pytorch lr finder
v0.2.2

Leslie N. Smith의 신경망을 훈련하기위한 주기적 학습 속도와 FASTAI가 사용하는 조정 된 버전에 대한주기 학습 속도에 상세한 학습 속도 범위 테스트의 Pytorch 구현.
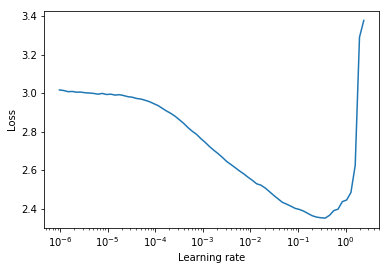
학습 속도 범위 테스트는 최적의 학습 속도에 대한 귀중한 정보를 제공하는 테스트입니다. 사전 훈련 실행 중에 학습 속도는 두 경계 사이에서 선형 또는 기하 급수적으로 증가합니다. 초기 학습 속도가 낮기 때문에 네트워크가 수렴을 시작하고 학습 속도가 높아짐에 따라 결국에는 너무 커지고 네트워크가 분기됩니다.
일반적으로 내림차순 손실 곡선에서 반쯤 좋은 정적 학습 속도를 찾을 수 있습니다. 아래 플롯에서는 lr = 0.002 입니다.
학습 속도가 두 경계 (start_lr, end_lr) 사이에 순환되는주기 학습 속도 (Leslie Smith의 논문에도 자세히 설명되어 있음)의 경우, 저자는 손실이 내림차순을 시작하는 지점과 손실이 각각 start_lr 및 end_lr 에 대해 손실이 내림차순을 멈추거나 격렬한 지점을 조언합니다. 아래 플롯에서 start_lr = 0.0002 및 end_lr=0.2 .
파이썬 3.5 이상 :
pip install torch-lr-finder혼합 정밀 훈련을 지원하여 설치합니다 (이 섹션 참조) :
pip install torch-lr-finder -v --global-option= " apex " 학습 속도를 기하 급수적으로 증가시키고 각 학습 속도에 대한 교육 손실을 계산합니다. lr_finder.plot() 훈련 손실과 로그 학습 속도를 플롯합니다.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state 학습 속도를 선형으로 증가시키고 각 학습 속도에 대한 평가 손실을 계산합니다. lr_finder.plot() 평가 손실과 학습 속도를 도표로 표시합니다. 이 접근법은 일반적으로 평가 손실이 발산에 더 취약하지만 특히 평가 데이터 세트가 큰 경우 테스트를 수행하는 데 훨씬 더 오래 걸리기 때문에 일반적으로 더 정확한 곡선을 생성합니다.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder 로 전달 된 Optimizer에는 LRScheduler 부착되어 있지 않아야합니다.LRFinder.range_test() 모델 가중치와 Optimizer 매개 변수를 변경합니다. 둘 다 LRFinder.reset() 로 초기 상태로 복원 할 수 있습니다.lr_finder.history 를 통해 액세스 할 수 있습니다. lr 및 loss 키가있는 사전을 반환합니다.step_mode="linear" 사용하는 경우 학습 속도 범위는 동일한 순서 내에 있어야합니다.LRFinder.range_test() 한 쌍의 input, label DataLoader 객체에서 반환 될 것으로 예상합니다. input 모델로 전달할 준비가되어 있어야하며 더 이상의 데이터 처리/처리/변환없이 label criterion 으로 전달할 준비가되어 있어야합니다. 해결 방법이 필요한 경우 DataLoader 와 Training/Evaluation Loop 사이의 데이터 처리/처리/변환을 수행하기 위해 TrainDataLoaderIter 및 ValDataLoaderIter 클래스를 사용하여 클래스를 사용할 수 있습니다. 예제/lrfinder_cifar10_dataloader_iter에서 이러한 클래스를 사용하는 방법의 예를 찾을 수 있습니다. Gradient 축적을 수행하기 위해 적절한 값으로 LRFinder.range_test() 에서 accumulation_steps 매개 변수를 설정할 수 있습니다.
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset () apex.amp 와 torch.amp 이제 모두 지원됩니다. 예는 다음과 같습니다.
apex.amp 사용 :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset () torch.amp 사용
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()혼합 정밀 훈련의 이점에는 텐서 코어가있는 NVIDIA GPU가 필요합니다 (NVIDIA/APEX #297 참조).
게다가, 당신은 torch.backends.cudnn.benchmark = True 설정하려고 시도 할 수 있습니다. (그러나 어떤 경우에는 효과가 없으며 자신의 위험에 따라 사용해야합니다).
모든 기부금은 환영하지만 먼저 기여를 살펴보십시오 .md.


