SORSA
1.0.1
يحتوي هذا المستودع على رموز تجارب SORSA الورقية: القيم الفردية والتكييف المفرد المنتظم من النماذج اللغوية الكبيرة .
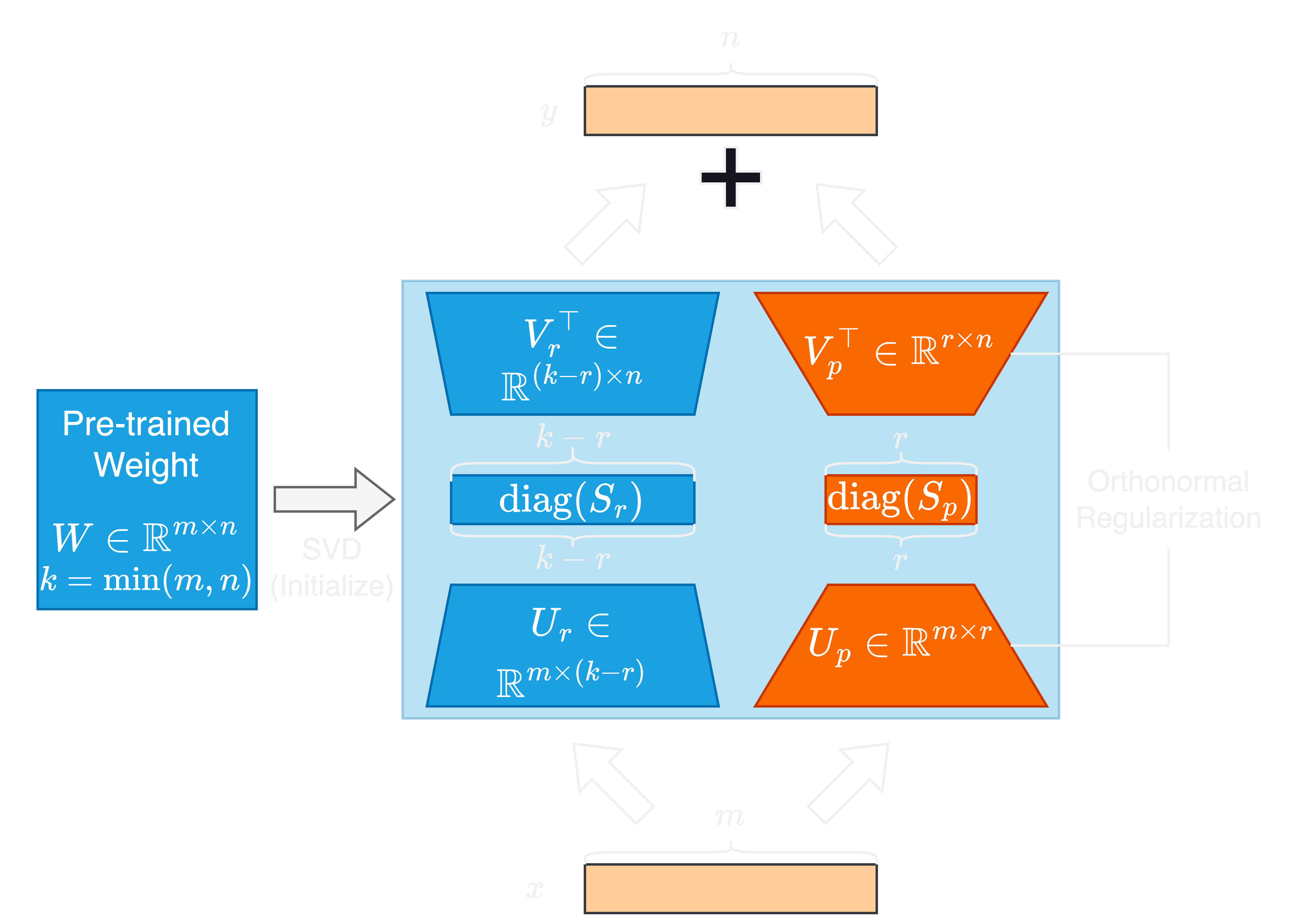
يأتي التقدم السريع في نماذج اللغة الكبيرة (LLMS) مع زيادة كبيرة في حجم المعلمة ، مما يمثل تحديات للتكيف والضبط. تُستخدم أساليب الضبط الدقيق (PEFT) الموفرة للمعلمة على نطاق واسع لتكييف LLMs لمهام المصب بكفاءة. في هذه الورقة ، نقترح القيم الفردية والتكيف المفرد المنتظم العظمي ، أو SORSA ، طريقة PEFT جديدة. يتكون كل محول Sorsa من جزأين رئيسيين: أوزان فردية رئيسية قابلة للتدريب
أولاً ، قم بتثبيت حزمة sorsa من PIP:
pip install sorsa ثم ، قم بإنشاء ملف .env في الدليل الجذر للمشروع وأضف رمز الوصول إلى وجهك:
hf=Your_Hugging_Face_Access_Tokenأولاً ، قم بتثبيت الحزم عبر Anaconda
conda env create -f environment.yml قم بتشغيل البرامج النصية من ./scripts/train_sorsa.sh لتدريب النموذج.
بعد التدريب ، قم بتشغيل ./scripts/merge_sorsa.sh لدمج المحول على النموذج الأساسي:
قم بتشغيل الأمر التالي للتقييم على GSM-8K:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16قم بتشغيل الأمر التالي لتقييم الرياضيات:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16قم بتشغيل الأمر التالي للتقييم على Humaneval:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 إذا كنت تتدرب أو تندمج أو اختبار طراز RWKV6 ، فيرجى إضافة --rwkv Flag to run.py
يمكنك الاستشهاد بالعمل باستخدام رمز bibtex على النحو التالي:
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

