facenet pytorch
v2.5.3
您還可以用中文讀取此文件的翻譯版本。
這是在Pytorch中啟動重新系統(V1)模型的存儲庫,在VGGFACE2和CASIA-WEBFACE上進行了預定。
使用David Sandberg的Tensorflow Facenet Repo移植的參數初始化了Pytorch模型權重。
此存儲庫還包括在推理之前有效的MTCNN的Pytorch實現。這些模型也經過概述。據我們所知,這是最快的MTCNN實現。
安裝:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipython在Python中,進口面向託管和實例化模型:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()處理圖像:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 ))有關使用和實施詳細信息,請參見help(MTCNN)和help(InceptionResnetV1) 。
請參閱:型號/inception_resnet_v1.py
以下模型已移植到Pytorch(帶有下載pytorch state_dict的鏈接):
| 模型名稱 | LFW準確性(此處列出) | 培訓數據集 |
|---|---|---|
| 20180408-102900(111MB) | 0.9905 | casia-webface |
| 20180402-114759(107MB) | 0.9965 | vggface2 |
無需手動下載驗證的state_dict;它們會自動下載有關模型實例化的下載,並緩存以供將來在火炬緩存中使用。要在Pytorch中使用Inception Resnet(V1)模型進行面部識別/識別,請使用:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()在160x160 PX圖像上訓練了兩個預審計的模型,因此,如果應用於調整該形狀的圖像,則可以表現最佳。為了獲得最佳效果,也應使用MTCNN將圖像裁剪到面部(見下文)。
默認情況下,上述模型將返回圖像的512維嵌入。相反,要啟用分類,要么將classify=True to Model構造函數,也可以隨後使用model.classify = True設置對象屬性。對於VGGFACE2,驗證的模型將輸出長度為8631的logit向量,對於長度10575的Casia-Webface logit向量。
通過使用MTCNN檢測面部,可以在使用Inception Resnet模型計算嵌入或概率之前首先檢測面部,從而輕鬆地應用面部識別。示例中的示例代碼/celeb.ipynb提供了一個完整的示例管道,利用數據集,數據編載程序和可選的GPU處理。
MTCNN可用於構建面部跟踪系統(使用MTCNN.detect()方法)。可以在示例/face_tracking.ipynb上找到一個完整的面部跟踪示例。

在大多數情況下,實現面部識別的最佳方法是直接使用驗證模型,使用聚類算法或簡單的距離指標來確定面部的身份。但是,如果需要列式調整(即,如果要根據模型的輸出邏輯選擇身份),則可以在示例/finetune.ipynb中找到一個示例。
本指南說明了MTCNN模塊的功能。涵蓋的主題是:
請參閱Kaggle上的筆記本。
本筆記本展示了三個面部檢測包的使用:
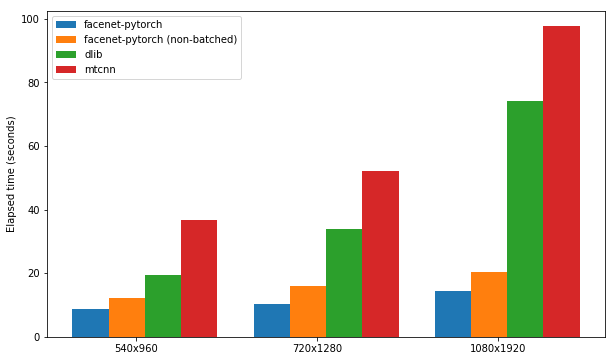
測試了每個軟件包的速度,以檢測一組300張圖像(一個視頻中的所有幀),並啟用了GPU支持。性能基於Kaggle的P100筆記本內核。結果總結下面。
| 包裹 | FPS(1080x1920) | FPS(720x1280) | FPS(540x960) |
|---|---|---|---|
| Facenet-Pytorch | 12.97 | 20.32 | 25.50 |
| FaceNet-Pytorch(非批處理) | 9.75 | 14.81 | 19.68 |
| Dlib | 3.80 | 8.39 | 14.53 |
| mtcnn | 3.04 | 5.70 | 8.23 |
請參閱Kaggle上的筆記本。
該算法通過利用相鄰框架之間的相似性來演示如何在視頻中專門實現非常有效的面部檢測。
請參閱Kaggle上的筆記本。
軟件包和任何示例筆記本可以使用Docker(或Nvidia-Docker)運行:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab 導航到示例/目錄並運行任何IPYTHON筆記本電腦。
有關Docker容器的詳細信息,請參見時代/Jupyter-DL-GPU。
要在您自己的git repo中使用此代碼,我建議首先將此倉庫添加為子模塊。請注意,在以s子管子為克時,應刪除存儲庫名稱中的儀表板(' - '),因為導入時會破壞python:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
另外,可以使用PIP作為軟件包安裝代碼:
pip install facenet-pytorch
請參閱:型號/utils/tensorflow2pytorch.py
請注意,不需要此功能即可使用此存儲庫中的模型,這僅取決於已保存的pytorch state_dict的s。
在實例化Pytorch模型後,每層的重量都是從Davidsandberg/FaceNet預驗證的張量模型中的等效層加載的。
原始張量流模型和Pytorch型模型的輸出的等效性已經進行了測試,並且是相同的:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
為了將Tensorflow參數重新運行到Pytorch模型中,請確保您用子模型克隆此存儲庫,因為將DavidSandberg/FaceNet Repo作為子模塊包括在內,並且部分需要進行轉換。
大衛·桑德伯格(David Sandberg
F. Schroff,D。 Kalenichenko,J。 Philbin。面部:面部識別和聚類的統一嵌入,ARXIV:1503.03832,2015。 PDF
Q. Cao,L。 Shen,W。 Xie,Om Parkhi,A。 Zisserman。 VGGFACE2:一個用於識別姿勢和年齡面孔的數據集,2018年自動面部和手勢識別國際會議。 PDF
D. Yi,Z。 Lei,S。 Liao和Sz li。 casiawebface:從頭開始學習面部表現,arxiv:1411.7923,2014。 PDF
K. Zhang,Z. Zhang,Z。 Li和Y. Qiao。使用多任務級聯卷積網絡的聯合面部檢測和對齊方式,IEEE信號處理信,2016年。 PDF


