pytorch lr finder
v0.2.2

Реализация Pytorch тестирования диапазона обучения, подробно описанную в циклических показателях обучения для обучения нейронных сетей Лесли Н. Смита, и настроенная версия, используемая FASTAI.
Тест диапазона обучения - это тест, который предоставляет ценную информацию об оптимальной скорости обучения. Во время предварительного обучения скорость обучения увеличивается линейно или экспоненциально между двумя границами. Низкая начальная скорость обучения позволяет сети начинать сходиться, и по мере увеличения скорости обучения он в конечном итоге будет слишком большой, а сеть будет расходиться.
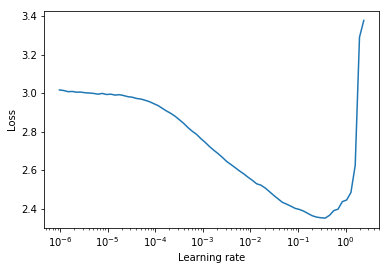
Как правило, хорошую статическую скорость обучения можно найти на полпути на кривой нисходящих потерь. На участке ниже это будет lr = 0.002 .
Для циклических показателей обучения (также подробно описанного в статье Лесли Смита), где скорость обучения циклевой цикл между двумя границами (start_lr, end_lr) , автор консультирует точку, в которой потеря начинает спускаться, и точка, в которой потеря перестает спускаться или становится рваной для start_lr и end_lr соответственно. На указанном ниже графике start_lr = 0.0002 и end_lr=0.2 .
Python 3.5 и выше:
pip install torch-lr-finderУстановите при поддержке смешанной точной тренировки (см. Также этот раздел):
pip install torch-lr-finder -v --global-option= " apex " Увеличивает скорость обучения экспоненциальным образом и вычисляет потери обучения для каждого уровня обучения. lr_finder.plot() определяет потерю обучения по сравнению с логарифмическим уровнем обучения.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state Увеличивает скорость обучения линейно и вычисляет потери оценки для каждой скорости обучения. lr_finder.plot() определяет потерю оценки в зависимости от скорости обучения. Этот подход обычно создает более точные кривые, потому что потеря оценки более подвержена дивергенции, но для выполнения теста требуется значительно больше времени, особенно если набор данных оценки велик.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder , не должен иметь к нему прикреплен LRScheduler .LRFinder.range_test() изменит веса модели и параметры оптимизатора. Оба могут быть восстановлены в их начальном состоянии с LRFinder.reset() .lr_finder.history . Это вернет словарь с lr и ключами loss .step_mode="linear" диапазон обучения должен находиться в пределах одного и того же порядка.LRFinder.range_test() ожидает, что пара input, label будет возвращена из объектов DataLoader , передаваемых к нему. input должен быть готов к передаче в модель, и label должна быть готова к передаче в criterion без дальнейшей обработки/обработки/обработки данных/преобразования. Если вам нужен обходной путь, вы можете использовать классы TrainDataLoaderIter и ValDataLoaderIter для выполнения любой обработки/обработки данных/обработки/преобразования между DataLoader и петлей обучения/оценки. Вы можете найти пример того, как использовать эти классы в примерах/lrfinder_cifar10_dataloader_iter. Вы можете установить параметр accumulation_steps в LRFinder.range_test() с правильным значением для выполнения накопления градиента:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset () И apex.amp , и torch.amp поддерживаются сейчас, вот примеры:
Используя apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset () Используя torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()Обратите внимание, что преимущество смешанной точной тренировки требует графического процессора NVIDIA с тензорными ядрами (см. Также: NVIDIA/APEX #297)
Кроме того, вы можете попытаться установить torch.backends.cudnn.benchmark = True чтобы улучшить скорость обучения. (Но это не сработает для некоторых случаев, вы должны использовать его на свой страх и риск)
Все взносы приветствуются, но сначала посмотрите на Appling.md.


