text2speech
1.0.0
? Accepté à ICASSP 2023
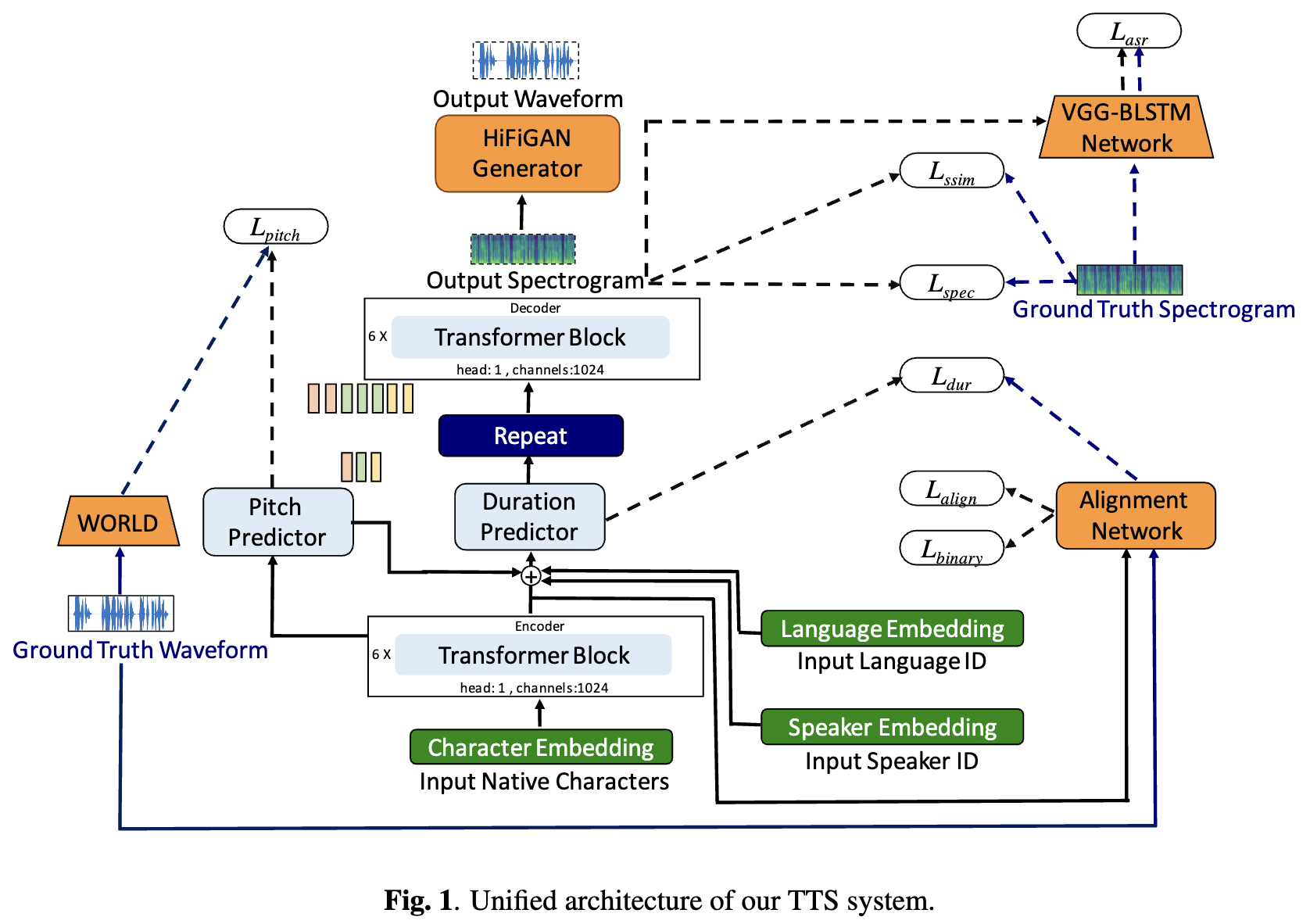
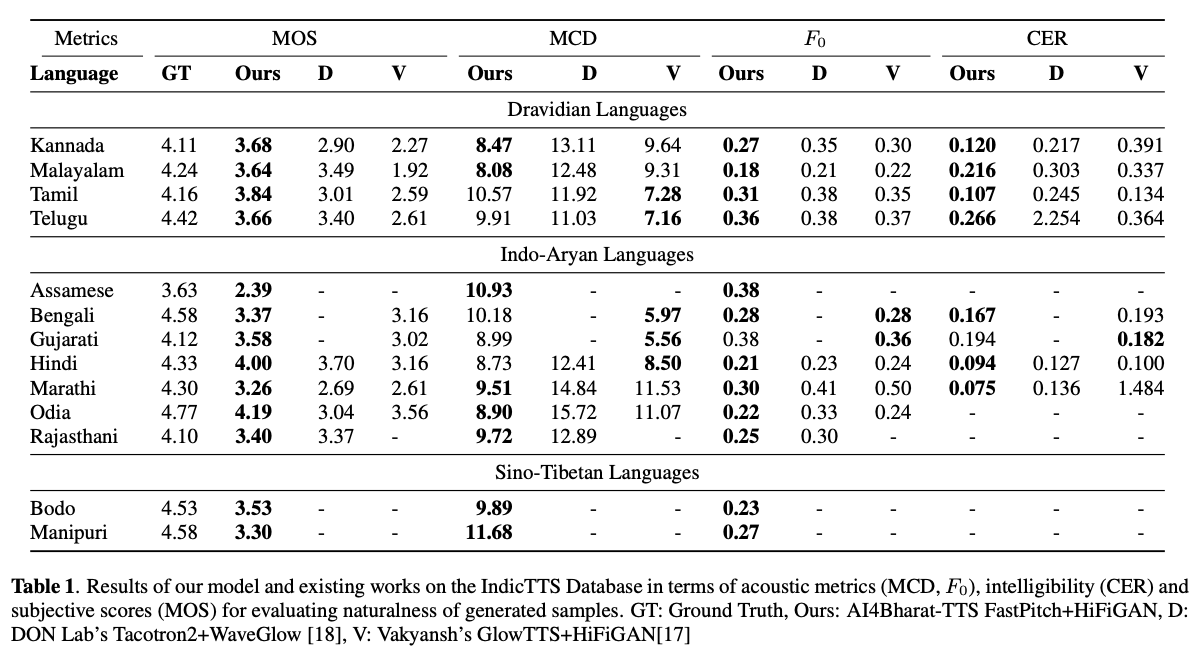
Les systèmes de texte à la fin vocale (TTS) en profondeur ont évolué rapidement avec les progrès des architectures de modèle, des méthodologies de formation et de la généralisation entre les haut-parleurs et les langues. Cependant, ces avancées n'ont pas été étudiées en profondeur pour la synthèse de la parole en langue indienne. Une telle enquête est coûteuse en calcul compte tenu du nombre et de la diversité des langues indiennes, de la disponibilité des ressources relativement plus faible et de l'ensemble diversifié des progrès des TTs neuronaux qui restent non testés. Dans cet article, nous évaluons le choix des modèles acoustiques, des vocodeurs, des fonctions de perte supplémentaire, des horaires de formation et de la diversité des conférenciers et des langues pour les langues dravidiennes et indo-aryennes. Sur la base de cela, nous identifions des modèles monolingues avec FastPitch et Hifi-Gan V1, formés conjointement sur des conférenciers masculins et féminins pour effectuer le meilleur. Avec cette configuration, nous formons et évaluons les modèles TTS pour 13 langues et trouvons nos modèles pour améliorer considérablement les modèles existants dans toutes les langues mesurés par les scores d'opinion moyens. Nous ouverts tous les modèles sur la plate-forme Bhashini.
TL; DR: NOUS OPENSES MODÈLES DE TEXT-TOT-TOT-SPEECH SOTA pour 13 langues indiennes: Assamais, Bengali, Bodo, Gujarati, Hindi, Kannada, Malayalam, Manipuri, Marathi, Odia, Rajasthani, Tamil et Telugu .
Auteurs: Gokul Karthik Kumar *, Praveen Sv *, Pratyush Kumar, Mitesh M. Khapra, Karthik Nandakumar
[ARXIV Préprint] [Échantillons audio] [Essayez-le en direct] [VIDEO]
# 1. Create environment
sudo apt-get install libsndfile1-dev
conda create -n tts-env
conda activate tts-env
# 2. Setup PyTorch
pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 3. Setup Trainer
git clone https://github.com/gokulkarthik/Trainer
cd Trainer
pip3 install -e .[all]
cd ..
[or]
cp Trainer/trainer/logging/wandb_logger.py to the local Trainer installation # fixed wandb logger
cp Trainer/trainer/trainer.py to the local Trainer installation # fixed model.module.test_log and added code to log epoch
add `gpus = [str(gpu) for gpu in gpus]` in line 53 of trainer/distribute.py
# 4. Setup TTS
git clone https://github.com/gokulkarthik/TTS
cd TTS
pip3 install -e .[all]
cd ..
[or]
cp TTS/TTS/bin/synthesize.py to the local TTS installation # added multiple output support for TTS.bin.synthesis
# 5. Install other requirements
> pip3 install -r requirements.txt
sh run.shLes fichiers de poids et de configuration formés peuvent être téléchargés sur ce lien.
python3 -m TTS.bin.synthesize --text <TEXT>
--model_path <LANG>/fastpitch/best_model.pth
--config_path <LANG>/config.json
--vocoder_path <LANG>/hifigan/best_model.pth
--vocoder_config_path <LANG>/hifigan/config.json
--out_path <OUT_PATH>
Référence du code: https://github.com/coqui-ai/tts


