TimeDiffusion
v0.4.1
연구 목적을위한 입력으로 2D (이미지) 및 3D (비디오) 데이터를 지원합니다.
pip install timediffusion예측 시계열
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )합성 시계열 생성
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )시계열 대치
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )시계열 : 다중 작업 예제
비트 코인 가격 예측 예측
시간 의식 모델의 주요 시놉시스는 실제로 시계열로 작업 할 때 다른 기계 학습 분야 (예 : CV, NLP)와 마찬가지로 샘플이 많지 않다는 것입니다. 따라서, Arima와 같은 고전적자가 회귀 접근법은 원래 순서 (일부 외인성 데이터와 함께)에만 적합 / 훈련에 가장 적합한 접근 방식을 가지고 있습니다.
시간의 시간은 이러한 확립 된 방법에서 영감을 얻고 입력 샘플에서만 훈련합니다. 모델은 확산 프로세스, 지수 확장 된 컨볼 루션, 잔류 연결 및주의 메커니즘 (버전 중 하나)과 같은 가장 강력한 현대적인 딥 러닝 기술을 통합합니다.
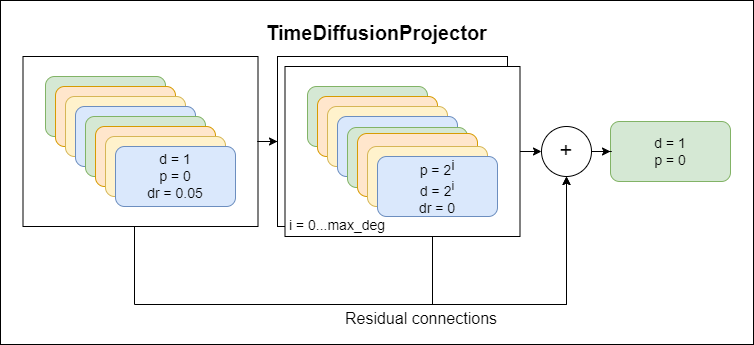
TimeDiffusionProjector 지수 확장 된 컨볼 루션 + 잔류 연결.현재 사용중인 주요 모델입니다
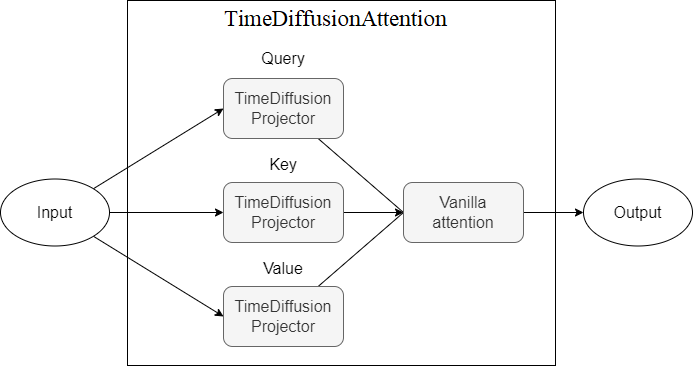
TimeDiffusionAttention TimeDiffusionProjector (Q, K, V) 프로젝터 위에주의 메커니즘.현재 실행 가능하지 않습니다
TimeDiffusionLiquid 공유 중간 컨볼 루션 층 무게를 갖는 지수 확장 된 컨볼 루션.경량, 빠르지 만 기본 모델보다 정확하지 않습니다.
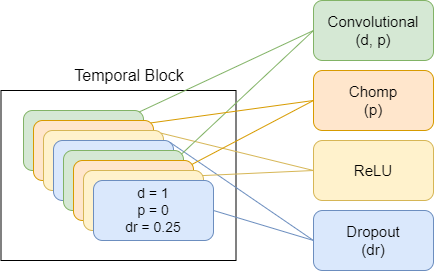
다음은 모델 구성 요소를 묘사 한 다이어그램이며, 각각의 새로운 체계는 더 높은 수준의 추상화를 나타냅니다.