SORSA
1.0.1
พื้นที่เก็บข้อมูลนี้มีรหัสของการทดลองของกระดาษ Sorsa: ค่าเอกพจน์และการปรับเวกเตอร์เอกพจน์แบบออร์โธนตามปกติของแบบจำลองภาษาขนาดใหญ่
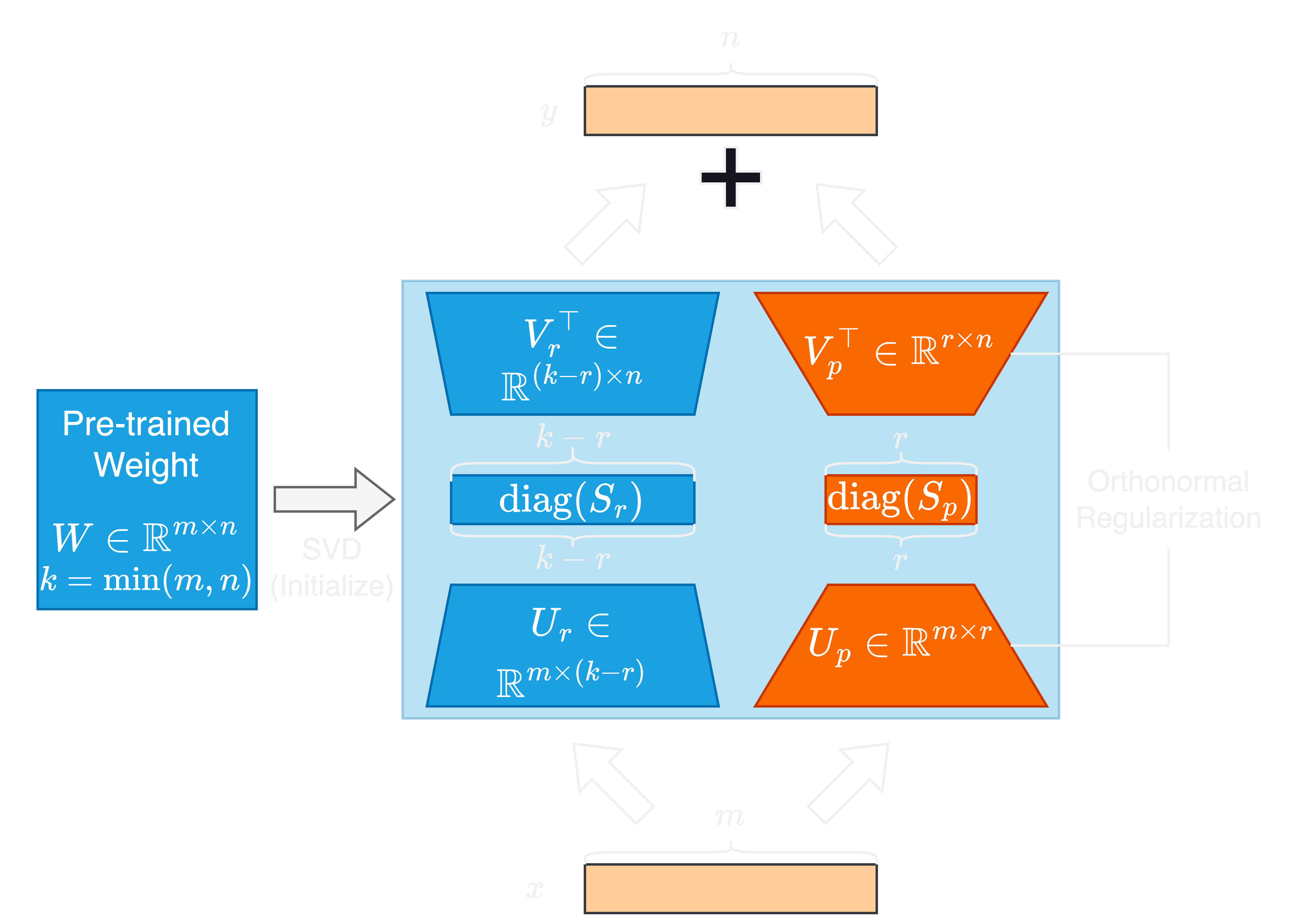
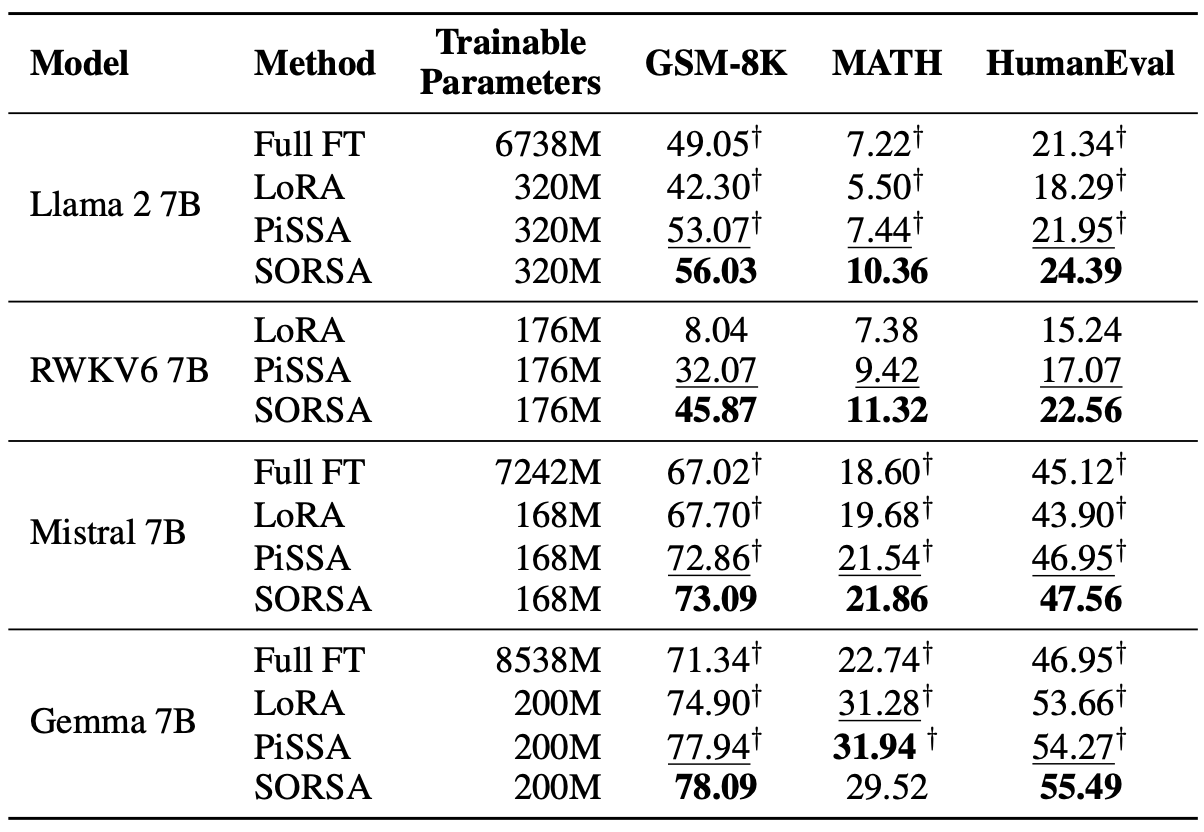
ความก้าวหน้าอย่างรวดเร็วในรูปแบบภาษาขนาดใหญ่ (LLMS) มาพร้อมกับการเพิ่มขนาดพารามิเตอร์ของพวกเขาอย่างมีนัยสำคัญนำเสนอความท้าทายสำหรับการปรับตัวและการปรับแต่ง วิธีการปรับแต่งพารามิเตอร์การปรับจูน (PEFT) นั้นใช้กันอย่างแพร่หลายในการปรับ LLMs สำหรับงานดาวน์สตรีมได้อย่างมีประสิทธิภาพ ในบทความนี้เราเสนอค่าเอกพจน์และการปรับตัวของเวกเตอร์แบบเอกพจน์แบบออร์โธนอลหรือ Sorsa ซึ่งเป็นวิธี PEFT แบบใหม่ อะแดปเตอร์ Sorsa แต่ละตัวประกอบด้วยสองส่วนหลัก: น้ำหนักเอกพจน์หลักฝึกอบรมได้
ก่อนอื่นให้ติดตั้งแพ็คเกจ sorsa จาก PIP:
pip install sorsa จากนั้นสร้างไฟล์ .env ในไดเรกทอรีรากของโครงการและเพิ่มโทเค็นการเข้าถึงใบหน้าของคุณ:
hf=Your_Hugging_Face_Access_Tokenก่อนอื่นให้ติดตั้งแพ็คเกจผ่าน Anaconda
conda env create -f environment.yml เรียกใช้สคริปต์จาก ./scripts/train_sorsa.sh เพื่อฝึกอบรมโมเดล
หลังจากการฝึกอบรมให้เรียกใช้ ./scripts/merge_sorsa.sh เพื่อรวมอะแดปเตอร์เข้ากับโมเดลพื้นฐาน:
เรียกใช้คำสั่งต่อไปนี้เพื่อประเมินบน GSM-8K:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16เรียกใช้คำสั่งต่อไปนี้เพื่อประเมินทางคณิตศาสตร์:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16เรียกใช้คำสั่งต่อไปนี้เพื่อประเมินเกี่ยวกับ HumanEval:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 หากคุณกำลังฝึกอบรมการรวมหรือทดสอบรุ่น RWKV6 โปรดเพิ่ม --rwkv Flag เพื่อ run.py
คุณสามารถอ้างอิงงานได้โดยใช้รหัส BIBTEX ดังนี้:
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

