TimeDiffusion
v0.4.1
支持2D(图像)和3D(视频)数据作为研究目的的输入。
pip install timediffusion预测时间序列
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )创建合成时间序列
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )时间序列插补
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )时间序列:多个任务示例
预测比特币价格示例
定时源模型背后的主要概要是,实际上,在使用时间序列时,我们没有很多样本,就像其他机器学习领域一样(例如CV,NLP)。因此,像Arima这样的经典自回旋方法只有在原始序列上拟合 /训练的最合适方法(也许有一些外源数据)。
定时源是从这些既定方法中汲取灵感,并且仅在输入样本上训练。模型结合了最强大的现代深度学习技术,例如扩散过程,指数扩张的卷积,残留连接和注意机制(其中一种版本)
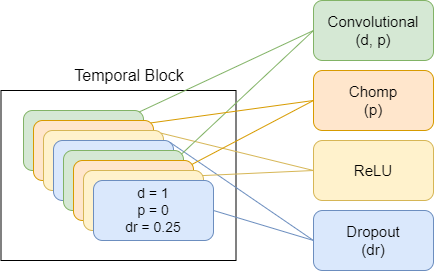
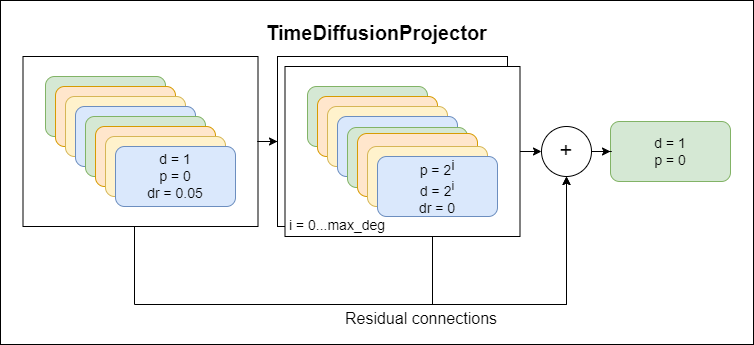
TimeDiffusionProjector - 指数扩张的卷积 +残差连接。当前使用的主要模型
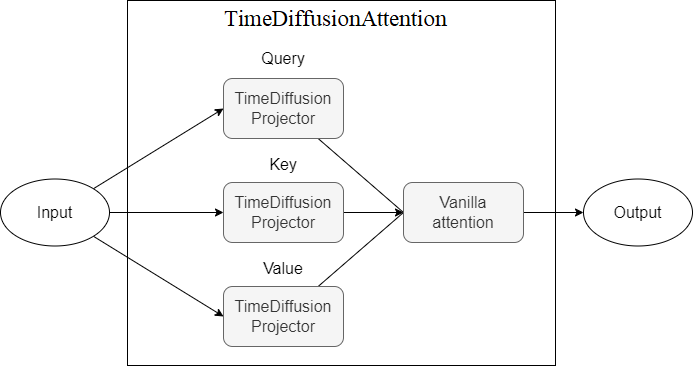
TimeDiffusionAttention - TimeDiffusionProjector (Q,k,v)投影仪的注意机制。目前不可行
TimeDiffusionLiquid指数扩张的卷积,共享中间卷积层的重量。轻巧,快速,但不如主要模型准确。
下面介绍的是描述模型组件的图,每个新方案代表更高水平的抽象。