SORSA
1.0.1
Este repositorio contiene los códigos de experimentos del documento SORSA: valores singulares y adaptación de vectores singulares regularizados ortonormales de modelos de idiomas grandes .
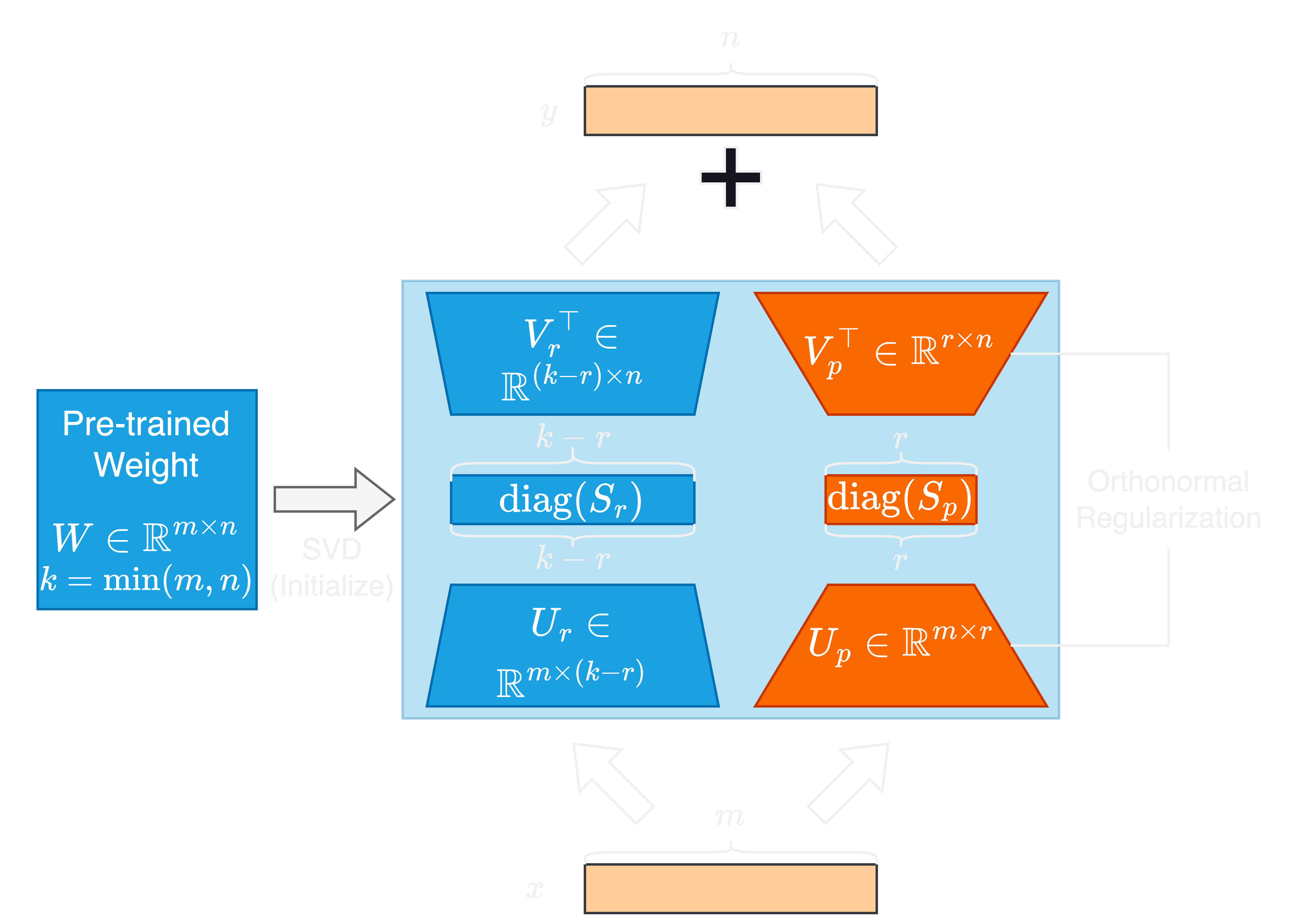
El rápido avance en los modelos de idiomas grandes (LLM) viene con un aumento significativo en el tamaño de su parámetro, presentando desafíos para la adaptación y ajuste fino. Los métodos de ajuste fino (PEFT) de parámetros se utilizan ampliamente para adaptar de manera eficiente las LLM para tareas posteriores. En este artículo, proponemos valores singulares y adaptación ortonormal de vectores singulares regularizados, o Sorsa, un nuevo método PEFF. Cada adaptador Sorsa consta de dos partes principales: Pesos singulares principales entrenables
Primero, instale el paquete sorsa desde PIP:
pip install sorsa Luego, cree el archivo .env en el directorio raíz del proyecto y agregue su token de acceso facial de abrazos:
hf=Your_Hugging_Face_Access_TokenPrimero, instale los paquetes a través de Anaconda
conda env create -f environment.yml Ejecute scripts desde ./scripts/train_sorsa.sh para entrenar el modelo.
Después del entrenamiento, ejecute ./scripts/merge_sorsa.sh para fusionar el adaptador al modelo base:
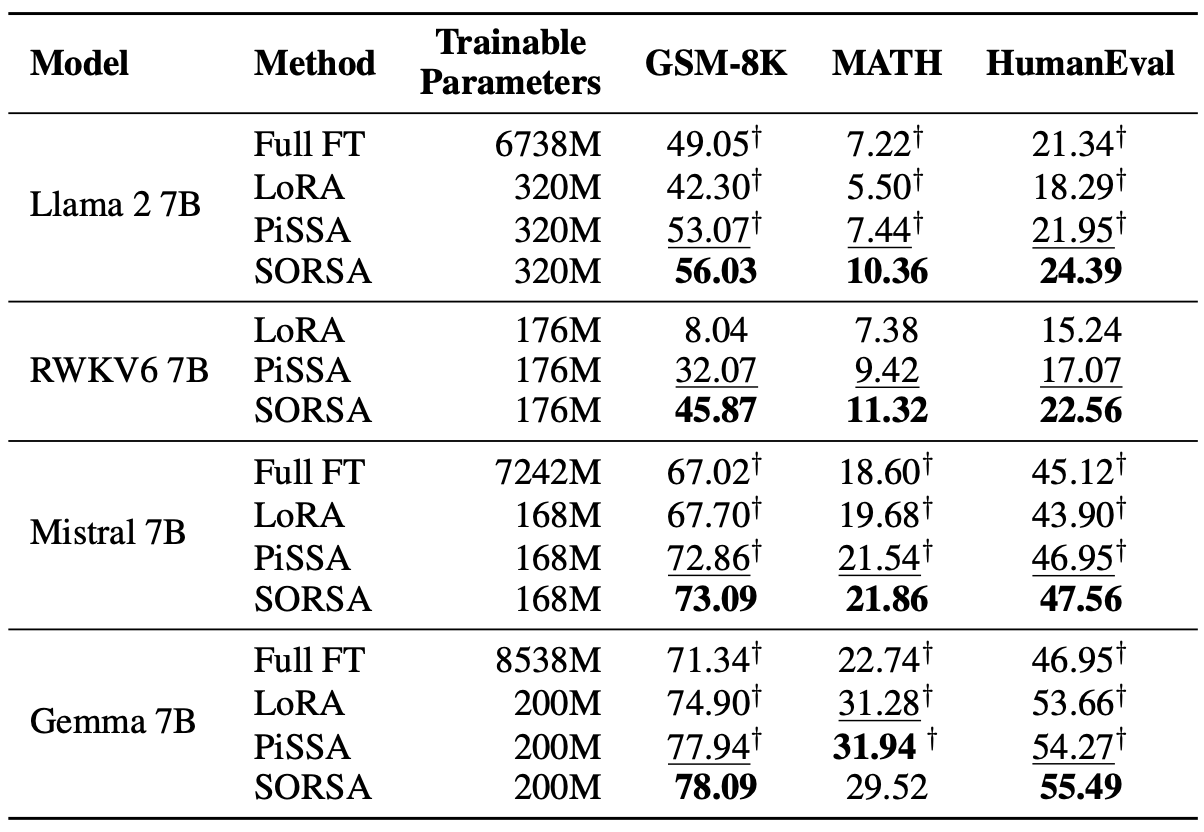
Ejecute el siguiente comando para evaluar en GSM-8K:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16Ejecute el siguiente comando para evaluar en matemáticas:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16Ejecute el siguiente comando para evaluar en Humaneval:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 Si está entrenando, fusionando o probando el modelo RWKV6, agregue --rwkv Flag a run.py
Puede citar el trabajo utilizando el código Bibtex de la siguiente manera:
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

