SORSA
1.0.1
이 저장소에는 논문 Sorsa의 실험 코드가 포함되어 있습니다 : 단수 값 및 대형 언어 모델의 직교 정규 정규화 된 단수 벡터 적응 .
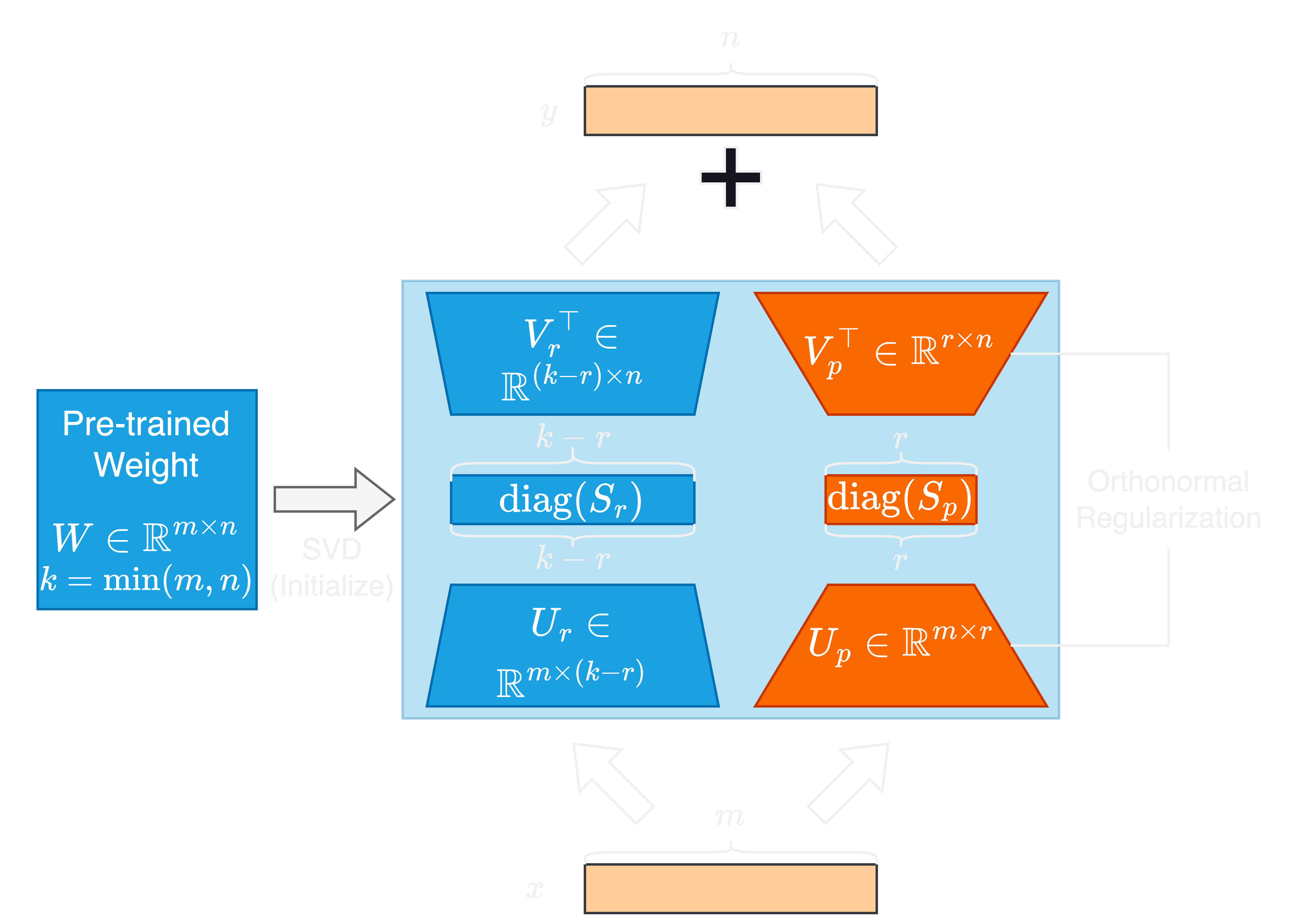
LLMS (Largin Language Model)의 빠른 발전은 매개 변수 크기가 크게 증가하여 적응 및 미세 조정에 대한 과제를 제시합니다. 파라미터 효율적인 미세 조정 (PEFT) 방법은 다운 스트림 작업에 효율적으로 LLM을 적응시키는 데 널리 사용됩니다. 이 논문에서 우리는 단수 값과 직교 정규 정규화 된 단수 벡터 적응 또는 새로운 PEFT 방법 인 Sorsa를 제안합니다. 각 Sorsa 어댑터는 두 가지 주요 부분으로 구성됩니다. 훈련 가능한 주요 단수 중량
먼저 PIP에서 sorsa 패키지를 설치하십시오.
pip install sorsa 그런 다음 프로젝트의 루트 디렉토리에서 .env 파일을 만들고 Hugging Face Access Token을 추가하십시오.
hf=Your_Hugging_Face_Access_Token먼저 Anaconda를 통해 패키지를 설치하십시오
conda env create -f environment.yml 모델을 훈련시키기 위해 ./scripts/train_sorsa.sh 에서 스크립트를 실행하십시오.
훈련 후 ./scripts/merge_sorsa.sh 를 실행하여 어댑터를 기본 모델과 병합하십시오.
GSM-8K에서 평가하려면 다음 명령을 실행하십시오.
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset gsm-8k
--test-precision bf16수학에 대한 평가를 위해 다음 명령을 실행하십시오.
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset math
--test-precision bf16HumaneVal에서 평가하려면 다음 명령을 실행하십시오.
python3 run.py --name llama2_sorsa_r128
--test
--test-dataset humaneval
--test-precision bf16 RWKV6 모델을 교육, 병합 또는 테스트하는 경우 run.py 에 --rwkv 플래그를 추가하십시오.
다음과 같이 Bibtex 코드를 사용하여 작업을 인용 할 수 있습니다.
@article { cao2024sorsa ,
title = { SORSA: Singular Values and Orthonormal Regularized Singular Vectors Adaptation of Large Language Models } ,
author = { Cao, Yang } ,
journal = { arXiv preprint arXiv:2409.00055 } ,
year = { 2024 }
}

