TimeDiffusion
v0.4.1
รองรับข้อมูล 2D (ภาพ) และ 3D (วิดีโอ) เป็นอินพุตเพื่อวัตถุประสงค์ในการวิจัย
pip install timediffusionชุดเวลาพยากรณ์
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )การสร้างอนุกรมเวลาสังเคราะห์
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )การใส่ชุดเวลา
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )อนุกรมเวลา: ตัวอย่างงานหลายงาน
การพยากรณ์ตัวอย่างราคา bitcoin
บทสรุปหลักที่อยู่เบื้องหลังโมเดล TimeDiffusion คือในความเป็นจริงเมื่อทำงานกับอนุกรมเวลาเราไม่มีตัวอย่างมากมายเพราะอาจเป็นในสาขาการเรียนรู้ของเครื่องอื่น ๆ (เช่น CV, NLP) ดังนั้นวิธีการแบบอัตโนมัติแบบคลาสสิกเช่น ARIMA มีวิธีการที่เหมาะสมที่สุดในการปรับ / ฝึกอบรมเฉพาะในลำดับต้นฉบับ (อาจมีข้อมูลภายนอกบางอย่าง)
TimeDiffusion ใช้แรงบันดาลใจจากวิธีการที่จัดตั้งขึ้นเหล่านี้และรถไฟเฉพาะในตัวอย่างอินพุต แบบจำลองรวมเทคนิคการเรียนรู้ลึกที่ทันสมัยที่สุดเช่นกระบวนการแพร่กระจายการขยายตัวแบบทวีคูณการเชื่อมต่อที่เหลือและกลไกความสนใจ (ในหนึ่งในเวอร์ชัน)
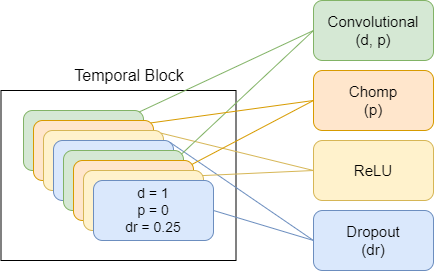
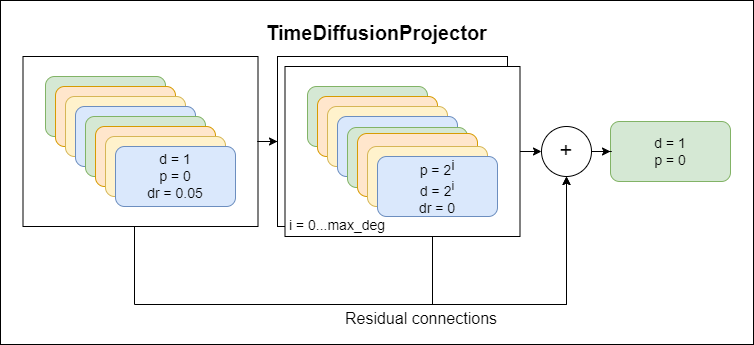
TimeDiffusionProjector - Convolutions ขยายตัวแบบเอ็กซ์โปเนนเชียล + การเชื่อมต่อที่เหลือปัจจุบันรุ่นหลักที่ใช้งานอยู่
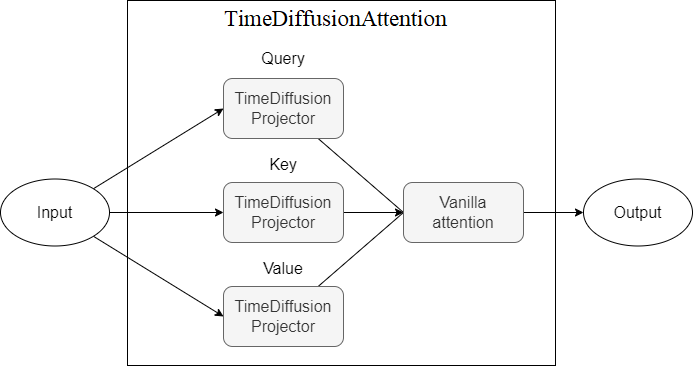
TimeDiffusionAttention - กลไกความสนใจที่ด้านบนของโปรเจคเตอร์ TimeDiffusionProjector (Q, K, V)ปัจจุบันยังไม่สามารถใช้งานได้
TimeDiffusionLiquid - ทวีคูณแบบทวีคูณด้วยน้ำหนักชั้นกลางที่ใช้ร่วมกันน้ำหนักเบาเร็ว แต่แม่นยำน้อยกว่ารุ่นหลัก
ที่นำเสนอด้านล่างนี้คือไดอะแกรมที่แสดงส่วนประกอบของแบบจำลองแต่ละรูปแบบใหม่ที่แสดงถึงระดับที่สูงขึ้นของนามธรรม