text2speech
1.0.0
?在ICASSP 2023接受
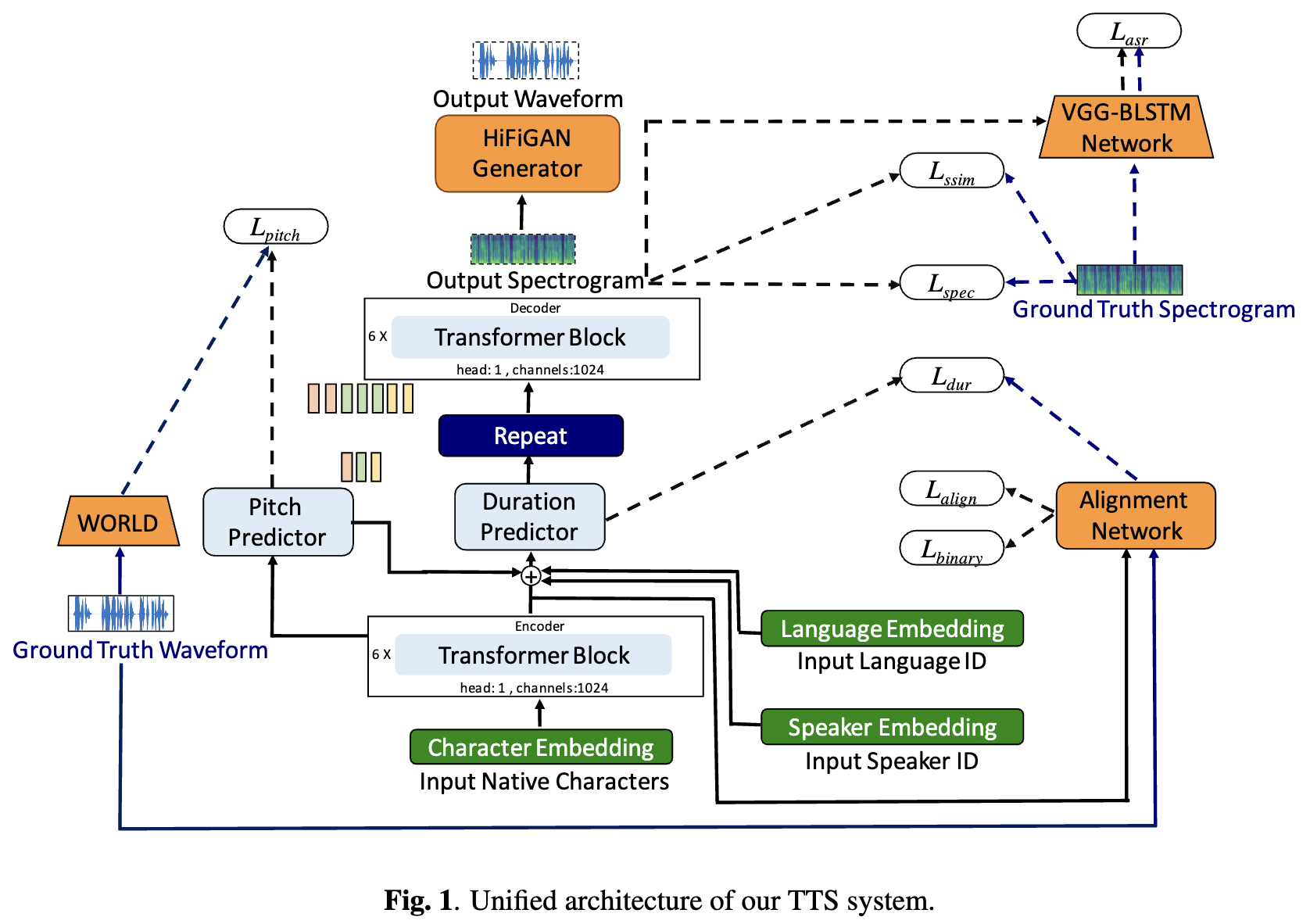
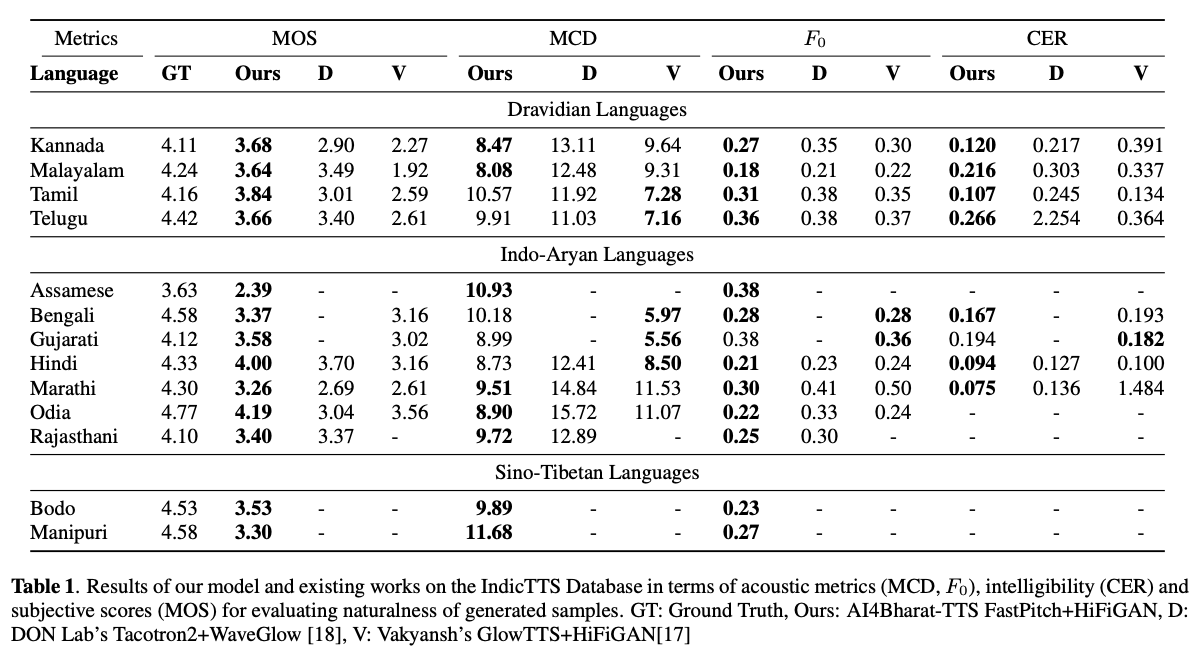
基於深度學習的文本到語音(TTS)系統,隨著模型架構,培訓方法和跨揚聲器和語言的概括的進步,正在迅速發展。但是,這些進步尚未經過徹底研究印度語言言語綜合。鑑於印度語言的數量和多樣性,資源可用性相對較低,並且在未經測試的神經TT中,這種調查在計算上是昂貴的。在本文中,我們評估了德拉維語和印度雅利安語言的聲學模型,聲碼器,補充損失功能,培訓時間表以及說話者和語言多樣性的選擇。基於此,我們通過FastPitch和Hifi-GAN V1確定了單語模型,並對男性和女性揚聲器進行了培訓,以表現最好。通過此設置,我們培訓和評估13種語言的TTS模型,並找到我們的模型,以通過平均意見分數衡量的所有語言中的現有模型顯著改進。我們在Bhashini平台上開放所有型號。
TL; DR:我們開源13種印度語言的SOTA SOTA文本到語音模型: Assamese,Bengali,Bodo,Gujarati,Gujarati,Hindi,Kannada,Kannada,Malayalam,Manipuri,Manipuri,Marathi,Marathi,Odia,Rajasthani,Rajasthani,Temil和Telugu 。
作者: Gokul Karthik Kumar*,Praveen SV*,Pratyush Kumar,Mitesh M. Khapra,Karthik Nandakumar
[arxiv預印度] [音頻樣本] [嘗試實時] [視頻]
# 1. Create environment
sudo apt-get install libsndfile1-dev
conda create -n tts-env
conda activate tts-env
# 2. Setup PyTorch
pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 3. Setup Trainer
git clone https://github.com/gokulkarthik/Trainer
cd Trainer
pip3 install -e .[all]
cd ..
[or]
cp Trainer/trainer/logging/wandb_logger.py to the local Trainer installation # fixed wandb logger
cp Trainer/trainer/trainer.py to the local Trainer installation # fixed model.module.test_log and added code to log epoch
add `gpus = [str(gpu) for gpu in gpus]` in line 53 of trainer/distribute.py
# 4. Setup TTS
git clone https://github.com/gokulkarthik/TTS
cd TTS
pip3 install -e .[all]
cd ..
[or]
cp TTS/TTS/bin/synthesize.py to the local TTS installation # added multiple output support for TTS.bin.synthesis
# 5. Install other requirements
> pip3 install -r requirements.txt
sh run.sh訓練和測試可以在此鏈接上下載經過訓練的模型權重和配置文件。
python3 -m TTS.bin.synthesize --text <TEXT>
--model_path <LANG>/fastpitch/best_model.pth
--config_path <LANG>/config.json
--vocoder_path <LANG>/hifigan/best_model.pth
--vocoder_config_path <LANG>/hifigan/config.json
--out_path <OUT_PATH>
代碼參考:https://github.com/coqui-ai/tts


