TimeDiffusion
v0.4.1
Unterstützt 2D- (Bild-) und 3D -Daten (Video) als Eingabe für Forschungszwecke.
pip install timediffusionVorhersage von Zeitreihen
# train sequence in shape [channels, sequence_length]
model = TD ( input_dims = train . shape ). to ( device = device )
training_losses = model . fit ( train )
# horizon : int - how many future values to forecast
predictions = model . forecast ( horizon )Erstellen synthetischer Zeitreihen
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
training_losses = model . fit ( seq )
# proximity - how close to original, samples - total synthetic time series
synthetic_data = model . synth ( proximity = 0.9 , samples = 3 , batch_size = 2 , step_granulation = 10 )Zeitreihe Imputation
# sequence in shape [channels, sequence_length]
model = TD ( input_dims = seq . shape ). to ( device = device )
# mask - binary array of same shape, as sequence, with 1 in positions, that are unknown
training_losses = model . fit ( seq , mask = mask )
restored_seq = model . restore ( example = seq , mask = mask )Zeitreihe: Mehrfachaufgaben Beispiel
Vorhersage des Bitcoin -Preisbeispiels
Hauptsynopsis hinter dem Timediffusion -Modell ist, dass wir in der Realität, wenn wir mit Zeitreihen arbeiten, nicht viele Beispiele haben, wie es in anderen maschinellen Lernfeldern sein könnte (z. B. CV, NLP). Daher hat klassische autoregressive Ansätze wie Arima den am besten geeigneten Ansatz für Anpassung / Training nur für die ursprüngliche Sequenz (möglicherweise mit einigen exogenen Daten).
Timediffusion lässt sich von diesen etablierten Methoden inspirieren und nur die Eingabemestifte. Das Modell umfasst die mächtigsten modernen Deep -Lern -Techniken wie Diffusionsprozess, exponentielle erweiterte Konvolutionen, Restverbindungen und Aufmerksamkeitsmechanismus (in einer der Versionen)
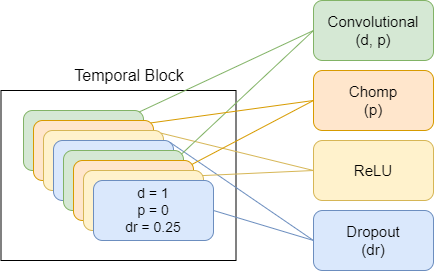
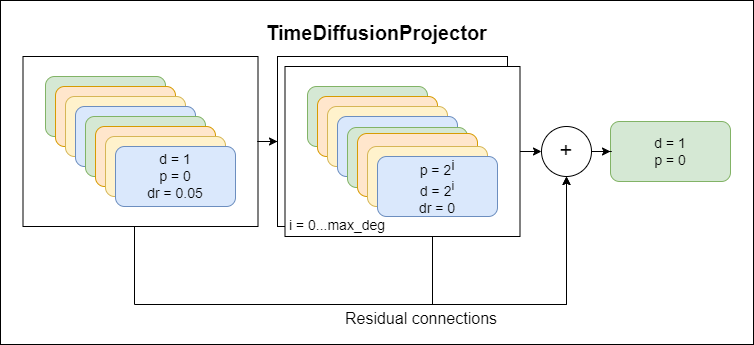
TimeDiffusionProjector - Exponential Dilatatated Convolutions + Restverbindungen.Derzeit verwendete Hauptmodell
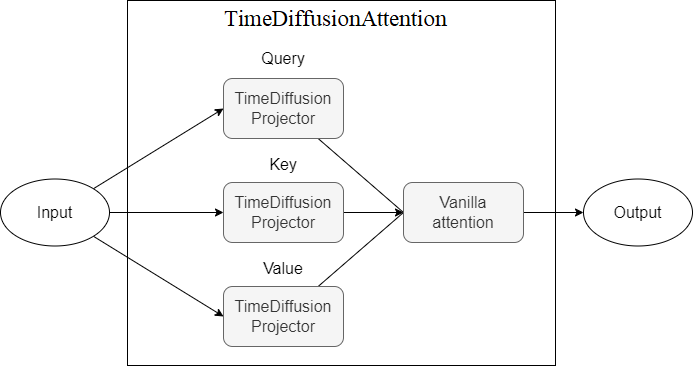
TimeDiffusionAttention - Aufmerksamkeitsmechanismus auf TimeDiffusionProjector (Q, K, V) Projektoren.Derzeit nicht lebensfähig
TimeDiffusionLiquid - Exponentielle erweiterte Konvolutionen mit gemeinsamem Gewicht der mittleren Faltungsschicht.Leicht, schnell, aber weniger genau als das Hauptmodell.
Im Folgenden sind Diagramme dargestellt, die Modellkomponenten darstellen, wobei jedes neue Schema ein höheres Abstraktionsniveau darstellt.