text2speech
1.0.0
? Auf ICASSP 2023 akzeptiert
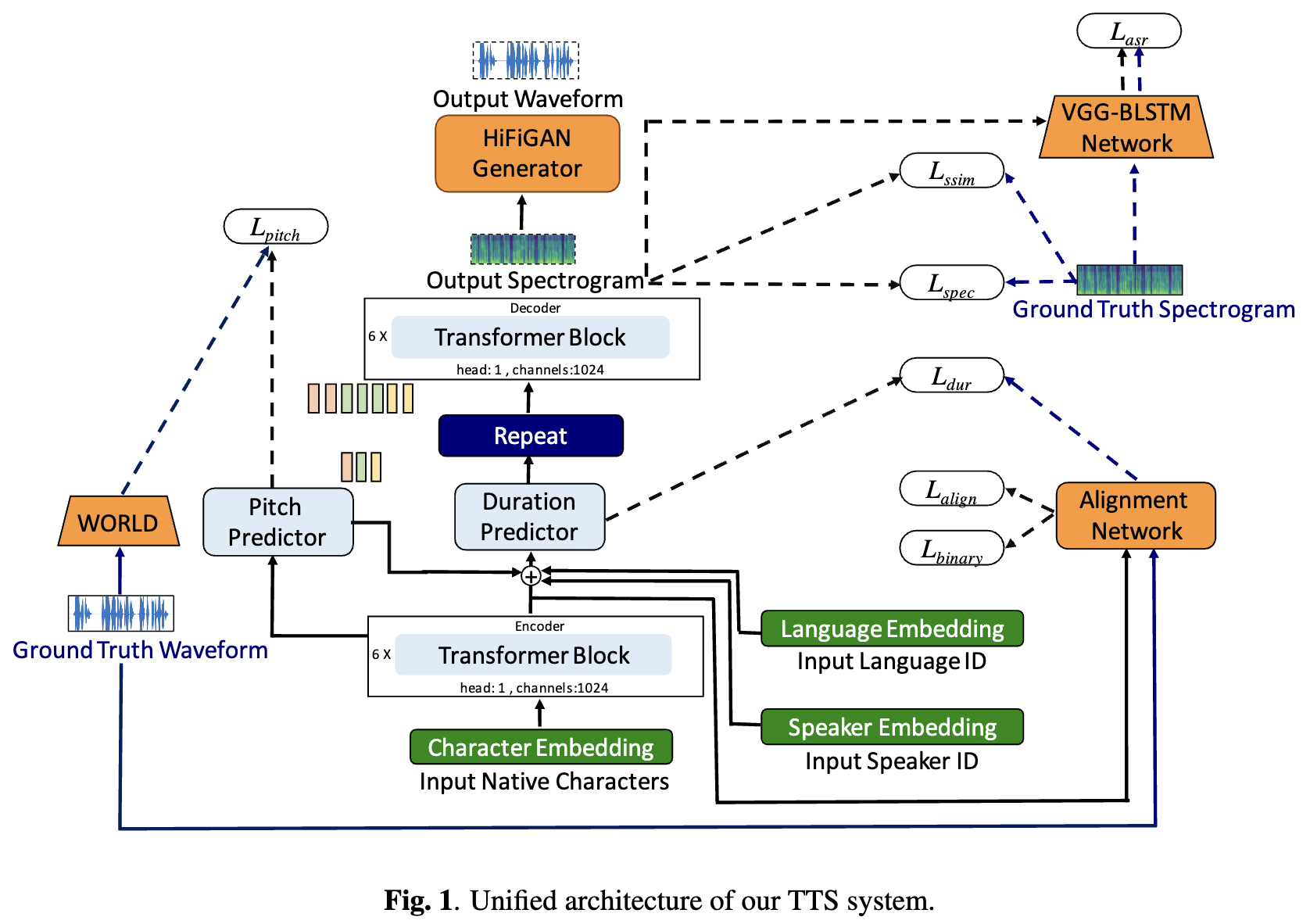
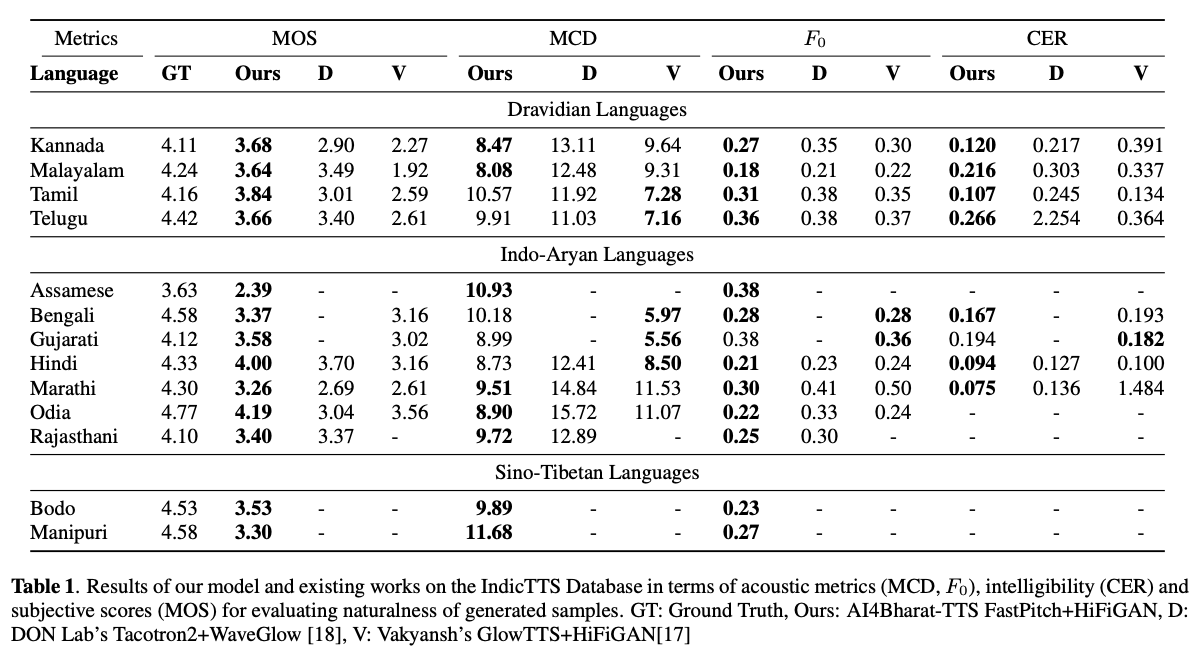
TTS-Systeme (Deep Learning Based Text-to Speech) haben sich mit Fortschritten in Modellarchitekturen, Trainingsmethoden und Verallgemeinerungen zwischen Sprechern und Sprachen rasch entwickelt. Diese Fortschritte wurden jedoch nicht gründlich für die indische Sprachsynthese untersucht. Eine solche Untersuchung ist aufgrund der Anzahl und Vielfalt indischer Sprachen, der relativ geringeren Verfügbarkeit von Ressourcen und der unterschiedlichen Fortschritte in neuronalen TTs, die nicht getestet bleiben, rechnerisch teuer. In diesem Artikel bewerten wir die Auswahl von Akustikmodellen, Vocoders, ergänzenden Verlustfunktionen, Schulungsplänen sowie Sprecher und Sprachvielfalt für dravidische und indo-arische Sprachen. Basierend darauf identifizieren wir einsprachige Modelle mit Fastpitch und Hifi -gan V1, die gemeinsam auf männliche und weibliche Lautsprecher ausgebildet wurden, um das Beste zu erreichen. Mit diesem Setup trainieren und bewerten wir TTS -Modelle für 13 Sprachen und finden unsere Modelle, um vorhandene Modelle in allen Sprachen, gemessen anhand der mittleren Meinungsbewertungen, erheblich zu verbessern. Wir haben alle Modelle auf der Bhashini-Plattform offen.
TL; DR: Wir Open-Source Sota Text-to-Speech-Modelle für 13 indische Sprachen: Assamesen, Bengali, Bodo, Gujarati, Hindi, Kannada, Malayalam, Manipuri, Marathi, Odia, Rajasthani, Tamil und Telugu .
Autoren: Gokul Karthik Kumar*, Praveen Sv*, Pratyush Kumar, Mitesh M. Khapra, Karthik Nandakumar
[Arxiv Preprint] [Audio -Beispiele] [Probieren Sie es live] [Video]
# 1. Create environment
sudo apt-get install libsndfile1-dev
conda create -n tts-env
conda activate tts-env
# 2. Setup PyTorch
pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 3. Setup Trainer
git clone https://github.com/gokulkarthik/Trainer
cd Trainer
pip3 install -e .[all]
cd ..
[or]
cp Trainer/trainer/logging/wandb_logger.py to the local Trainer installation # fixed wandb logger
cp Trainer/trainer/trainer.py to the local Trainer installation # fixed model.module.test_log and added code to log epoch
add `gpus = [str(gpu) for gpu in gpus]` in line 53 of trainer/distribute.py
# 4. Setup TTS
git clone https://github.com/gokulkarthik/TTS
cd TTS
pip3 install -e .[all]
cd ..
[or]
cp TTS/TTS/bin/synthesize.py to the local TTS installation # added multiple output support for TTS.bin.synthesis
# 5. Install other requirements
> pip3 install -r requirements.txt
sh run.shDas geschultes Modellgewicht und Konfigurationsdateien können unter diesem Link heruntergeladen werden.
python3 -m TTS.bin.synthesize --text <TEXT>
--model_path <LANG>/fastpitch/best_model.pth
--config_path <LANG>/config.json
--vocoder_path <LANG>/hifigan/best_model.pth
--vocoder_config_path <LANG>/hifigan/config.json
--out_path <OUT_PATH>
Codereferenz: https://github.com/coqui-ai/tts


