pytorch lr finder
v0.2.2

تطبيق Pytorch لاختبار نطاق التعلم مفصل في معدلات التعلم الدورية لتدريب الشبكات العصبية من قبل ليزلي إن سميث والنسخة المعدلة التي تستخدمها Fastai.
اختبار نطاق معدل التعلم هو اختبار يوفر معلومات قيمة حول معدل التعلم الأمثل. أثناء تشغيل ما قبل التدريب ، يتم زيادة معدل التعلم خطيًا أو بشكل كبير بين حدودين. يسمح معدل التعلم الأولي المنخفض للشبكة بالبدء في التقارب ومع زيادة معدل التعلم ، سيكون في النهاية أكبر من اللازم وستتباعد الشبكة.
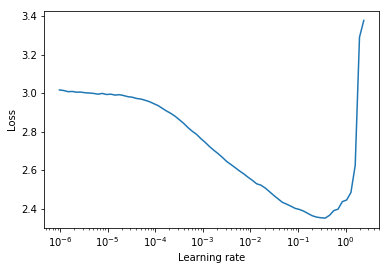
عادةً ما يمكن العثور على معدل تعلم ثابت جيد في منتصف الطريق على منحنى الخسارة التنازلي. في المؤامرة أدناه سيكون lr = 0.002 .
بالنسبة لمعدلات التعلم الدورية (المفصلة أيضًا في ورقة ليزلي سميث) حيث يتم تدوير معدل التعلم بين حدودين (start_lr, end_lr) ، ينصح المؤلف النقطة التي تبدأ فيها الخسارة في الهبوط والنقطة التي تتوقف عندها الخسارة عن الهبوط أو تصبح خشنة في start_lr و end_lr على التوالي. في المؤامرة أدناه ، start_lr = 0.0002 و end_lr=0.2 .
بيثون 3.5 وما فوق:
pip install torch-lr-finderالتثبيت بدعم من التدريب الدقيق المختلط (انظر أيضًا هذا القسم):
pip install torch-lr-finder -v --global-option= " apex " يزيد من معدل التعلم بطريقة أسية ويحسب خسارة التدريب لكل معدل تعليمي. lr_finder.plot() يرسم خسارة التدريب مقابل معدل التعلم اللوغاريتمي.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state يزيد معدل التعلم خطيًا ويحسب فقدان التقييم لكل معدل تعليمي. lr_finder.plot() يرسم فقدان التقييم مقابل معدل التعلم. ينتج هذا النهج عادةً منحنيات أكثر دقة لأن فقدان التقييم أكثر عرضة للاختلاف ولكنه يستغرق وقتًا أطول بكثير لإجراء الاختبار ، خاصة إذا كانت مجموعة بيانات التقييم كبيرة.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder يحتوي على LRScheduler متصل به.LRFinder.range_test() تغيير أوزان النموذج ومعلمات المُحسّنة. يمكن استعادة كلاهما إلى حالتهما الأولية باستخدام LRFinder.reset() .lr_finder.history . سيؤدي هذا إلى إرجاع قاموس مع مفاتيح lr loss .step_mode="linear" يجب أن يكون نطاق معدل التعلم في نفس الترتيب من حيث الحجم.LRFinder.range_test() زوجًا من input, label من كائنات DataLoader التي تم تمريرها إليها. يجب أن تكون input جاهزة للتمرير إلى النموذج ويجب أن تكون label جاهزة للتمرير إلى criterion دون أي مزيد من معالجة/معالجة/تحويل البيانات. إذا وجدت نفسك بحاجة إلى حل بديل ، فيمكنك الاستفادة من الفصول الدراسية TrainDataLoaderIter و ValDataLoaderIter لأداء أي معالجة/معالجة/تحويل البيانات بين DataLoader وحلقة التدريب/التقييم. يمكنك العثور على مثال على كيفية استخدام هذه الفئات في أمثلة/lrfinder_cifar10_dataloader_iter. يمكنك تعيين معلمة accumulation_steps في LRFinder.range_test() مع قيمة مناسبة لأداء تراكم التدرج:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset () يتم دعم كل من apex.amp و torch.amp الآن ، وهنا الأمثلة:
باستخدام apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset () باستخدام torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()لاحظ أن فائدة التدريب الدقيق المختلط تتطلب وحدة معالجة الرسومات NVIDIA مع نوى الموتر (انظر أيضًا: NVIDIA/APEX #297)
علاوة على ذلك ، يمكنك محاولة ضبط torch.backends.cudnn.benchmark = True لتحسين سرعة التدريب. (لكنها لن تنجح في بعض الحالات ، يجب عليك استخدامها على مسؤوليتك الخاصة)
جميع المساهمات موضع ترحيب ولكن أولاً ، ألق نظرة على المساهمة.


