pytorch lr finder
v0.2.2

Leslie N. Smith和Fastai使用的調整版本的培訓神經網絡的周期性學習率中詳細詳細介紹了學習率範圍測試的Pytorch實施。
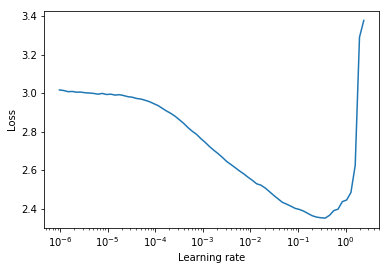
學習率範圍測試是一項測試,可提供有關最佳學習率的有價值信息。在訓練前的運行中,學習率在兩個邊界之間線性或指數呈線性提高。低初始學習率使網絡可以開始融合,並且隨著學習率的提高,最終將太大,網絡將會差異。
通常,可以在下降損失曲線中途找到良好的靜態學習率。在下面的圖中,該圖為lr = 0.002 。
對於週期性的學習率(也在萊斯利·史密斯(Leslie Smith)的論文中詳細介紹),其中學習率在兩個邊界之間循環(start_lr, end_lr) ,作者建議損失開始下降的地步,而損失停止下降或在start_lr和end_lr中逐漸降低。在下面的圖中, start_lr = 0.0002和end_lr=0.2 。
Python 3.5及以上:
pip install torch-lr-finder在混合精確培訓的支持下安裝(另請參見本節):
pip install torch-lr-finder -v --global-option= " apex " 以指數級的方式提高學習率,併計算每個學習率的訓練損失。 lr_finder.plot()繪製訓練損失與對數學習率。
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state線性提高學習率,併計算每個學習率的評估損失。 lr_finder.plot()繪製評估損失與學習率。這種方法通常會產生更精確的曲線,因為評估損失更容易發散,但是執行測試需要更長的時間,尤其是在評估數據集很大的情況下。
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder不應附上LRScheduler 。LRFinder.range_test()將更改模型權重和優化器參數。兩者都可以使用LRFinder.reset()恢復到其初始狀態。lr_finder.history訪問學習率和損失歷史。這將返回使用lr和loss鍵的字典。step_mode="linear"時,學習率範圍應在相同的數量級內。LRFinder.range_test()期望一對input, label從傳遞給它的DataLoader器對象返回。必須準備將input傳遞給模型,並且必須準備將label傳遞給criterion ,而無需任何進一步的數據處理/處理/轉換。如果您發現自己需要解決方法,則可以利用TrainDataLoaderIter和ValDataLoaderIter的類,在DataLoader和培訓/評估循環之間執行任何數據處理/處理/轉換。您可以找到一個如何在示例中使用這些類的示例/lrfinder_cifar10_dataloader_iter。 您可以在LRFinder.range_test()中設置accumulation_steps參數,具有適當的值以執行梯度累積:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset ()apex.amp和torch.amp現在得到支持,以下是:
使用apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()使用torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()請注意,混合精度訓練的好處需要帶有張量芯的NVIDIA GPU(另請參見:NVIDIA/APEX#297)
此外,您可以嘗試設置torch.backends.cudnn.benchmark = True以提高訓練速度。 (但是在某些情況下它不起作用,您應該自擔風險)
歡迎所有貢獻,但首先,看看貢獻。 md。


