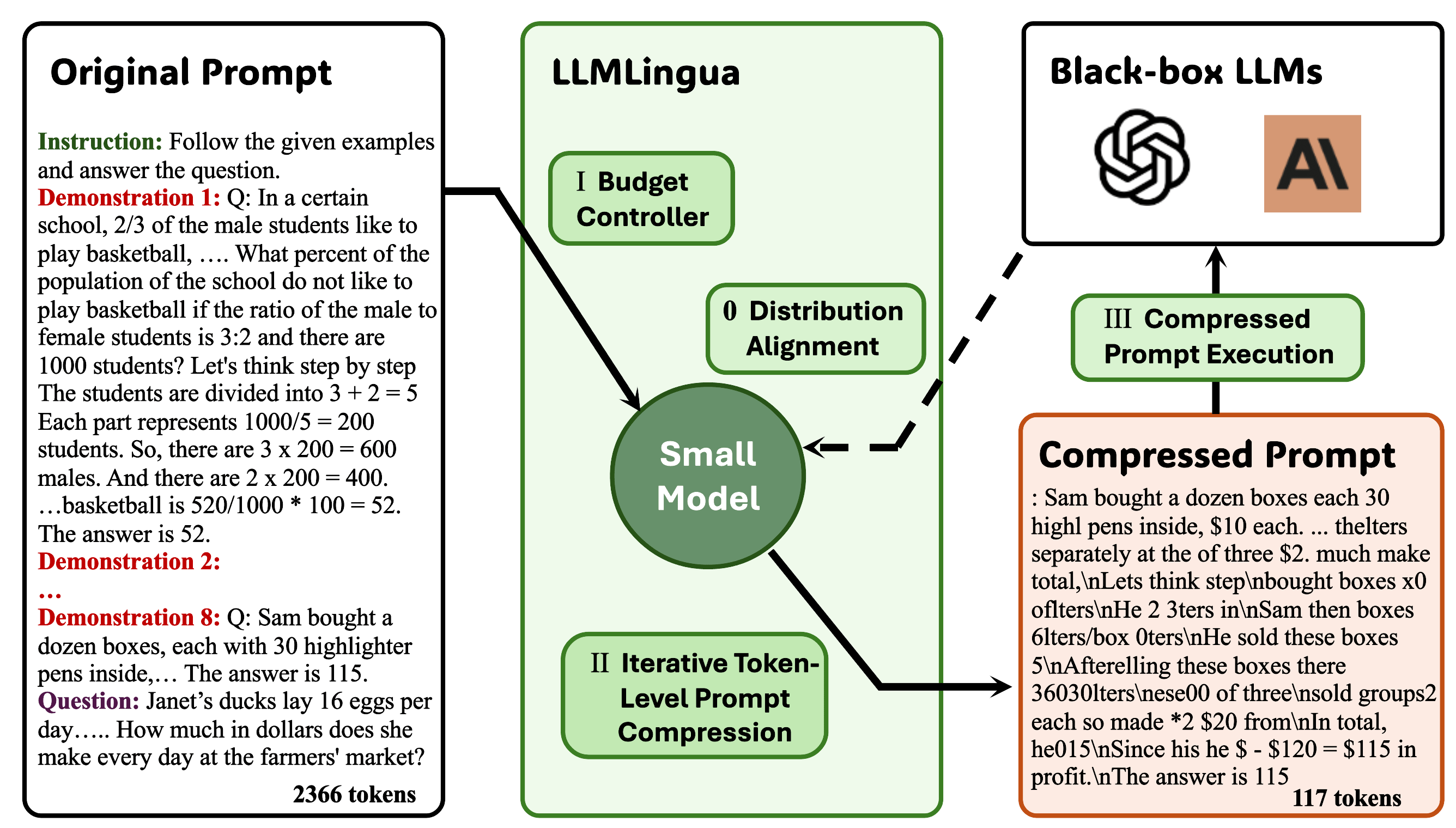 | GitHub Бумага |
Longllmlingua: ускорение и улучшение LLM в сценариях длинных контекстов посредством быстрого сжатия Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu | 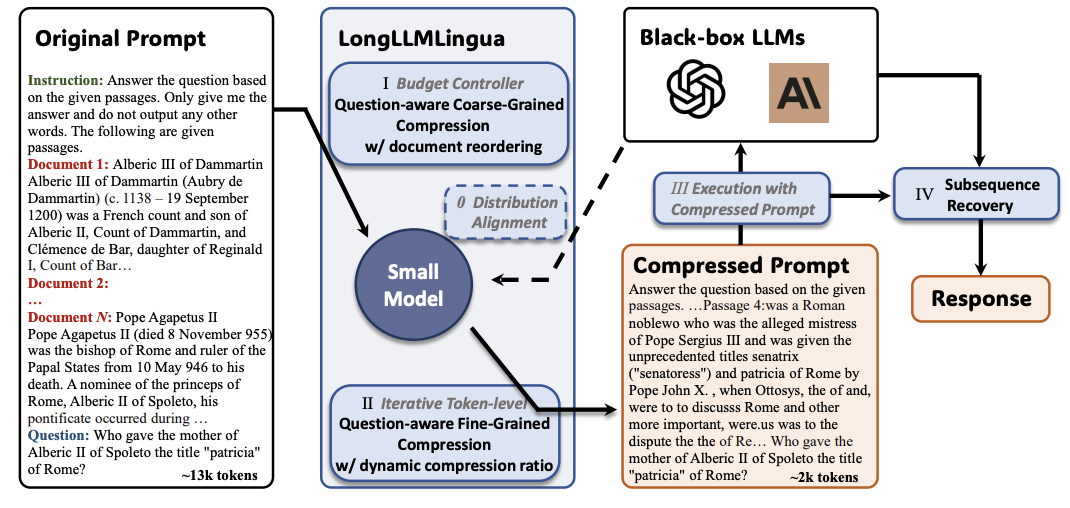 | GitHub Бумага |
| JPPO: совместная оптимизация мощности и быстрого ускоренного языкового модели Фейран ты, Хоньян Д.Ю., Каибин Хуанг, Аббас Джамалипур | Бумага | |
Генеративный контекст дистилляция Хэбин Шин, Лей Джи, Йенун Гонг, Сунгдонг Ким, Юнби Чой, Минджун Сео | | GitHub Бумага |
Multitok: токенизация с переменной длиной для эффективных LLMS, адаптированных из сжатия LZW Ноэль Элиас, Хома Эсфаханизаде, Каан Кале, Шрирам Вишванат, Мюриэль Медард | GitHub Бумага | |
Selection-P: самоотверженная задача-агрессивная оперативная сжатие для верности и передачи Цз Тинг Чунг, Лейанг Куй, Лемо Лю, Синьтинг Хуан, Шуминг Ши, Дит-Янь Юнг | Бумага | |
От чтения до сжатия: изучение многодокументного считывателя для быстрого сжатия Eunseong Choi, Sunkyung Lee, Minjin Choi, June Park, Jongwuk Lee | Бумага | |
| Компрессор восприятия: метод сжатия без обучения в длинных контекстных сценариях Jiwei Tang, Jin Xu, Tingwei Lu, Hai Lin, Yiming Zhao, Hai-Tao Zhheng | Бумага | |
Finezip: раздвижение пределов больших языковых моделей для практического сжатия текста без потерь Фазал Митту, Йихуан Бу, Акшат Гупта, Ашок Девирудди, Альп Эрен Оздарендели, Анант Сингх, Гопала Ануманчипалли | GitHub Бумага | |
Распоряжение деревьев управляют быстрого сжатия LLM Венхао Мао, Ченгбин Хоу, Тянью Чжан, Синью Лин, Ке Тан, Хайпонг Л.В. | GitHub Бумага | |
Alphazip: сжатие текста без потерь с потерей. Swathi Shree Narashiman, Nitin Chandrachoodan | GitHub Бумага | |
| TACO-RL: Оптимизация сжатия сжатия с помощью задачи с помощью обучения подкреплению Shivam Shandilya, Menglin Xia, Supriyo Ghosh, Huiqiang Jiang, Jue Zhang, Qianhui Wu, Victor Rühle | Бумага | |
| Эффективная дистилляция контекста LLM Раджеш Упадхаяйя, Захари Смит, Критофер Коттмайер, Маниш Радж Ости | Бумага | |
Улучшение и ускорение крупных языковых моделей с помощью контекстного сжатия с учетом инструкций Хауэн Ху, Фей М.А., Бинвен Бай, Синсин Чжу, Фей Ю | GitHub Бумага |
| Название и авторы | Введение | Ссылки |
|---|---|---|
Натуральное изобилие: ускорение изобилии для обучения LLM и точной настройки, экономически эффективного для памяти Ариджит Дас | GitHub Бумага | |
| Компактные: сжатые активации для обучения LLM с эффективной памятью Яра Шамшум, Ницан Ходос, Юваль Сирадцки, Асаф Шустер | Бумага | |
ESPACE: Dimensionality Reduction of Activations for Model Compression Charbel Sakr, Brucek Khailany | 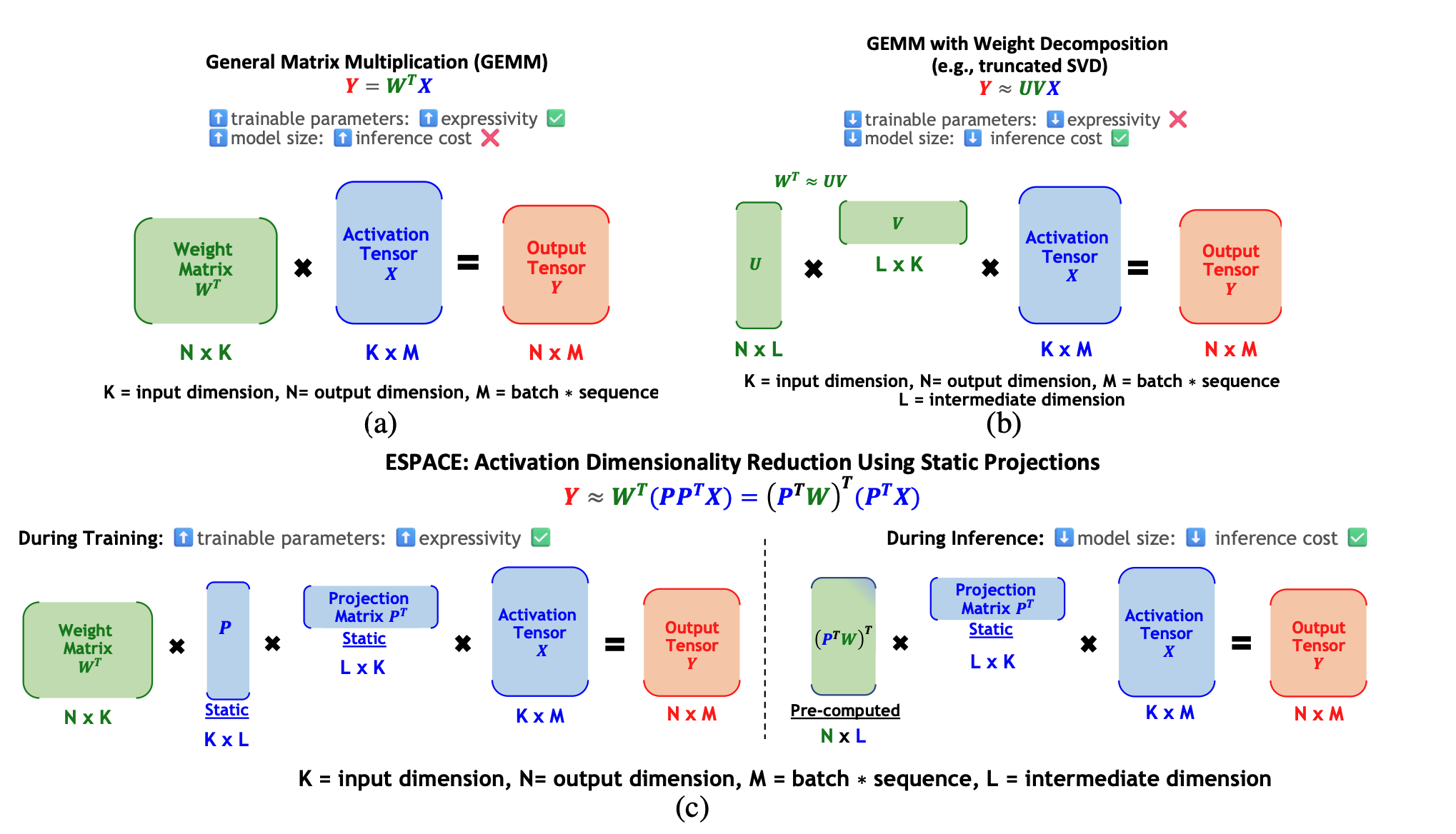 | Бумага |
| Title & Authors | Введение | Ссылки |
|---|---|---|
| FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving Ao Shen, Zhiyao Li, Mingyu Gao | Бумага | |
| CE-CoLLM: Efficient and Adaptive Large Language Models Through Cloud-Edge Collaboration Hongpeng Jin, Yanzhao Wu | Бумага | |
| Ripple: Accelerating LLM Inference on Smartphones with Correlation-Aware Neuron Management Tuowei Wang, Ruwen Fan, Minxing Huang, Zixu Hao, Kun Li, Ting Cao, Youyou Lu, Yaoxue Zhang, Ju Ren | Бумага | |
ALISE: Accelerating Large Language Model Serving with Speculative Scheduling Youpeng Zhao, Jun Wang | Бумага | |
| EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models Junhao Hu, Wenrui Huang, Haoyi Wang, Weidong Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, Tao Xie | Бумага | |
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training Jinda Jia, Cong Xie, Hanlin Lu, Daoce Wang, Hao Feng, Chengming Zhang, Baixi Sun, Haibin Lin, Zhi Zhang, Xin Liu, Dingwen Tao | Бумага | |
| FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs Haoran Lin, Xianzhi Yu, Kang Zhao, Lu Hou, Zongyuan Zhan et al | Бумага | |
| POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, Ashish Panwar | Бумага | |
TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices Zonghang Li, Wenjiao Feng, Mohsen Guizani, Hongfang Yu | Github Бумага | |
Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores Shaobo Ma, Chao Fang, Haikuo Shao, Zhongfeng Wang | Бумага | |
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models Jahyun Koo, Dahoon Park, Sangwoo Jung, Jaeha Kung | Бумага | |
| Accelerating Large Language Model Training with Hybrid GPU-based Compression Lang Xu, Quentin Anthony, Qinghua Zhou, Nawras Alnaasan, Radha R. Gulhane, Aamir Shafi, Hari Subramoni, Dhabaleswar K. Panda | Бумага |
| Title & Authors | Введение | Ссылки |
|---|---|---|
| HELENE: Hessian Layer-wise Clipping and Gradient Annealing for Accelerating Fine-tuning LLM with Zeroth-order Optimization Huaqin Zhao, Jiaxi Li, Yi Pan, Shizhe Liang, Xiaofeng Yang, Wei Liu, Xiang Li, Fei Dou, Tianming Liu, Jin Lu | Бумага | |
Robust and Efficient Fine-tuning of LLMs with Bayesian Reparameterization of Low-Rank Adaptation Ayan Sengupta, Vaibhav Seth, Arinjay Pathak, Natraj Raman, Sriram Gopalakrishnan, Tanmoy Chakraborty | Github Бумага | |
MiLoRA: Efficient Mixture of Low-Rank Adaptation for Large Language Models Fine-tuning Jingfan Zhang, Yi Zhao, Dan Chen, Xing Tian, Huanran Zheng, Wei Zhu | Бумага | |
RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates Md Kowsher, Tara Esmaeilbeig, Chun-Nam Yu, Mojtaba Soltanalian, Niloofar Yousefi | 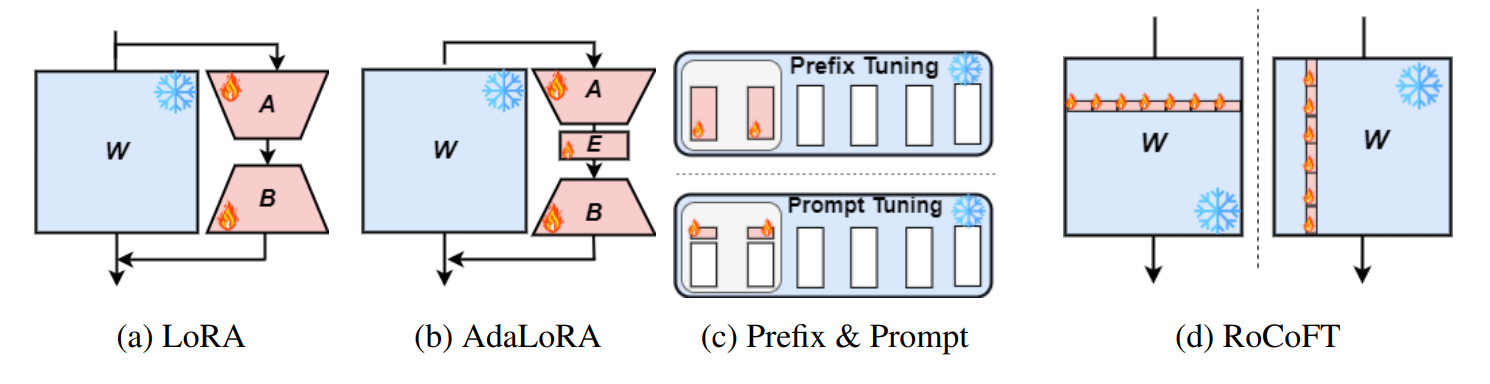 | Github Бумага |
Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models Kai Yao, Penlei Gao, Lichun Li, Yuan Zhao, Xiaofeng Wang, Wei Wang, Jianke Zhu | Github Бумага | |
Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning Nusrat Jahan Prottasha, Asif Mahmud, Md. Shohanur Islam Sobuj, Prakash Bhat, Md Kowsher, Niloofar Yousefi, Ozlem Ozmen Garibay | Бумага | |
QEFT: Quantization for Efficient Fine-Tuning of LLMs Changhun Lee, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park | Github Бумага | |
BIPEFT: Budget-Guided Iterative Search for Parameter Efficient Fine-Tuning of Large Pretrained Language Models Aofei Chang, Jiaqi Wang, Han Liu, Parminder Bhatia, Cao Xiao, Ting Wang, Fenglong Ma | Github Бумага | |
SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers Viktoriia Chekalina, Anna Rudenko, Gleb Mezentsev, Alexander Mikhalev, Alexander Panchenko, Ivan Oseledets | Github Бумага | |
| SpaLLM: Unified Compressive Adaptation of Large Language Models with Sketching Tianyi Zhang, Junda Su, Oscar Wu, Zhaozhuo Xu, Anshumali Shrivastava | Бумага | |
Bone: Block Affine Transformation as Parameter Efficient Fine-tuning Methods for Large Language Models Jiale Kang | Github Бумага | |
| Enabling Resource-Efficient On-Device Fine-Tuning of LLMs Using Only Inference Engines Lei Gao, Amir Ziashahabi, Yue Niu, Salman Avestimehr, Murali Annavaram | 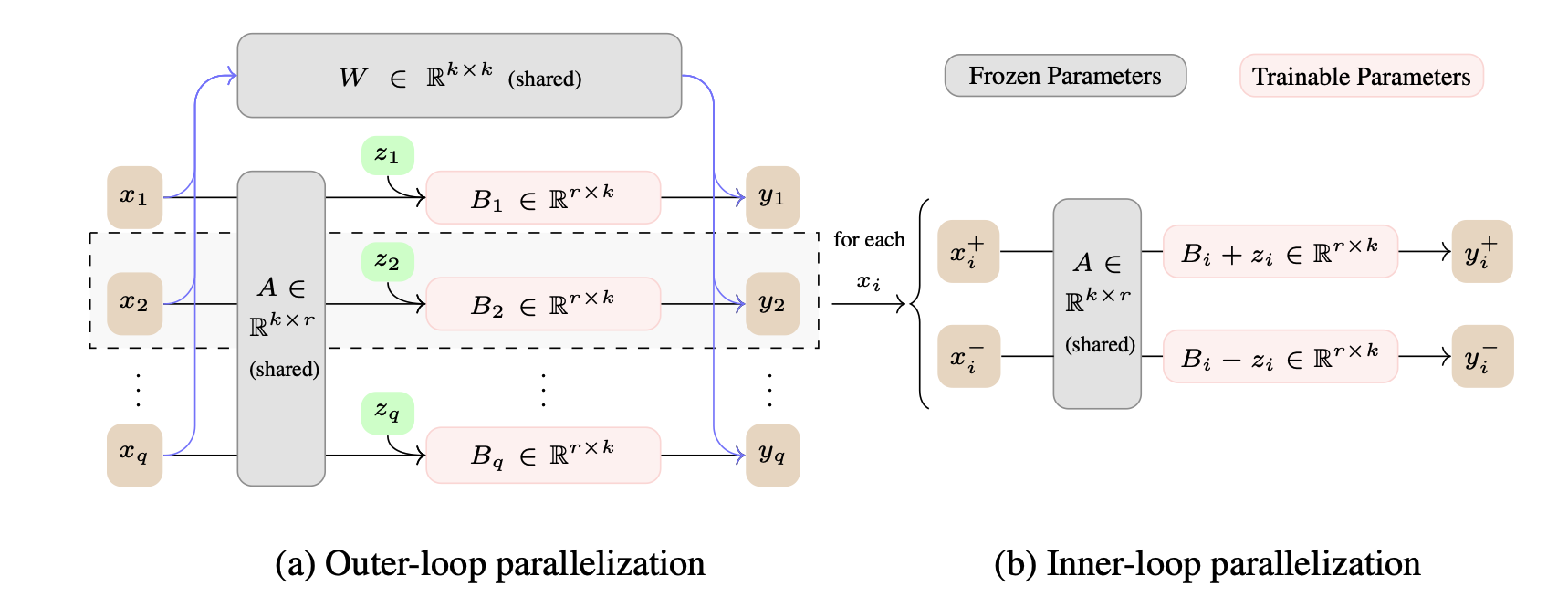 | Бумага |
| Title & Authors | Введение | Ссылки |
|---|---|---|
| AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning Changhai Zhou, Shiyang Zhang, Yuhua Zhou, Zekai Liu, Shichao Weng | 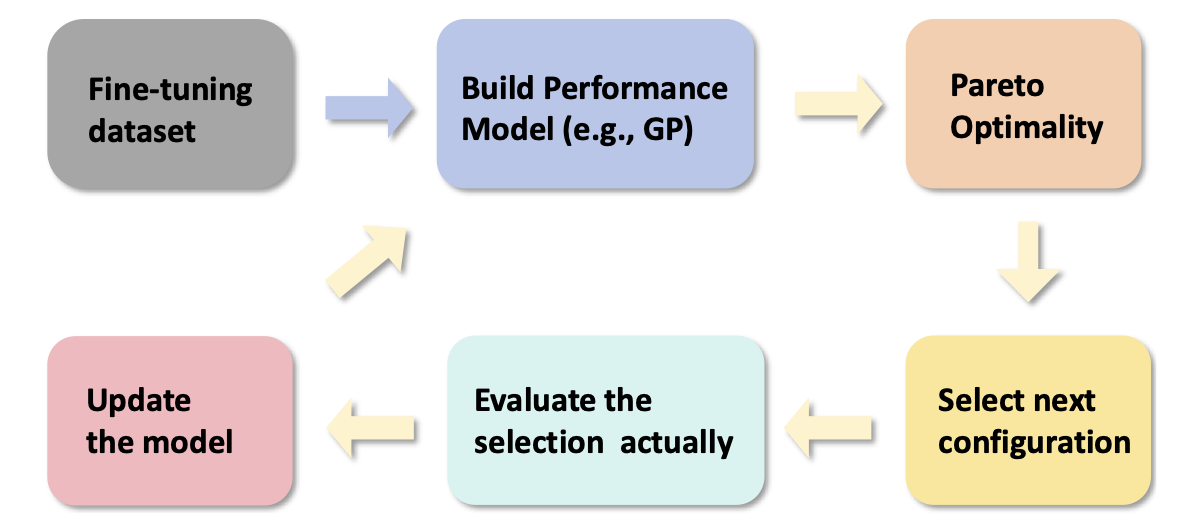 | Бумага |
Scalable Efficient Training of Large Language Models with Low-dimensional Projected Attention Xingtai Lv, Ning Ding, Kaiyan Zhang, Ermo Hua, Ganqu Cui, Bowen Zhou | Github Бумага | |
| Less is More: Extreme Gradient Boost Rank-1 Adaption for Efficient Finetuning of LLMs Yifei Zhang, Hao Zhu, Aiwei Liu, Han Yu, Piotr Koniusz, Irwin King | Бумага | |
COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training Haocheng Xi, Han Cai, Ligeng Zhu, Yao Lu, Kurt Keutzer, Jianfei Chen, Song Han | 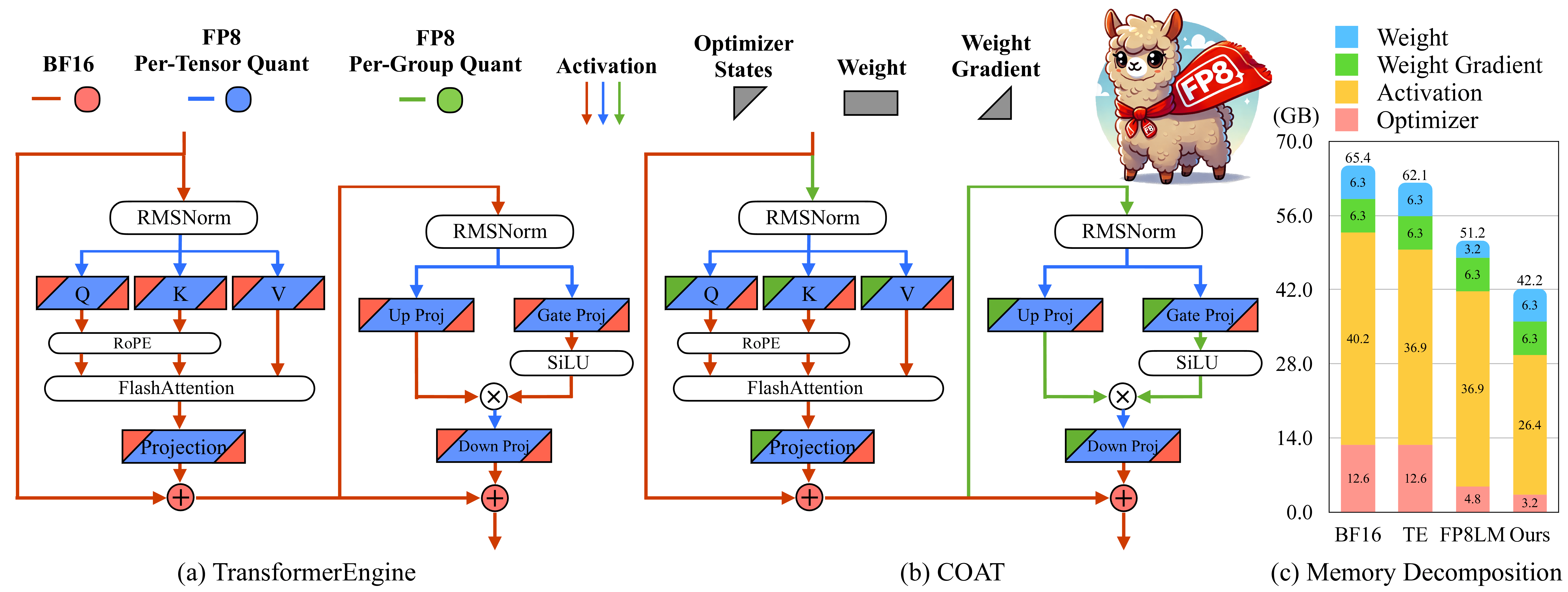 | Github Бумага |
BitPipe: Bidirectional Interleaved Pipeline Parallelism for Accelerating Large Models Training Houming Wu, Ling Chen, Wenjie Yu |  | Github Бумага |
| Title & Authors | Введение | Ссылки |
|---|---|---|
| Closer Look at Efficient Inference Methods: A Survey of Speculative Decoding Hyun Ryu, Eric Kim | Бумага | |
LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Accelerators Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus et al | Github Бумага | |
Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier | Github Бумага | |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai | Бумага | |
| A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Haotong Qin, Jinyang Guo, Michele Magno, Xianglong Liu | Бумага | |
Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey Sourav Verma | 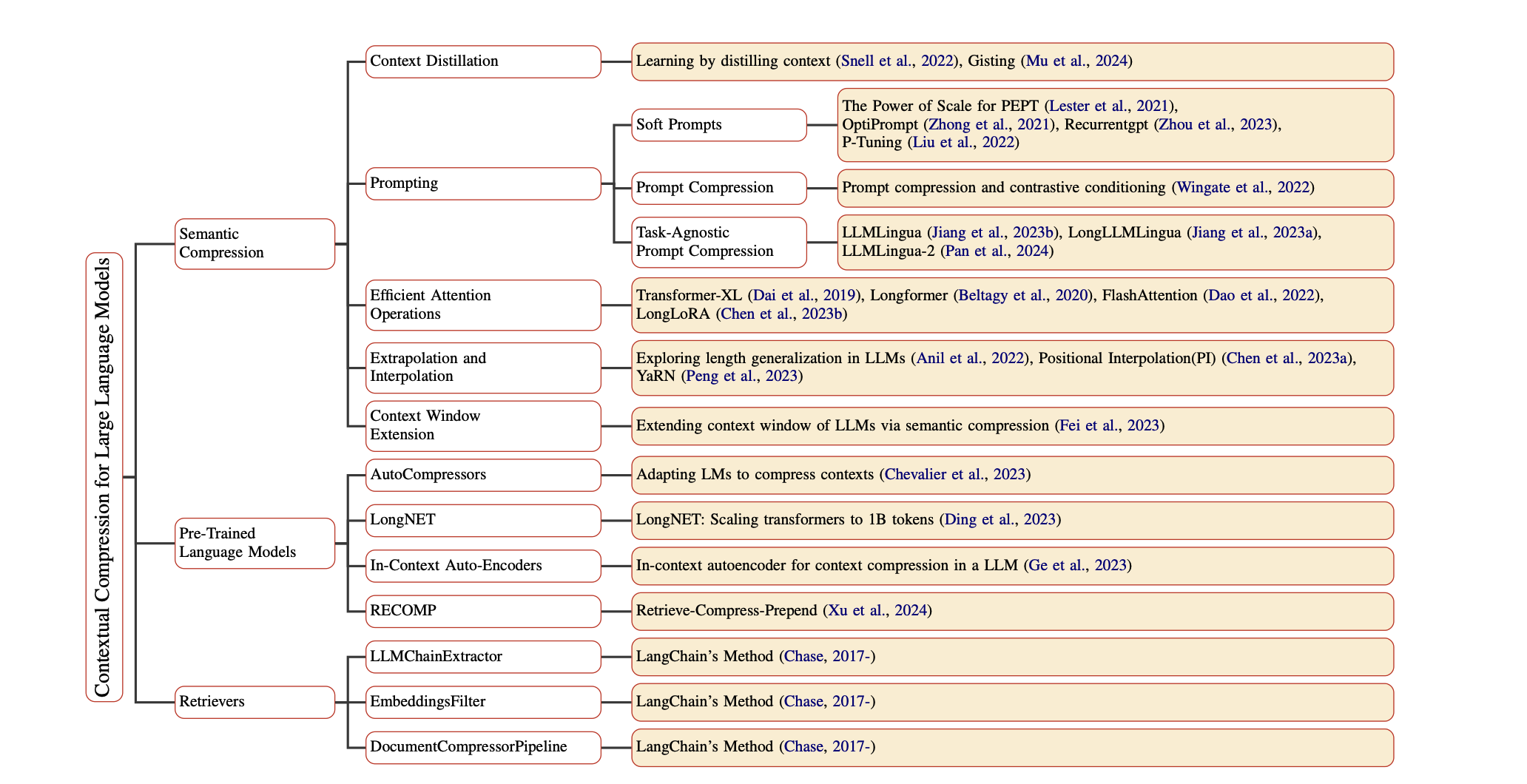 | Github Бумага |
| Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview Yanshu Wang, Tong Yang, Xiyan Liang, Guoan Wang, Hanning Lu, Xu Zhe, Yaoming Li, Li Weitao | Бумага | |
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris | Бумага | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song | Бумага |


