TimeDiffusion
v0.4.1
Prend en charge les données 2D (image) et 3D (vidéo) en entrée à des fins de recherche.
pip install timediffusionSérie chronologique de prévision
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )Création d'une série chronologique synthétique
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )Imputation de la série chronologique
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )Série chronologique: Exemple de tâches multiples
Exemple de prix du bitcoin de prévision
Le synopsis principal derrière le modèle TimeDiffusion est qu'en réalité, lorsque nous travaillons avec des séries chronologiques, nous n'avons pas beaucoup d'échantillons, comme cela pourrait l'être dans d'autres domaines d'apprentissage automatique (par exemple CV, NLP). Ainsi, les approches autorégressives classiques comme Arima ont l'approche la plus appropriée de l'ajustement / de l'entraînement uniquement sur la séquence originale (peut-être avec certaines données exogènes).
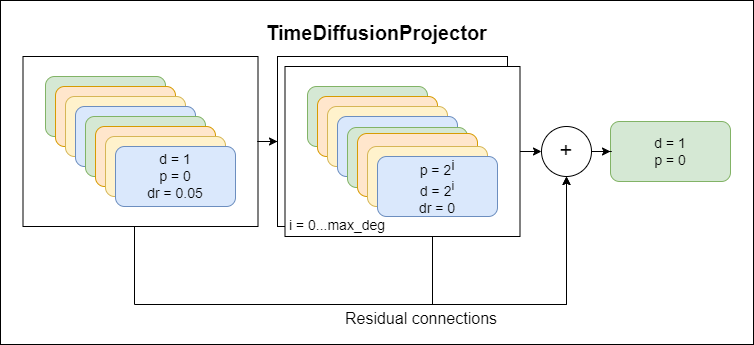
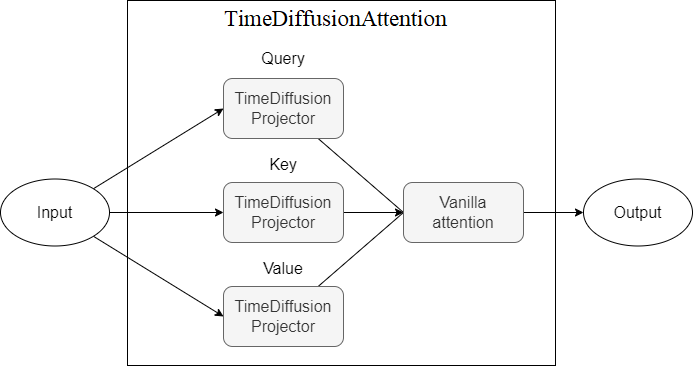
TimeDiffusion s'inspire de ces méthodes établies et s'entraîne uniquement sur l'échantillon d'entrée. Le modèle intègre les techniques d'apprentissage en profondeur modernes les plus puissantes telles que le processus de diffusion, les convolutions exponentielles dilatées, les connexions résiduelles et le mécanisme d'attention (dans l'une des versions)
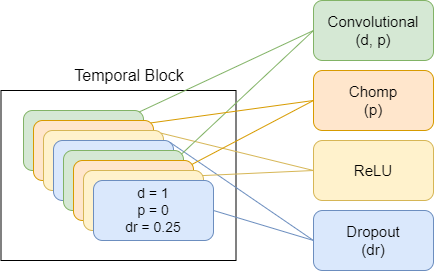
TimeDiffusionProjector - Convolutions exponentielles dilatées + connexions résiduelles.Actuellement principal modèle utilisé
TimeDiffusionAttention - Mécanisme d'attention en plus des projecteurs TimeDiffusionProjector (Q, K, V).Actuellement pas viable
TimeDiffusionLiquid - Convolutions exponentielles dilatées avec un poids de couche convolutionnel moyen partagé.Léger, rapide, mais moins précis que le modèle principal.
Vous trouverez ci-dessous des diagrammes représentant des composants du modèle, chaque nouveau schéma représentant un niveau d'abstraction plus élevé.