SORSA
1.0.1
Этот репозиторий содержит коды экспериментов по бумажной Сорсе: единственные ценности и ортонормальные регуляризованные единственные векторы адаптация крупных языковых моделей .
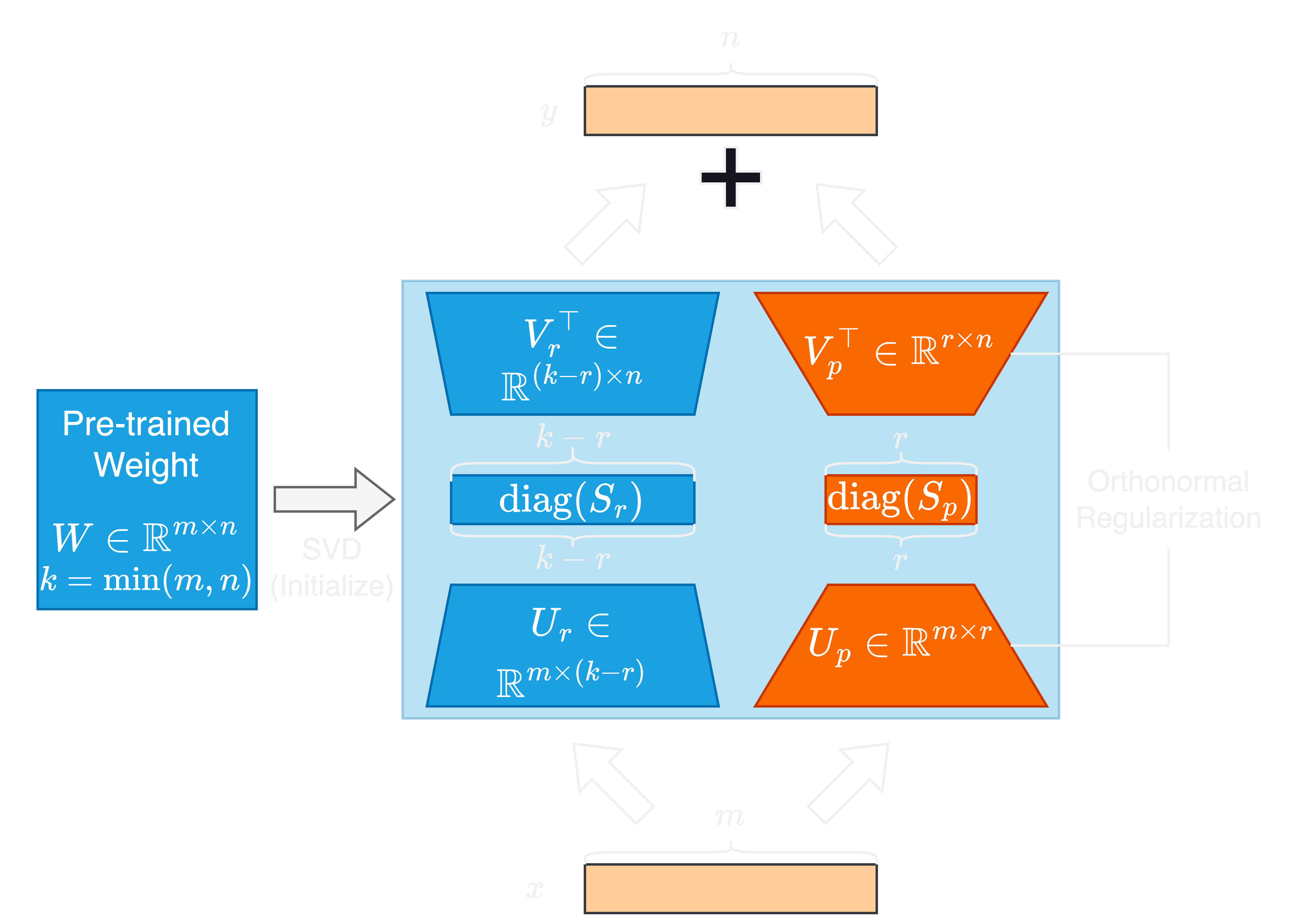
Быстрый прогресс в моделях крупных языков (LLMS) поставляется со значительным увеличением размера их параметров, что представляет проблемы для адаптации и тонкой настройки. Методы с точной настройкой параметров (PEFT) широко используются для эффективной адаптации LLM для эффективной задачи. В этой статье мы предлагаем единственные ценности и ортонормальные регуляризованные единственные векторы адаптация, или SORSA, новый метод PEFT. Каждый адаптер SORSA состоит из двух основных частей: обучаемые основные единственные веса
Сначала установите пакет sorsa от PIP:
pip install sorsa Затем создайте файл .env в корневом каталоге проекта и добавьте свой токен доступа к лицу:
hf=Your_Hugging_Face_Access_TokenСначала установите пакеты через Anaconda
conda env create -f environment.yml Запустите сценарии от ./scripts/train_sorsa.sh для обучения модели.
После обучения запустите ./scripts/merge_sorsa.sh , чтобы объединить адаптер с базовой моделью:
Запустите следующую команду для оценки GSM-8K:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16Запустите следующую команду, чтобы оценить по математике:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16Запустите следующую команду, чтобы оценить Humaneval:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 Если вы тренируете, слияете или тестируете модель RWKV6, пожалуйста, добавьте --rwkv Flag для run.py
Вы можете привести работу, используя код Bibtex следующим образом:
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

