pytorch lr finder
v0.2.2

การใช้งาน Pytorch ของการทดสอบช่วงอัตราการเรียนรู้รายละเอียดในอัตราการเรียนรู้แบบวัฏจักรสำหรับการฝึกอบรมเครือข่ายประสาทโดย Leslie N. Smith และรุ่นที่ปรับแต่งโดย Fastai
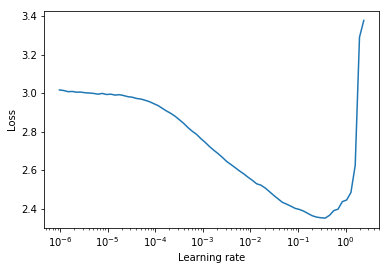
การทดสอบช่วงอัตราการเรียนรู้เป็นการทดสอบที่ให้ข้อมูลที่มีค่าเกี่ยวกับอัตราการเรียนรู้ที่ดีที่สุด ในระหว่างการฝึกอบรมก่อนการฝึกอบรมอัตราการเรียนรู้จะเพิ่มขึ้นเป็นเส้นตรงหรือแบบทวีคูณระหว่างสองขอบเขต อัตราการเรียนรู้เริ่มต้นต่ำช่วยให้เครือข่ายเริ่มการบรรจบกันและเมื่ออัตราการเรียนรู้เพิ่มขึ้นในที่สุดก็จะมีขนาดใหญ่เกินไปและเครือข่ายจะแตกต่างกัน
โดยทั่วไปแล้วอัตราการเรียนรู้แบบคงที่ที่ดีสามารถพบได้ครึ่งทางของเส้นโค้งการสูญเสียจากมากไปน้อย ในพล็อตด้านล่างที่จะเป็น lr = 0.002
สำหรับอัตราการเรียนรู้แบบวัฏจักร (ยังมีรายละเอียดในกระดาษของเลสลี่สมิ ธ ) ซึ่งอัตราการเรียนรู้ถูกปั่นจักรยานระหว่างสองขอบเขต ( start_lr , end_lr (start_lr, end_lr) ผู้เขียนแนะนำจุดที่การสูญเสียเริ่มลงและจุดที่การสูญเสียหยุดลง ในพล็อตด้านล่าง start_lr = 0.0002 และ end_lr=0.2
Python 3.5 ขึ้นไป:
pip install torch-lr-finderติดตั้งด้วยการสนับสนุนการฝึกอบรมแบบผสมผสาน (ดูส่วนนี้ด้วย):
pip install torch-lr-finder -v --global-option= " apex " เพิ่มอัตราการเรียนรู้ในลักษณะทวีคูณและคำนวณการสูญเสียการฝึกอบรมสำหรับแต่ละอัตราการเรียนรู้ lr_finder.plot() วางแผนการสูญเสียการฝึกอบรมกับอัตราการเรียนรู้ลอการิทึม
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state เพิ่มอัตราการเรียนรู้เชิงเส้นและคำนวณการสูญเสียการประเมินผลสำหรับแต่ละอัตราการเรียนรู้ lr_finder.plot() วางแผนการสูญเสียการประเมินผลกับอัตราการเรียนรู้ วิธีการนี้มักจะสร้างเส้นโค้งที่แม่นยำมากขึ้นเนื่องจากการสูญเสียการประเมินนั้นมีความอ่อนไหวต่อความแตกต่าง แต่ใช้เวลานานกว่าในการทดสอบโดยเฉพาะอย่างยิ่งหากชุดข้อมูลการประเมินมีขนาดใหญ่
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder ไม่ควรมี LRScheduler ติดอยู่LRFinder.range_test() จะเปลี่ยนน้ำหนักรุ่นและพารามิเตอร์เครื่องมือเพิ่มประสิทธิภาพ ทั้งสองสามารถกู้คืนสู่สถานะเริ่มต้นด้วย LRFinder.reset()lr_finder.history สิ่งนี้จะส่งคืนพจนานุกรมด้วย lr และปุ่ม lossstep_mode="linear" ช่วงอัตราการเรียนรู้ควรอยู่ในลำดับขนาดเดียวกันLRFinder.range_test() คาดว่าจะมีคู่ของ input, label ที่จะส่งคืนจากวัตถุ DataLoader ที่ส่งผ่านไป input จะต้องพร้อมที่จะส่งผ่านไปยังโมเดลและ label จะต้องพร้อมที่จะส่งผ่านไปยัง criterion โดยไม่ต้องประมวลผลข้อมูล/การจัดการ/การแปลงข้อมูลเพิ่มเติม หากคุณพบว่าตัวเองต้องการวิธีแก้ปัญหาคุณสามารถใช้ประโยชน์จากคลาส TrainDataLoaderIter และ ValDataLoaderIter เพื่อดำเนินการประมวลผล/การจัดการข้อมูลใด ๆ ระหว่าง DataLoader และลูปฝึกอบรม/ประเมินผล คุณสามารถค้นหาตัวอย่างของวิธีการใช้คลาสเหล่านี้ในตัวอย่าง/lrfinder_cifar10_dataloader_iter คุณสามารถตั้งค่าพารามิเตอร์ accumulation_steps ใน LRFinder.range_test() ด้วยค่าที่เหมาะสมในการทำการสะสมการไล่ระดับสี:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset () ทั้ง apex.amp และ torch.amp ได้รับการสนับสนุนตอนนี้นี่คือตัวอย่าง:
ใช้ apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset () ใช้ torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()โปรดทราบว่าประโยชน์ของการฝึกอบรมแบบผสมผสานแบบผสมต้องใช้ Nvidia GPU พร้อมแกนเทนเซอร์ (ดูเพิ่มเติมที่: Nvidia/Apex #297)
นอกจากนี้คุณสามารถลองตั้งค่า torch.backends.cudnn.benchmark = True เพื่อปรับปรุงความเร็วในการฝึกอบรม (แต่มันจะไม่ทำงานในบางกรณีคุณควรใช้มันด้วยความเสี่ยงของคุณเอง)
ยินดีต้อนรับการมีส่วนร่วมทั้งหมด แต่ก่อนอื่นลองดูที่ MD


