text2speech
1.0.0
? Aceptado en ICASSP 2023
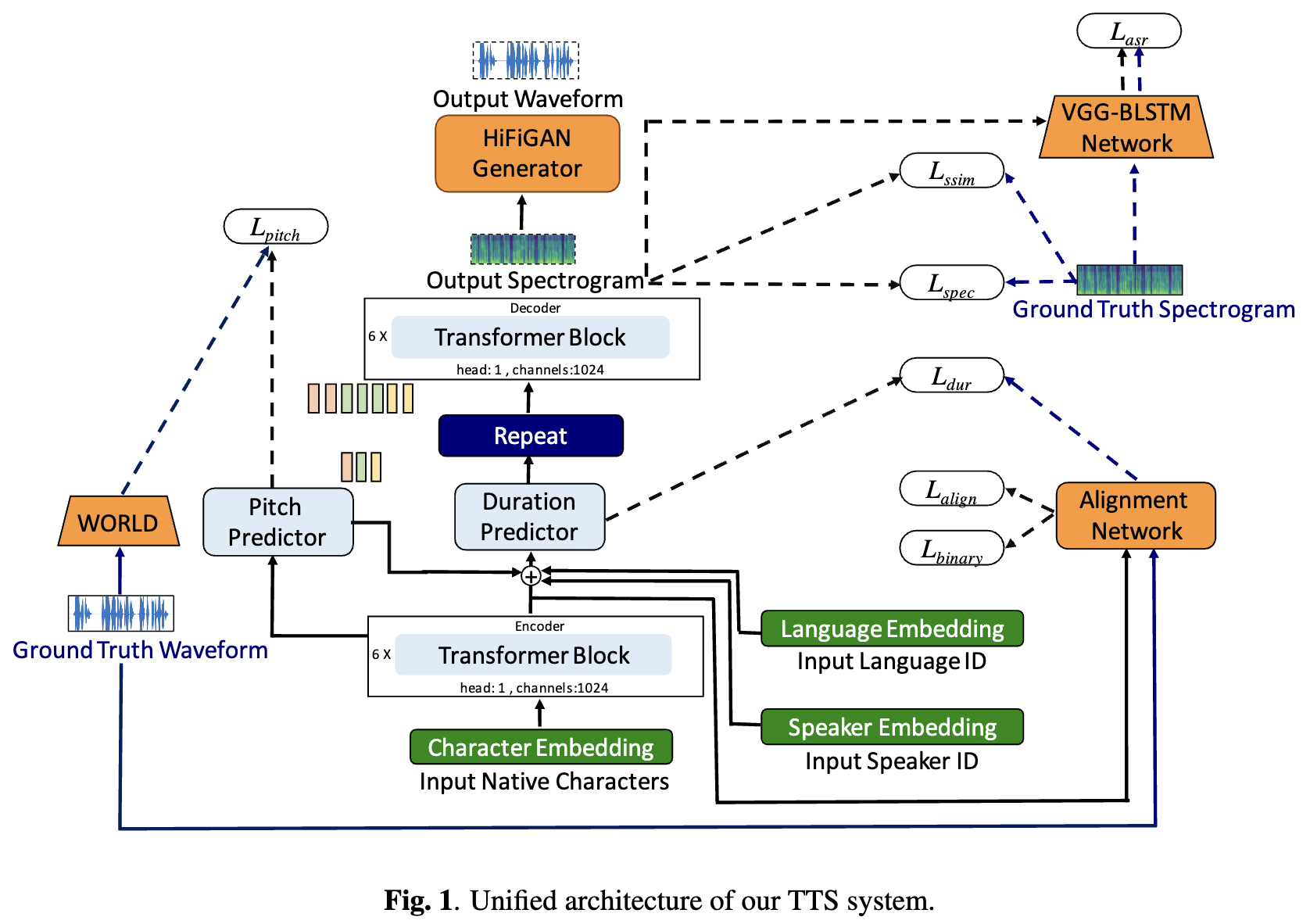
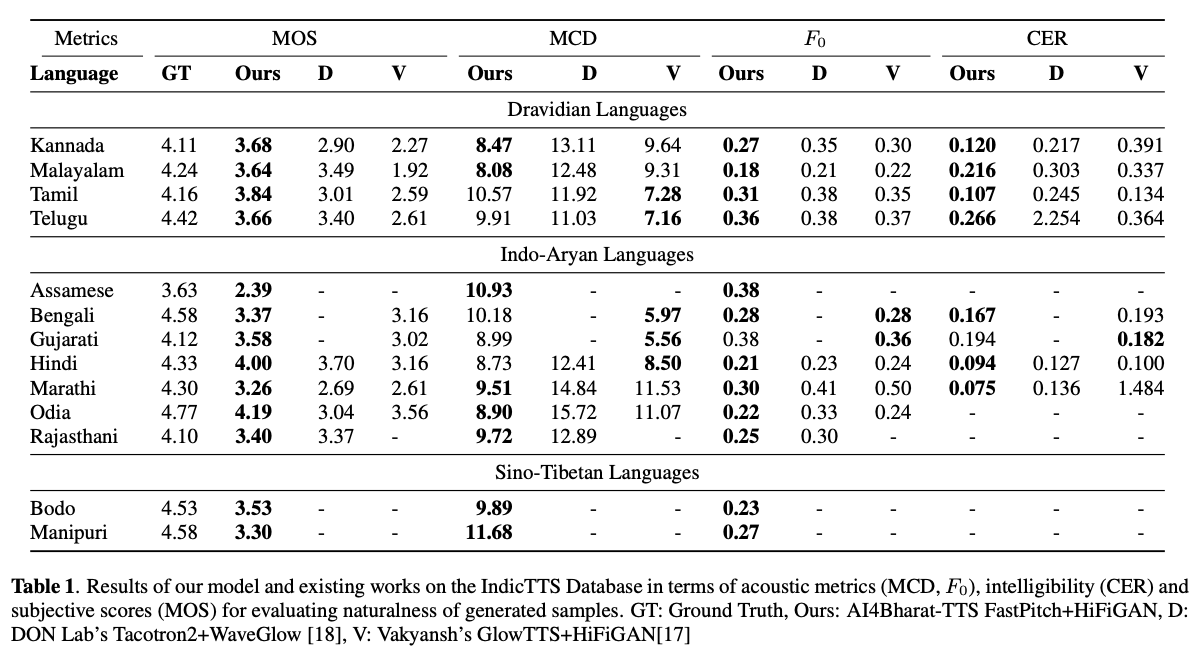
Los sistemas de texto a voz basados en el aprendizaje profundo (TTS) han evolucionado rápidamente con los avances en las arquitecturas de modelos, las metodologías de capacitación y la generalización entre los altavoces y los idiomas. Sin embargo, estos avances no han sido investigados a fondo para la síntesis del habla del idioma indio. Dicha investigación es computacionalmente costosa dado el número y la diversidad de los idiomas indios, la disponibilidad de recursos relativamente más baja y el conjunto diverso de avances en TT neural que permanecen sin probar. En este artículo, evaluamos la elección de modelos acústicos, vocoders, funciones de pérdida complementarias, horarios de capacitación y diversidad de oradores y idiomas para idiomas dravidianos e indo-arios. Según esto, identificamos modelos monolingües con FastPitch y Hifi-Gan V1, entrenados conjuntamente en altavoces masculinos y femeninos para que funcionen mejor. Con esta configuración, capacitamos y evaluamos los modelos TTS para 13 idiomas y encontramos que nuestros modelos mejoran significativamente los modelos existentes en todos los idiomas medidos por las puntuaciones medias de opinión. De código abierto todos los modelos en la plataforma Bhashini.
TL; DR: Modelos de texto a voz de código abierto para 13 idiomas indios: asamés, bengalí, bodo, gujarati, hindi, kannada, malayalam, manipuri, marathi, odia, rajasthani, tamil y telugu .
Autores: Gokul Karthik Kumar*, Praveen SV*, Pratyush Kumar, Mitesh M. Khapra, Karthik Nandakumar
[Preprint] [muestras de audio] [Pruébalo en vivo] [Video]
# 1. Create environment
sudo apt-get install libsndfile1-dev
conda create -n tts-env
conda activate tts-env
# 2. Setup PyTorch
pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 3. Setup Trainer
git clone https://github.com/gokulkarthik/Trainer
cd Trainer
pip3 install -e .[all]
cd ..
[or]
cp Trainer/trainer/logging/wandb_logger.py to the local Trainer installation # fixed wandb logger
cp Trainer/trainer/trainer.py to the local Trainer installation # fixed model.module.test_log and added code to log epoch
add `gpus = [str(gpu) for gpu in gpus]` in line 53 of trainer/distribute.py
# 4. Setup TTS
git clone https://github.com/gokulkarthik/TTS
cd TTS
pip3 install -e .[all]
cd ..
[or]
cp TTS/TTS/bin/synthesize.py to the local TTS installation # added multiple output support for TTS.bin.synthesis
# 5. Install other requirements
> pip3 install -r requirements.txt
sh run.shLos archivos de peso y de configuración de modelo capacitado se pueden descargar en este enlace.
python3 -m TTS.bin.synthesize --text <TEXT>
--model_path <LANG>/fastpitch/best_model.pth
--config_path <LANG>/config.json
--vocoder_path <LANG>/hifigan/best_model.pth
--vocoder_config_path <LANG>/hifigan/config.json
--out_path <OUT_PATH>
Referencia de código: https://github.com/coqui-ai/tts


