pytorch lr finder
v0.2.2

Une mise en œuvre en pytorch du test de plage de taux d'apprentissage détaillée dans les taux d'apprentissage cyclique pour la formation des réseaux de neurones par Leslie N. Smith et la version modifiée utilisée par Fastai.
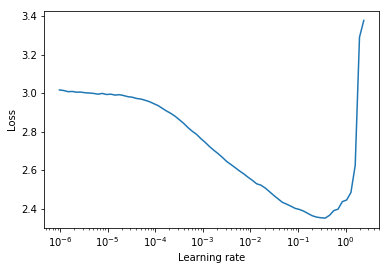
Le test de plage de taux d'apprentissage est un test qui fournit des informations précieuses sur le taux d'apprentissage optimal. Au cours d'une exécution avant la formation, le taux d'apprentissage augmente linéairement ou exponentiellement entre deux limites. Le faible taux d'apprentissage initial permet au réseau de commencer la convergence et à mesure que le taux d'apprentissage augmente, il sera finalement trop important et le réseau divergera.
En règle générale, un bon taux d'apprentissage statique peut être trouvé à mi-chemin de la courbe descente descendant. Dans le tracé ci-dessous, il serait lr = 0.002 .
Pour les taux d'apprentissage cycliques (également détaillés dans l'article de Leslie Smith) où le taux d'apprentissage est cyclable entre deux limites (start_lr, end_lr) , l'auteur conseille le point auquel la perte commence à descendre et le point où la perte cesse de descente ou devient en lambeaux pour start_lr et end_lr respectivement. Dans le tracé ci-dessous, start_lr = 0.0002 et end_lr=0.2 .
Python 3.5 et plus:
pip install torch-lr-finderInstaller avec le support de la formation de précision mixte (voir aussi cette section):
pip install torch-lr-finder -v --global-option= " apex " Augmente le taux d'apprentissage d'une manière exponentielle et calcule la perte de formation pour chaque taux d'apprentissage. lr_finder.plot() trace la perte de formation par rapport au taux d'apprentissage logarithmique.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state Augmente le taux d'apprentissage linéairement et calcule la perte d'évaluation pour chaque taux d'apprentissage. lr_finder.plot() trace la perte d'évaluation par rapport au taux d'apprentissage. Cette approche produit généralement des courbes plus précises car la perte d'évaluation est plus sensible à la divergence, mais il faut beaucoup plus de temps pour effectuer le test, surtout si l'ensemble de données d'évaluation est important.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder ne devrait pas avoir un LRScheduler attaché.LRFinder.range_test() modifiera les poids du modèle et les paramètres d'optimiseur. Les deux peuvent être restaurés à leur état initial avec LRFinder.reset() .lr_finder.history . Cela renverra un dictionnaire avec lr et des clés loss .step_mode="linear" la plage de taux d'apprentissage doit être dans le même ordre de grandeur.LRFinder.range_test() s'attend à ce qu'une paire d' input, label soit renvoyée des objets DataLoader qui lui sont transmis. L' input doit être prête à être transmise au modèle et l' label doit être prête à être transmise au criterion sans autre traitement / manutention / conversion de données. Si vous avez besoin d'une solution de contournement, vous pouvez utiliser les classes TrainDataLoaderIter et ValDataLoaderIter pour effectuer tout traitement / manipulation / conversion entre les données entre le DataLoader et la boucle de formation / évaluation. Vous pouvez trouver un exemple de la façon d'utiliser ces classes dans des exemples / lrfinder_cifar10_dataloader_iter. Vous pouvez définir le paramètre accumulation_steps dans LRFinder.range_test() avec une valeur appropriée pour effectuer une accumulation de gradient:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset () apex.amp et torch.amp sont pris en charge maintenant, voici les exemples:
Utilisation d' apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset () Utilisation de torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()Notez que l'avantage d'une formation de précision mixte nécessite un GPU NVIDIA avec des noyaux de tenseur (voir également: Nvidia / Apex # 297)
En outre, vous pouvez essayer de définir torch.backends.cudnn.benchmark = True pour améliorer la vitesse de formation. (Mais cela ne fonctionnera pas pour certains cas, vous devriez l'utiliser à vos propres risques)
Toutes les contributions sont les bienvenues, mais d'abord, jetez un œil à la contribution.md.


