pytorch lr finder
v0.2.2

Leslie N. Smith和Fastai使用的调整版本的培训神经网络的周期性学习率中详细详细介绍了学习率范围测试的Pytorch实施。
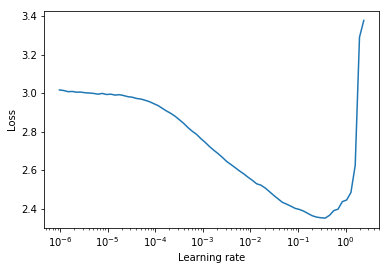
学习率范围测试是一项测试,可提供有关最佳学习率的有价值信息。在训练前的运行中,学习率在两个边界之间线性或指数呈线性提高。低初始学习率使网络可以开始融合,并且随着学习率的提高,最终将太大,网络将会差异。
通常,可以在下降损失曲线中途找到良好的静态学习率。在下面的图中,该图为lr = 0.002 。
对于周期性的学习率(也在莱斯利·史密斯(Leslie Smith)的论文中详细介绍),其中学习率在两个边界之间循环(start_lr, end_lr) ,作者建议损失开始下降的地步,而损失停止下降或在start_lr和end_lr中逐渐降低。在下面的图中, start_lr = 0.0002和end_lr=0.2 。
Python 3.5及以上:
pip install torch-lr-finder在混合精确培训的支持下安装(另请参见本节):
pip install torch-lr-finder -v --global-option= " apex " 以指数级的方式提高学习率,并计算每个学习率的训练损失。 lr_finder.plot()绘制训练损失与对数学习率。
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state线性提高学习率,并计算每个学习率的评估损失。 lr_finder.plot()绘制评估损失与学习率。这种方法通常会产生更精确的曲线,因为评估损失更容易发散,但是执行测试需要更长的时间,尤其是在评估数据集很大的情况下。
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder不应附上LRScheduler 。LRFinder.range_test()将更改模型权重和优化器参数。两者都可以使用LRFinder.reset()恢复到其初始状态。lr_finder.history访问学习率和损失历史。这将返回使用lr和loss键的字典。step_mode="linear"时,学习率范围应在相同的数量级内。LRFinder.range_test()期望一对input, label从传递给它的DataLoader器对象返回。必须准备将input传递给模型,并且必须准备将label传递给criterion ,而无需任何进一步的数据处理/处理/转换。如果您发现自己需要解决方法,则可以利用TrainDataLoaderIter和ValDataLoaderIter的类,在DataLoader和培训/评估循环之间执行任何数据处理/处理/转换。您可以找到一个如何在示例中使用这些类的示例/lrfinder_cifar10_dataloader_iter。 您可以在LRFinder.range_test()中设置accumulation_steps参数,具有适当的值以执行梯度累积:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset ()apex.amp和torch.amp现在得到支持,以下是:
使用apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()使用torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()请注意,混合精度训练的好处需要带有张量芯的NVIDIA GPU(另请参见:NVIDIA/APEX#297)
此外,您可以尝试设置torch.backends.cudnn.benchmark = True以提高训练速度。 (但是在某些情况下它不起作用,您应该自担风险)
欢迎所有贡献,但首先,看看贡献。md。


