TimeDiffusion
v0.4.1
支持2D(圖像)和3D(視頻)數據作為研究目的的輸入。
pip install timediffusion預測時間序列
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )創建合成時間序列
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )時間序列插補
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )時間序列:多個任務示例
預測比特幣價格示例
定時源模型背後的主要概要是,實際上,在使用時間序列時,我們沒有很多樣本,就像其他機器學習領域一樣(例如CV,NLP)。因此,像Arima這樣的經典自迴旋方法只有在原始序列上擬合 /訓練的最合適方法(也許有一些外源數據)。
定時源是從這些既定方法中汲取靈感,並且僅在輸入樣本上訓練。模型結合了最強大的現代深度學習技術,例如擴散過程,指數擴張的捲積,殘留連接和注意機制(其中一種版本)
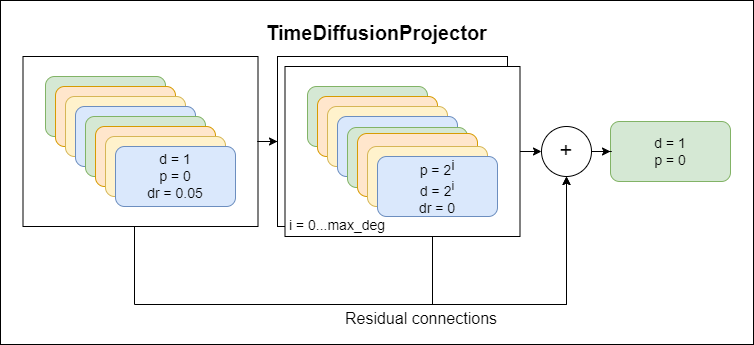
TimeDiffusionProjector - 指數擴張的捲積 +殘差連接。當前使用的主要模型
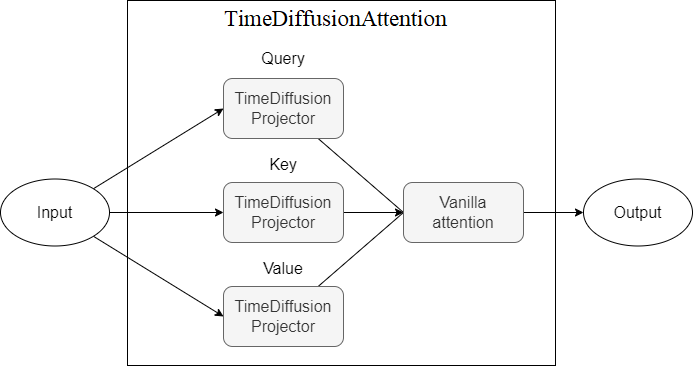
TimeDiffusionAttention - TimeDiffusionProjector (Q,k,v)投影儀的注意機制。目前不可行
TimeDiffusionLiquid指數擴張的捲積,共享中間卷積層的重量。輕巧,快速,但不如主要模型準確。
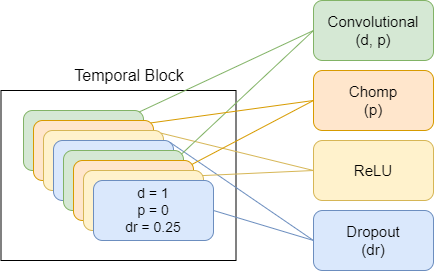
下面介紹的是描述模型組件的圖,每個新方案代表更高水平的抽象。