SORSA
1.0.1
Este repositório contém os códigos de experimentos do artigo Sorsa: valores singulares e vetores singulares regularizados ortonormais adaptação de grandes modelos de linguagem .
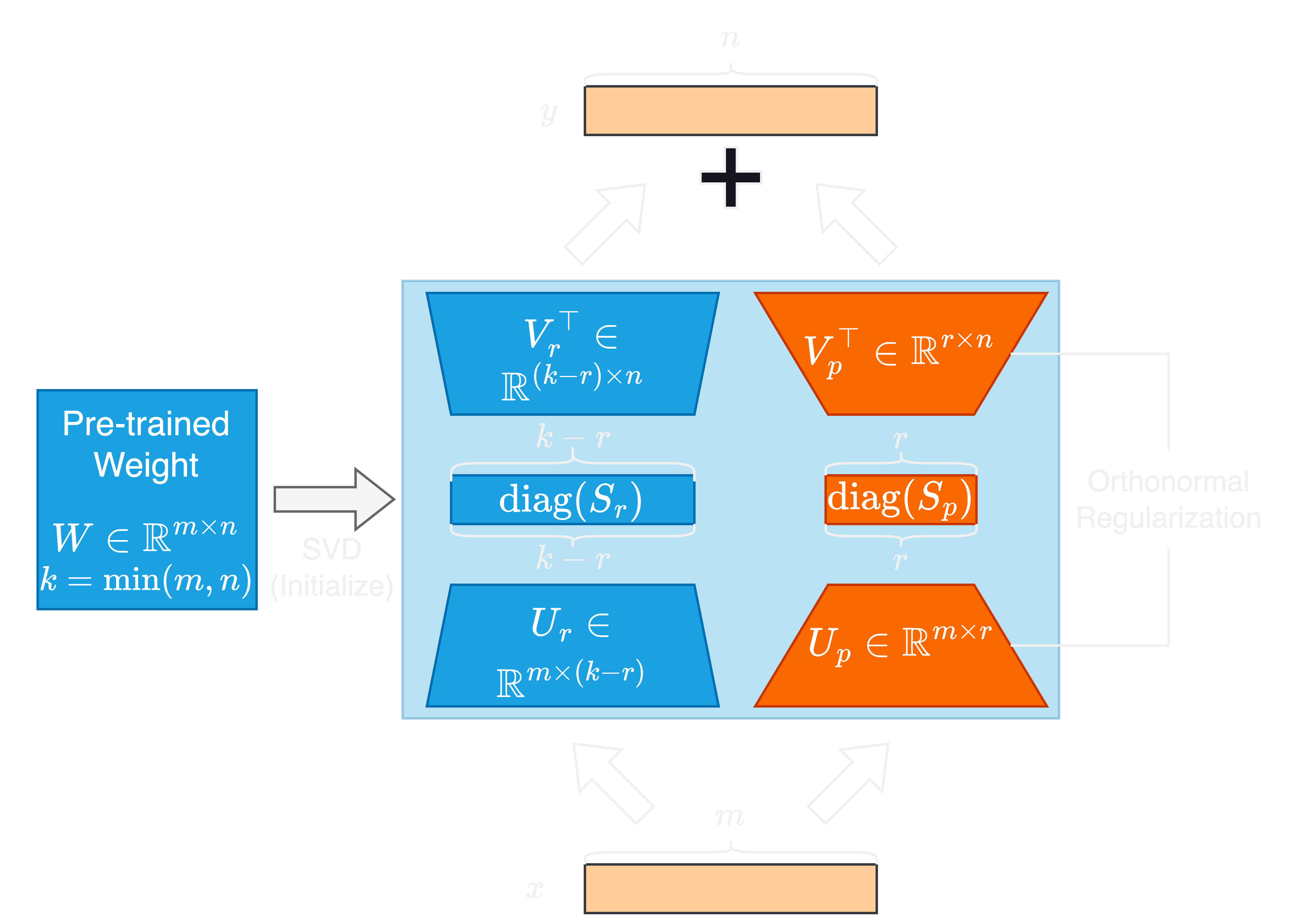
O rápido avanço em grandes modelos de idiomas (LLMS) vem com um aumento significativo no tamanho do parâmetro, apresentando desafios para adaptação e ajuste fino. Os métodos de ajuste fino (PEFT) com eficiência de parâmetro são amplamente utilizados para adaptar os LLMs para tarefas a jusante com eficiência. Neste artigo, propomos valores singulares e adaptação ortomal de vetores singulares regularizados, ou Sorsa, um novo método PEFT. Cada adaptador Sorsa consiste em duas partes principais: pesos singulares principais treináveis
Primeiro, instale o pacote sorsa a partir de Pip:
pip install sorsa Em seguida, crie o arquivo .env no diretório raiz do projeto e adicione seu token de acesso à face abraça:
hf=Your_Hugging_Face_Access_TokenPrimeiro, instale os pacotes via Anaconda
conda env create -f environment.yml Execute scripts de ./scripts/train_sorsa.sh para treinar o modelo.
Após o treinamento, execute o ./scripts/merge_sorsa.sh para mesclar o adaptador ao modelo básico:
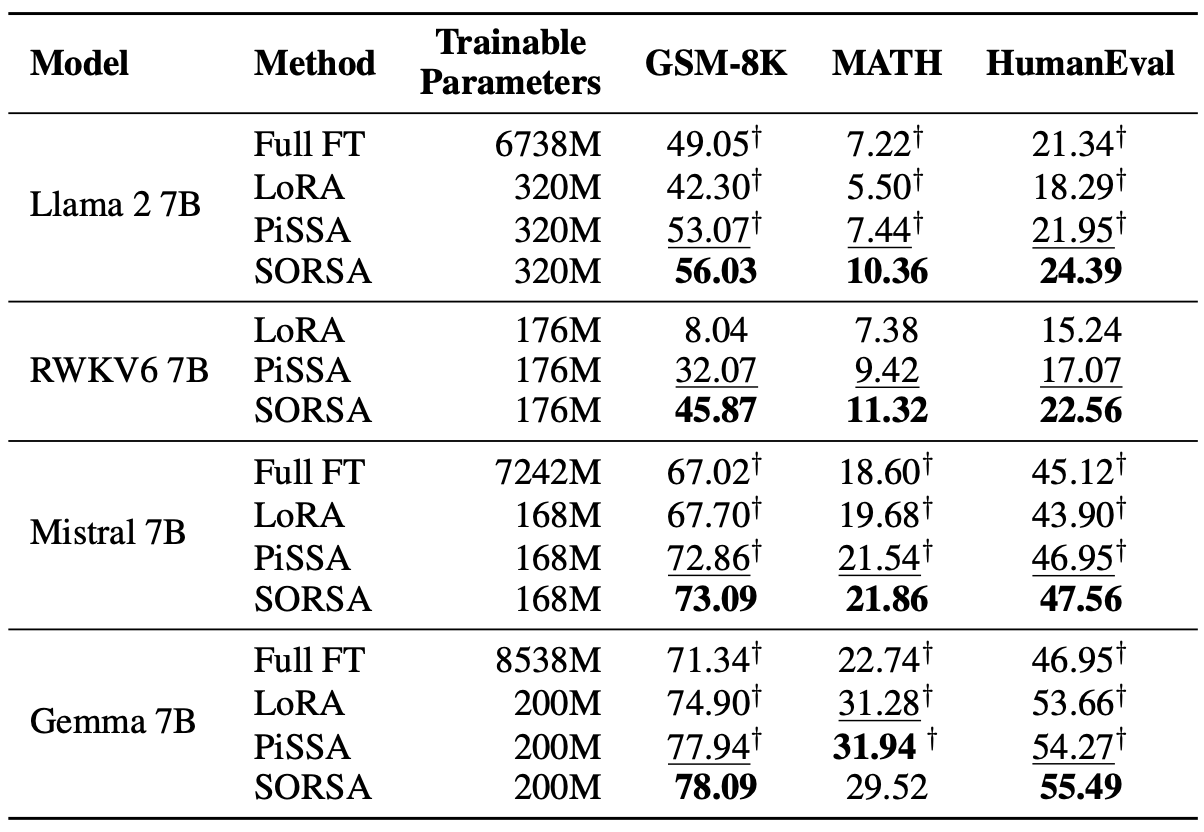
Execute o seguinte comando para avaliar no GSM-8K:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16Execute o seguinte comando para avaliar em matemática:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16Execute o seguinte comando para avaliar no Humaneval:
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 Se você estiver treinando, mesclando ou testando o modelo RWKV6, adicione --rwkv FLAG para run.py
Você pode citar o trabalho usando o código Bibtex da seguinte forma:
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

