TimeDiffusion
v0.4.1
Suporta dados 2D (imagem) e 3D (vídeo) como entrada para fins de pesquisa.
pip install timediffusionPrevisão de séries temporais
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )Criando séries temporais sintéticas
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )Imputação de séries temporais
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )Série temporal: Exemplo de várias tarefas
Previsão de exemplo de preço de bitcoin
A principal sinopse por trás do modelo Timediffusion é que, na realidade, ao trabalhar com séries temporais, não temos muitas amostras, pois pode estar em outros campos de aprendizado de máquina (por exemplo, CV, NLP). Assim, abordagens autoregressivas clássicas como ARIMA têm a abordagem mais adequada de ajuste / treinamento apenas na sequência original (talvez com alguns dados exógenos).
O timediffusion se inspira nesses métodos estabelecidos e apenas treina na amostra de entrada. O modelo incorpora as mais poderosas técnicas modernas de aprendizado profundo, como processo de difusão, convoluções dilatadas exponenciais, conexões residuais e mecanismo de atenção (em uma das versões)
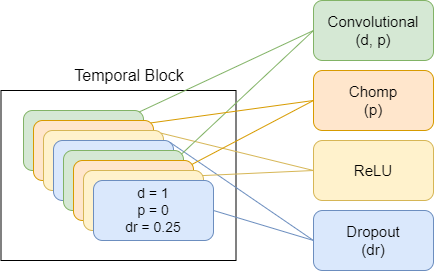
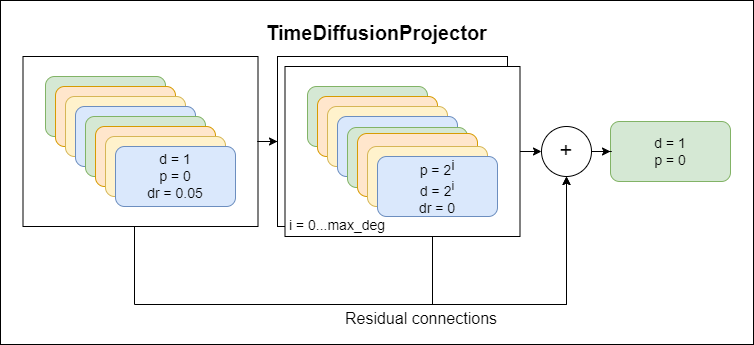
TimeDiffusionProjector - Convidões dilatadas exponenciais + conexões residuais.Atualmente modelo principal em uso
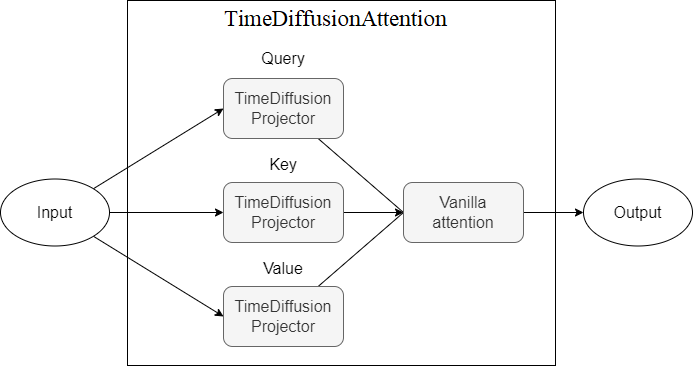
TimeDiffusionAttention - Mecanismo de atenção no topo dos projetores TimeDiffusionProjector (Q, K, V).Atualmente não é viável
TimeDiffusionLiquid - Convidões dilatadas exponenciais com peso da camada convolucional média convolucional compartilhada.Luz, rápido, mas menos preciso que o modelo principal.
A seguir, são apresentados diagramas que representam componentes do modelo, cada novo esquema representando um nível mais alto de abstração.