TimeDiffusion
v0.4.1
Admite datos 2D (imagen) y 3D (video) como entrada para fines de investigación.
pip install timediffusionSerie de tiempo de pronóstico
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )Creación de series de tiempo sintéticas
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )Imputación de series de tiempo
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )Serie de tiempo: ejemplo de múltiples tareas
Pronosticar el precio del precio de bitcoin
La sinopsis principal detrás del modelo Timediffusion es que en realidad, cuando trabajamos con series de tiempo, no tenemos muchas muestras, como podría estar en otros campos de aprendizaje automático (por ejemplo, CV, PNL). Por lo tanto, los enfoques autorregresivos clásicos como ARIMA tienen el enfoque más adecuado de ajuste / entrenamiento solo en secuencia original (tal vez con algunos datos exógenos).
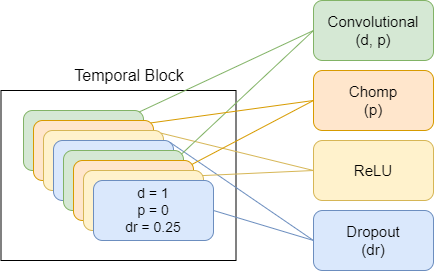
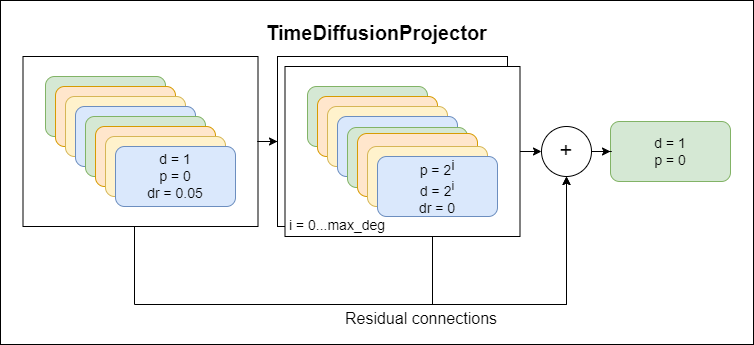
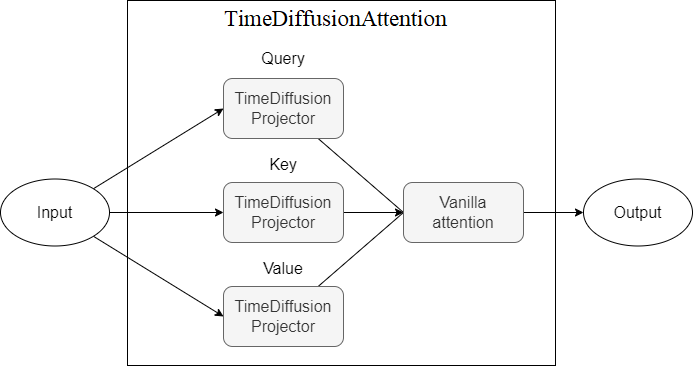
Timedifiusion se inspira en estos métodos establecidos y solo trenes en la muestra de entrada. El modelo incorpora las técnicas de aprendizaje profundo modernos más potentes, como el proceso de difusión, las convoluciones dilatadas exponenciales, las conexiones residuales y el mecanismo de atención (en una de las versiones)
TimeDiffusionProjector - Convoluciones dilatadas exponenciales + conexiones residuales.Actualmente modelo principal en uso
TimeDiffusionAttention - Mecanismo de atención sobre los proyectores TimeDiffusionProjector (Q, K, V).Actualmente no viable
TimeDiffusionLiquid : convoluciones dilatadas exponenciales con peso de capa convolucional media compartida.Ligero, rápido, pero menos preciso que el modelo principal.
A continuación se presentan diagramas que representan componentes del modelo, cada nuevo esquema que representa un mayor nivel de abstracción.