SORSA
1.0.1
このリポジトリには、SORSAの紙の実験コードが含まれています:特異値と、大規模な言語モデルの正規定型化された単数形のベクトル適応が含まれています。
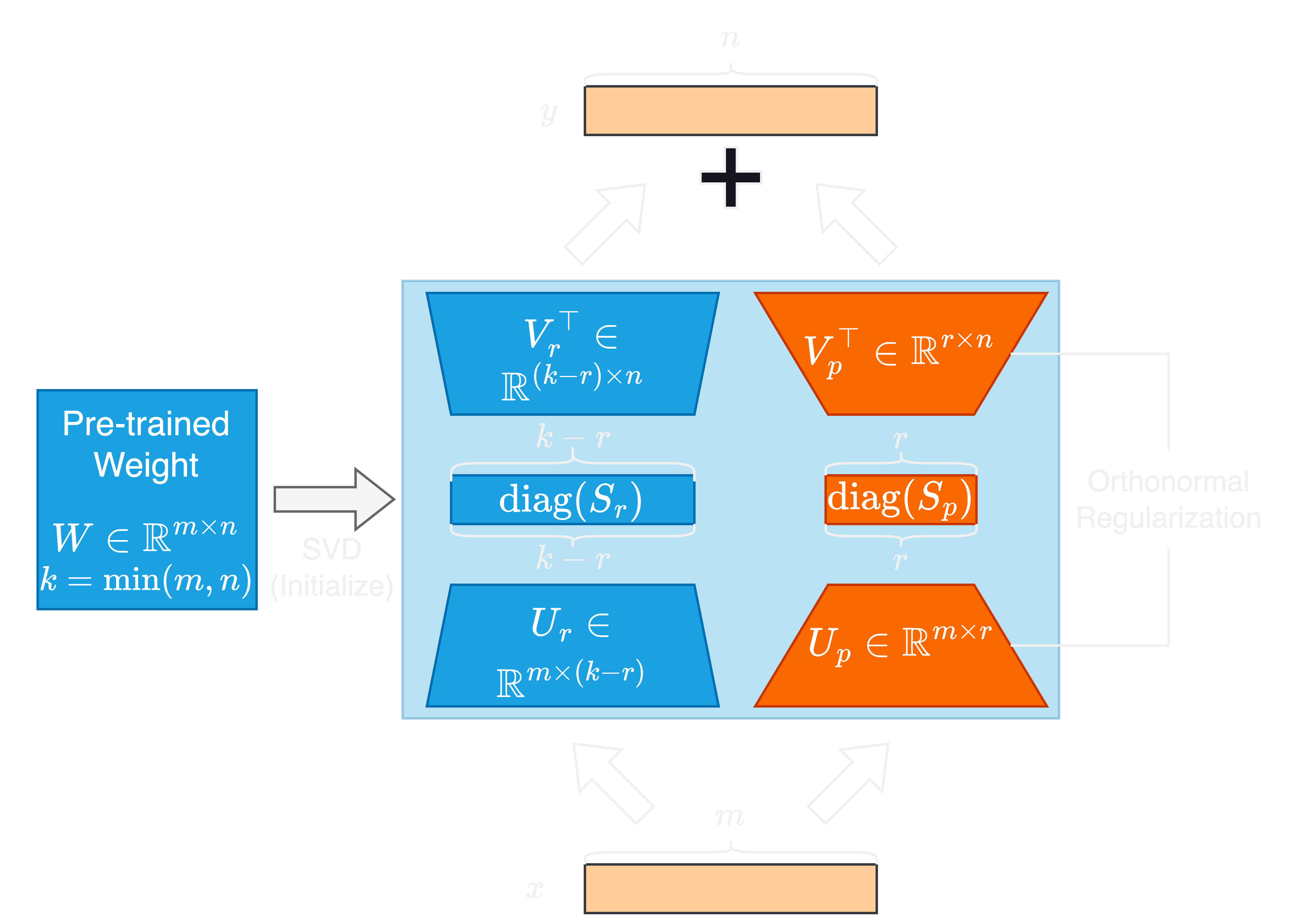
大規模な言語モデル(LLMS)の急速な進歩には、パラメーターサイズが大幅に増加し、適応と微調整の課題があります。パラメーター効率の高い微調整(PEFT)メソッドは、LLMSをダウンストリームタスクに効率的に適応させるために広く使用されています。このホワイトペーパーでは、単数の値と正規の正規化された特異ベクターの適応、または新しいPEFT法であるSORSAを提案します。各SORSAアダプターは、2つの主要な部分で構成されています。トレーニング可能な主要な特異ウェイト
まず、PIPからsorsaパッケージをインストールします。
pip install sorsa次に、プロジェクトのルートディレクトリに.envファイルを作成し、ハグするフェイスアクセストークンを追加します。
hf=Your_Hugging_Face_Access_Tokenまず、Anaconda経由でパッケージをインストールします
conda env create -f environment.yml ./scripts/train_sorsa.shからスクリプトを実行して、モデルをトレーニングします。
トレーニング後、 ./scripts/merge_sorsa.sh merge_sorsa.shを実行して、アダプターをベースモデルにマージします。
次のコマンドを実行してGSM-8Kで評価します。
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16数学で評価するために次のコマンドを実行します。
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16次のコマンドを実行して、Humanevalで評価します。
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 RWKV6モデルのトレーニング、マージ、またはテストを行っている場合は、 --rwkvフラグをrun.pyに追加してください。
次のように、bibtexコードを使用して作業を引用できます。
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

