pytorch lr finder
v0.2.2

Implementasi Pytorch dari Tes Rentang Tingkat Pembelajaran yang dirinci dalam tingkat pembelajaran siklus untuk melatih jaringan saraf oleh Leslie N. Smith dan versi tweak yang digunakan oleh Fastai.
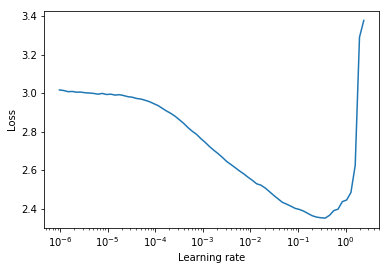
Tes rentang laju pembelajaran adalah tes yang memberikan informasi berharga tentang tingkat pembelajaran yang optimal. Selama menjalankan pra-pelatihan, tingkat pembelajaran meningkat secara linier atau eksponensial antara dua batas. Tingkat pembelajaran awal yang rendah memungkinkan jaringan untuk memulai konvergen dan karena tingkat pembelajaran meningkat pada akhirnya akan terlalu besar dan jaringan akan berbeda.
Biasanya, tingkat pembelajaran statis yang baik dapat ditemukan setengah jalan pada kurva kerugian menurun. Dalam plot di bawah ini akan menjadi lr = 0.002 .
Untuk tingkat pembelajaran siklus (juga dirinci dalam makalah Leslie Smith) di mana tingkat pembelajaran bersepeda antara dua batas (start_lr, end_lr) , penulis menyarankan titik di mana kerugian mulai turun dan titik di mana kerugian berhenti atau menjadi compang -camping masing -masing untuk start_lr dan end_lr . Dalam plot di bawah ini, start_lr = 0.0002 dan end_lr=0.2 .
Python 3.5 dan di atas:
pip install torch-lr-finderInstal dengan dukungan pelatihan presisi campuran (lihat juga bagian ini):
pip install torch-lr-finder -v --global-option= " apex " Meningkatkan tingkat pembelajaran secara eksponensial dan menghitung kerugian pelatihan untuk setiap tingkat pembelajaran. lr_finder.plot() memplot kehilangan pelatihan versus tingkat pembelajaran logaritmik.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 1e-7 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 100 , num_iter = 100 )
lr_finder . plot () # to inspect the loss-learning rate graph
lr_finder . reset () # to reset the model and optimizer to their initial state Meningkatkan tingkat pembelajaran secara linier dan menghitung kehilangan evaluasi untuk setiap tingkat pembelajaran. lr_finder.plot() memplot kehilangan evaluasi versus tingkat pembelajaran. Pendekatan ini biasanya menghasilkan kurva yang lebih tepat karena kehilangan evaluasi lebih rentan terhadap divergensi tetapi dibutuhkan secara signifikan lebih lama untuk melakukan tes, terutama jika dataset evaluasi besar.
from torch_lr_finder import LRFinder
model = ...
criterion = nn . CrossEntropyLoss ()
optimizer = optim . Adam ( model . parameters (), lr = 0.1 , weight_decay = 1e-2 )
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , val_loader = val_loader , end_lr = 1 , num_iter = 100 , step_mode = "linear" )
lr_finder . plot ( log_lr = False )
lr_finder . reset ()LRFinder tidak boleh memiliki LRScheduler yang melekat padanya.LRFinder.range_test() akan mengubah bobot model dan parameter pengoptimal. Keduanya dapat dikembalikan ke keadaan awal mereka dengan LRFinder.reset() .lr_finder.history . Ini akan mengembalikan kamus dengan kunci lr dan loss .step_mode="linear" rentang laju pembelajaran harus berada dalam urutan besarnya yang sama.LRFinder.range_test() mengharapkan sepasang input, label akan dikembalikan dari objek DataLoader yang diteruskan ke sana. input harus siap untuk diteruskan ke model dan label harus siap untuk diteruskan ke criterion tanpa pemrosesan/penanganan/konversi data lebih lanjut. Jika Anda membutuhkan solusi, Anda dapat memanfaatkan kelas TrainDataLoaderIter dan ValDataLoaderIter untuk melakukan pemrosesan data/penanganan/konversi data di antara DataLoader dan loop pelatihan/evaluasi. Anda dapat menemukan contoh cara menggunakan kelas -kelas ini dalam contoh/lrfinder_cifar10_dataloader_iter. Anda dapat mengatur parameter accumulation_steps di LRFinder.range_test() dengan nilai yang tepat untuk melakukan akumulasi gradien:
from torch . utils . data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size , real_batch_size = 32 , 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# Beware of the `batch_size` used by `DataLoader`
trainloader = DataLoader ( dataset , batch_size = real_batch_size , shuffle = True )
model = ...
criterion = ...
optimizer = ...
# (Optional) With this setting, `amp.scale_loss()` will be adopted automatically.
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder ( model , optimizer , criterion , device = "cuda" )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = "exp" , accumulation_steps = accumulation_steps )
lr_finder . plot ()
lr_finder . reset () Baik apex.amp dan torch.amp didukung sekarang, berikut adalah contohnya:
Menggunakan apex.amp :
from torch_lr_finder import LRFinder
from apex import amp
# Add this line before running `LRFinder`
model , optimizer = amp . initialize ( model , optimizer , opt_level = 'O1' )
lr_finder = LRFinder ( model , optimizer , criterion , device = 'cuda' , amp_backend = 'apex' )
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset () Menggunakan torch.amp
from torch_lr_finder import LRFinder
amp_config = {
'device_type' : 'cuda' ,
'dtype' : torch . float16 ,
}
grad_scaler = torch . cuda . amp . GradScaler ()
lr_finder = LRFinder (
model , optimizer , criterion , device = 'cuda' ,
amp_backend = 'torch' , amp_config = amp_config , grad_scaler = grad_scaler
)
lr_finder . range_test ( trainloader , end_lr = 10 , num_iter = 100 , step_mode = 'exp' )
lr_finder . plot ()
lr_finder . reset ()Perhatikan bahwa manfaat pelatihan presisi campuran membutuhkan GPU NVIDIA dengan inti tensor (lihat juga: NVIDIA/APEX #297)
Selain itu, Anda dapat mencoba mengatur torch.backends.cudnn.benchmark = True untuk meningkatkan kecepatan pelatihan. (Tapi itu tidak akan berhasil untuk beberapa kasus, Anda harus menggunakannya dengan risiko sendiri)
Semua kontribusi dipersilakan tetapi pertama -tama, lihat kontribusi.md.


