SORSA
1.0.1
該存儲庫包含紙質索薩的實驗的代碼:奇異值和大型語言模型的正規正規化奇異矢量的適應。
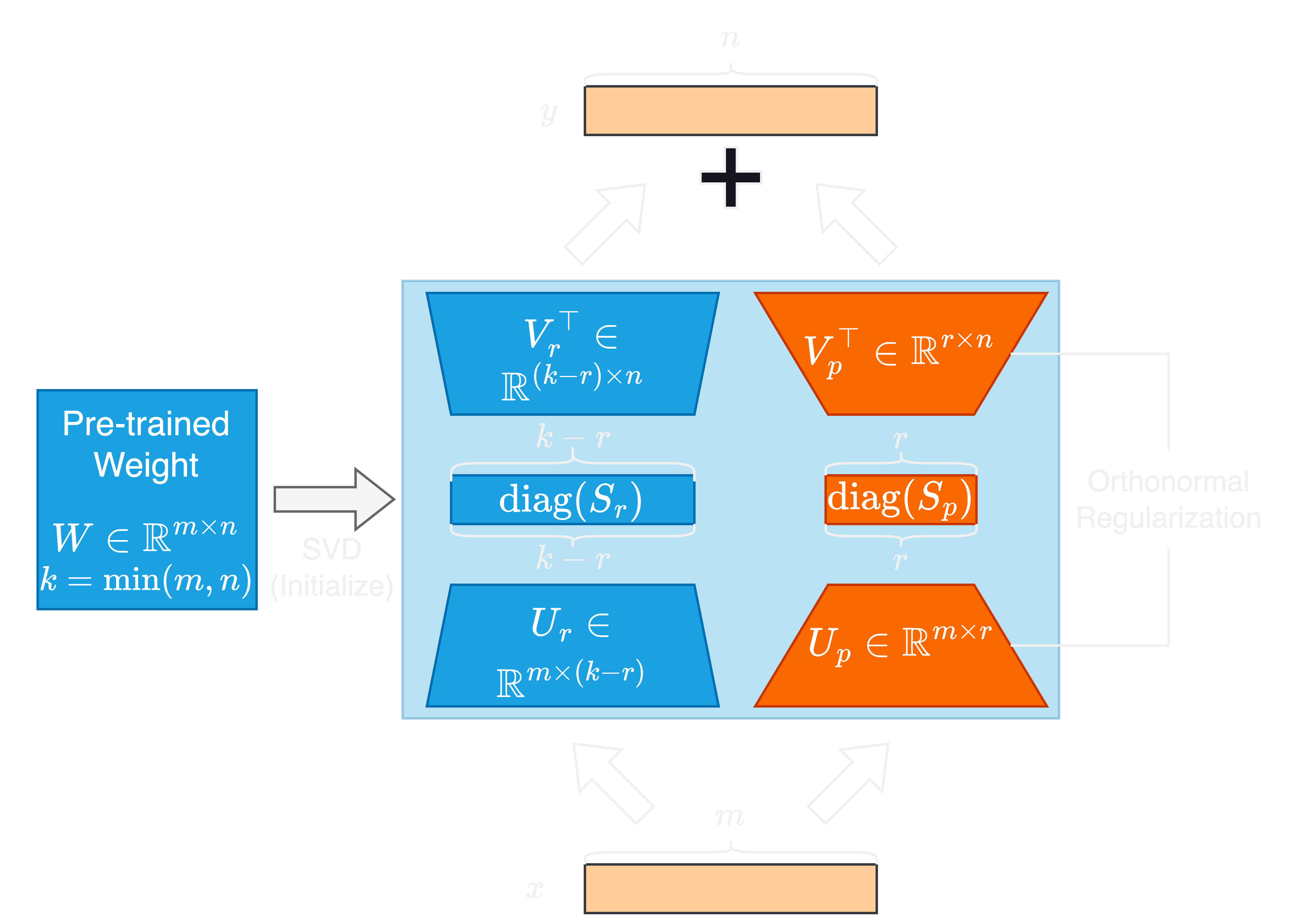
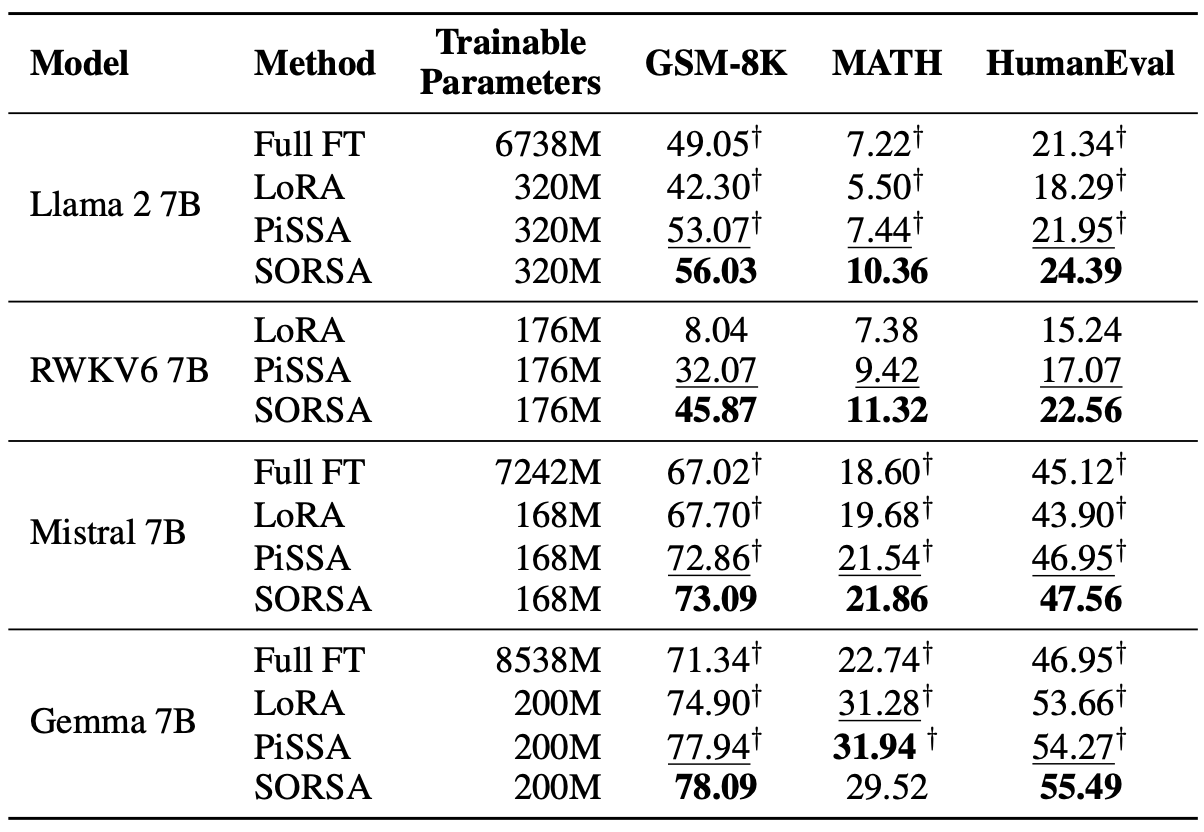
大語言模型(LLMS)的快速進步伴隨著其參數大小的顯著增加,對適應和微調提出了挑戰。參數有效的微調(PEFT)方法被廣泛用於適應下游任務的LLMS。在本文中,我們提出了奇異的值和正規正規化的奇異矢量適應,或者是一種新型的PEFT方法SORSA。每個SORSA適配器由兩個主要部分組成:可訓練的主要奇異重量
首先,從PIP安裝sorsa軟件包:
pip install sorsa然後,在項目的根目錄中創建.env文件,並添加您的擁抱面孔訪問令牌:
hf=Your_Hugging_Face_Access_Token首先,通過Anaconda安裝軟件包
conda env create -f environment.yml從./scripts/train_sorsa.sh運行腳本以訓練模型。
訓練後,運行./scripts/merge_sorsa.sh將適配器合併到基本模型:
運行以下命令以在GSM-8K上進行評估:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16運行以下命令進行數學評估:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16運行以下命令以評估人類事件:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16如果您正在培訓,合併或測試RWKV6型號,請添加--rwkv標誌為run.py
您可以使用Bibtex代碼來引用工作,如下所示:
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

