facenet pytorch
v2.5.3
นอกจากนี้คุณยังสามารถอ่านเวอร์ชันที่แปลของไฟล์นี้เป็นภาษาจีน简体中文版
นี่คือที่เก็บข้อมูลสำหรับการเริ่มต้น Resnet (V1) ใน Pytorch, pretraned บน VGGFACE2 และ CASIA-WEBFACE
น้ำหนักโมเดล Pytorch เริ่มต้นโดยใช้พารามิเตอร์ที่พอร์ตจาก Repo tensorflow ของ David Sandberg
รวมอยู่ใน repo นี้คือการใช้ pytorch ที่มีประสิทธิภาพของ MTCNN สำหรับการตรวจจับใบหน้าก่อนการอนุมาน แบบจำลองเหล่านี้ยังได้รับการปรับแต่ง สำหรับความรู้ของเรานี่คือการใช้งาน MTCNN ที่เร็วที่สุดที่มีอยู่
ติดตั้ง:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipythonใน Python, นำเข้า facenet-pytorch และอินสแตนซ์โมเดล:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()ประมวลผลภาพ:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 )) ดู help(MTCNN) และ help(InceptionResnetV1) สำหรับรายละเอียดการใช้งานและการใช้งาน
ดู: โมเดล/inception_resnet_v1.py
โมเดลต่อไปนี้ได้รับการพอร์ตไปยัง Pytorch (พร้อมลิงค์เพื่อดาวน์โหลด Pytorch State_dict's):
| ชื่อนางแบบ | ความแม่นยำของ LFW (ตามที่ระบุไว้ที่นี่) | ชุดข้อมูลการฝึกอบรม |
|---|---|---|
| 20180408-102900 (111MB) | 0.9905 | Casia-Webface |
| 20180402-114759 (107MB) | 0.9965 | vggface2 |
ไม่จำเป็นต้องดาวน์โหลด Pretrained State_dict's; พวกเขาจะถูกดาวน์โหลดโดยอัตโนมัติในการสร้างอินสแตนซ์แบบจำลองและแคชเพื่อใช้ในอนาคตในแคชคบเพลิง ในการใช้แบบจำลองการเริ่มต้น Resnet (V1) สำหรับการจดจำใบหน้า/การระบุตัวตนใน Pytorch, ใช้:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()โมเดลที่ผ่านการฝึกอบรมทั้งสองได้รับการฝึกฝนบนภาพ 160x160 PX ดังนั้นจะทำงานได้ดีที่สุดหากนำไปใช้กับภาพที่ปรับขนาดกับรูปร่างนี้ เพื่อผลลัพธ์ที่ดีที่สุดรูปภาพควรถูกครอบตัดบนใบหน้าโดยใช้ MTCNN (ดูด้านล่าง)
โดยค่าเริ่มต้นโมเดลข้างต้นจะส่งคืนการฝังภาพ 512 มิติของภาพ ในการเปิดใช้งานการจำแนกประเภทแทนไม่ว่าจะผ่าน classify=True ไปยังตัวสร้างโมเดลหรือคุณสามารถตั้งค่าแอตทริบิวต์วัตถุหลังจากนั้นด้วย model.classify = True สำหรับ VGGFACE2 แบบจำลองที่ผ่านการฝึกอบรมจะส่งออกเวกเตอร์ logit ที่มีความยาว 8631 และสำหรับ casia-webface logit เวกเตอร์ความยาว 10575
การจดจำใบหน้าสามารถนำไปใช้กับภาพดิบได้อย่างง่ายดายโดยการตรวจจับใบหน้าครั้งแรกโดยใช้ MTCNN ก่อนที่จะคำนวณการฝังหรือความน่าจะเป็นโดยใช้แบบจำลอง ResNet Inception รหัสตัวอย่างที่ตัวอย่าง/infer.ipynb ให้ตัวอย่างที่สมบูรณ์ไปป์ไลน์ที่ใช้ชุดข้อมูล Dataloaders และการประมวลผล GPU เสริม
MTCNN สามารถใช้ในการสร้างระบบติดตามใบหน้า (ใช้วิธี MTCNN.detect() ) ตัวอย่างการติดตามหน้าเต็มสามารถพบได้ที่ตัวอย่าง/face_tracking.ipynb

ในสถานการณ์ส่วนใหญ่วิธีที่ดีที่สุดในการใช้การจดจำใบหน้าคือการใช้โมเดลที่ผ่านการฝึกอบรมโดยตรงด้วยอัลกอริทึมการจัดกลุ่มหรือตัวชี้วัดระยะทางที่เรียบง่ายเพื่อกำหนดตัวตนของใบหน้า อย่างไรก็ตามหากจำเป็นต้องมีการกำหนด finetuning (เช่นหากคุณต้องการเลือกตัวตนตามบันทึกเอาต์พุตของโมเดล) ตัวอย่างสามารถพบได้ที่ตัวอย่าง/finetune.ipynb
คู่มือนี้แสดงให้เห็นถึงการทำงานของโมดูล MTCNN หัวข้อที่ครอบคลุมคือ:
ดูสมุดบันทึกบน Kaggle
สมุดบันทึกนี้แสดงให้เห็นถึงการใช้แพ็คเกจตรวจจับใบหน้าสามชุด:
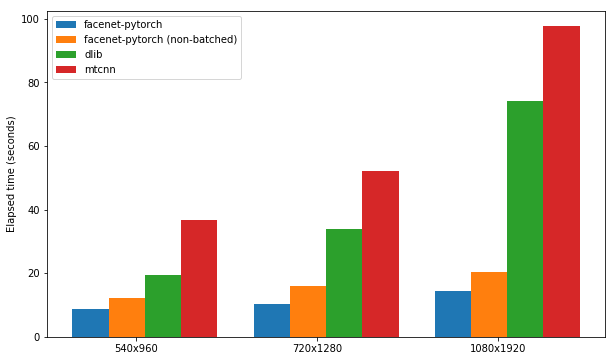
แต่ละแพ็คเกจได้รับการทดสอบด้วยความเร็วในการตรวจจับใบหน้าในชุดภาพ 300 ภาพ (เฟรมทั้งหมดจากวิดีโอหนึ่งรายการ) โดยเปิดใช้งานการรองรับ GPU ประสิทธิภาพขึ้นอยู่กับเคอร์เนลโน้ตบุ๊ก P100 ของ Kaggle ผลลัพธ์สรุปไว้ด้านล่าง
| บรรจุุภัณฑ์ | FPS (1080x1920) | FPS (720x1280) | FPS (540x960) |
|---|---|---|---|
| หน้าผาก | 12.97 | 20.32 | 25.50 |
| Facenet-Pytorch (ไม่ได้ติดตั้ง) | 9.75 | 14.81 | 19.68 |
| dlib | 3.80 | 8.39 | 14.53 |
| MTCNN | 3.04 | 5.70 | 8.23 |
ดูสมุดบันทึกบน Kaggle
อัลกอริทึมนี้แสดงให้เห็นถึงวิธีการตรวจจับใบหน้าที่มีประสิทธิภาพอย่างมากโดยเฉพาะในวิดีโอโดยใช้ประโยชน์จากความคล้ายคลึงกันระหว่างเฟรมที่อยู่ติดกัน
ดูสมุดบันทึกบน Kaggle
แพ็คเกจและสมุดบันทึกตัวอย่างใด ๆ สามารถเรียกใช้กับ Docker (หรือ Nvidia-Docker) โดยใช้:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab นำทางไปยังตัวอย่าง/ ไดเรกทอรีและเรียกใช้สมุดบันทึก ipython ใด ๆ
ดู Timesler/Jupyter-DL-GPU สำหรับรายละเอียดคอนเทนเนอร์ Docker
หากต้องการใช้รหัสนี้ใน GIT Repo ของคุณเองฉันขอแนะนำให้เพิ่ม repo นี้เป็น submodule ก่อน โปรดทราบว่าควรลบ dash ('-') ในชื่อ repo เมื่อโคลนเป็น submodule เนื่องจากจะทำลาย Python เมื่อนำเข้า:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
อีกทางเลือกหนึ่งรหัสสามารถติดตั้งเป็นแพ็คเกจโดยใช้ PIP:
pip install facenet-pytorch
ดู: รุ่น/utils/tensorflow2pytorch.py
โปรดทราบว่าฟังก์ชั่นนี้ไม่จำเป็นต้องใช้โมเดลใน repo นี้ซึ่งขึ้นอยู่กับ pytorch state_dict ที่บันทึกไว้เท่านั้น
หลังจากการสร้างอินสแตนซ์ของโมเดล Pytorch น้ำหนักของแต่ละชั้นจะถูกโหลดจากเลเยอร์ที่เทียบเท่าในรุ่น tensorflow ที่ได้รับการฝึกฝนจาก Davidsandberg/Facenet
ความเท่าเทียมกันของเอาต์พุตจากรุ่น Tensorflow ดั้งเดิมและโมเดล Pytorch-ported ได้รับการทดสอบและเหมือนกัน:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
เพื่อที่จะเรียกใช้การแปลงพารามิเตอร์ tensorflow อีกครั้งเป็นโมเดล pytorch ให้แน่ใจว่าคุณโคลน repo นี้ กับ submodules เนื่องจาก davidsandberg/facenet repo รวมอยู่ในรูปแบบ submodule และบางส่วนของมันสำหรับการแปลง
Repo Facenet ของ David Sandberg: https://github.com/davidsandberg/facenet
F. Schroff, D. Kalenichenko, J. Philbin Facenet: การฝังแบบครบวงจรสำหรับการจดจำใบหน้าและการจัดกลุ่ม , arxiv: 1503.03832, 2015. PDF
Q. Cao, L. Shen, W. Xie, OM Parkhi, A. Zisserman VGGFACE2: ชุดข้อมูลสำหรับการจดจำใบหน้าข้ามท่าและอายุ การประชุมนานาชาติเกี่ยวกับการรับรู้ใบหน้าและท่าทางอัตโนมัติ 2018 PDF
D. Yi, Z. Lei, S. Liao และ Sz Li casiawebface: การเรียนรู้ใบหน้าเป็นตัวแทนตั้งแต่เริ่มต้น , arxiv: 1411.7923, 2014. PDF
K. Zhang, Z. Zhang, Z. Li และ Y. Qiao การตรวจจับใบหน้าร่วมและการจัดตำแหน่งโดยใช้เครือข่าย cascaded cascaded , จดหมายประมวลผลสัญญาณ IEEE, 2016. PDF


