facenet pytorch
v2.5.3
Sie können auch eine übersetzte Version dieser Datei in Chinesisch lesen.
Dies ist ein Repository für Inception ResNet (V1) -Modelle in Pytorch, das auf VGGFace2 und Casia-Webface vorbereitet ist.
Pytorch -Modellgewichte wurden unter Verwendung von Parametern aus David Sandbergs Tensorflow Spacenet Repo initialisiert.
Ebenfalls in diesem Repo enthalten ist eine effiziente Pytorch -Implementierung von MTCNN zur Gesichtserkennung vor der Inferenz. Diese Modelle sind ebenfalls vorbereitet. Nach unserem Kenntnisstand ist dies die schnellste verfügbare MTCNN -Implementierung.
Installieren:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipythonIn Python importieren Sie Spaceet-Pytorch und instanziiert Modelle:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()Verarbeiten Sie ein Bild:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 )) In help(MTCNN) und help(InceptionResnetV1) finden Sie die Nutzungs- und Implementierungsdetails.
Siehe: Models/Inception_resnet_v1.py
Die folgenden Modelle wurden auf Pytorch portiert (mit Links zum Herunterladen von pytorch state_dict's):
| Modellname | LFW -Genauigkeit (wie hier aufgeführt) | Trainingsdatensatz |
|---|---|---|
| 20180408-102900 (111 MB) | 0,9905 | Casia-Webface |
| 20180402-114759 (107 MB) | 0,9965 | Vggface2 |
Es ist nicht nötig, die vorgefertigten State_Dict's manuell herunterzuladen. Sie werden automatisch in der Modell -Instanziierung heruntergeladen und für die zukünftige Verwendung im Fackelcache zwischengespeichert. Verwenden Sie ein Inception ResNet (V1) -Modell für Gesichtserkennung/Identifizierung in Pytorch: Verwenden Sie:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()Beide vorbereiteten Modelle wurden auf 160x160 PX -Bildern trainiert und werden daher am besten auf die angegriffenen Bilder in dieser Form geleistet. Für die besten Ergebnisse sollten Bilder auch mit MTCNN ins Gesicht geschnitten werden (siehe unten).
Standardmäßig werden die obigen Modelle 512-dimensionale Einbettungen von Betten zurückgeben. Um die Klassifizierung stattdessen zu aktivieren, passieren Sie entweder classify=True an den Modellkonstruktor, oder Sie können das Objektattribut anschließend mit model.classify = True festlegen. Für VGGFace2 gibt das vorgezogene Modell Logit-Vektoren von Länge 8631 und für Logit-Vektoren von Casia-Webface von Länge 10575 aus.
Die Gesichtserkennung kann leicht auf Rohbilder angewendet werden, indem zuerst Gesichter unter Verwendung von MTCNN erfasst werden, bevor die Einbettung oder Wahrscheinlichkeiten unter Verwendung eines Inception ResNet -Modells berechnet werden. Der Beispielcode bei Beispielen/Infer.IPYNB bietet eine vollständige Beispielpipeline mit Datensätzen, Dataloadern und optionaler GPU -Verarbeitung.
MTCNN kann verwendet werden, um ein Gesichts -Tracking -System zu erstellen (unter Verwendung der Methode MTCNN.detect() ). Ein Beispiel für das vollständige Gesichts -Tracking finden Sie unter Beispielen/face_tracking.ipynb.

In den meisten Situationen besteht der beste Weg, die Gesichtserkennung zu implementieren, die vorbereiteten Modelle direkt mit einem Clustering -Algorithmus oder einer einfachen Abstandmetriken, um die Identität eines Gesichts zu bestimmen. Wenn jedoch eine Finetuning erforderlich ist (dh, wenn Sie die Identität basierend auf den Ausgangsprotokoll des Modells auswählen möchten), finden Sie ein Beispiel bei Beispielen/Figune.ipynb.
Diese Anleitung demonstriert die Funktionalität des MTCNN -Moduls. Themen abgedeckt sind:
Siehe das Notizbuch auf Kaggle.
Dieses Notizbuch zeigt die Verwendung von drei Gesichtserkennungspaketen:
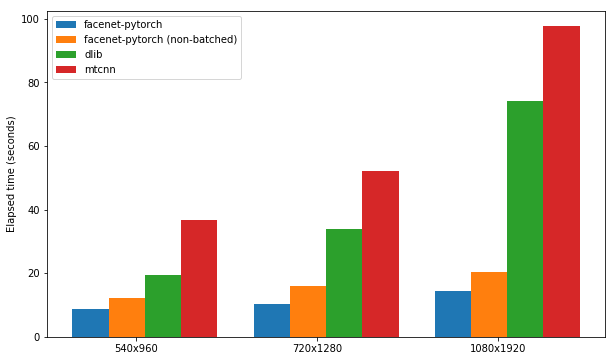
Jedes Paket wird auf seine Geschwindigkeit beim Erkennen der Gesichter in einem Satz von 300 Bildern (alle Frames aus einem Video) getestet, wobei die GPU -Unterstützung aktiviert ist. Die Leistung basiert auf Kaggle's P100 Notebook -Kernel. Die Ergebnisse sind nachstehend zusammengefasst.
| Paket | FPS (1080x1920) | FPS (720x1280) | FPS (540x960) |
|---|---|---|---|
| Spaceet-Pytorch | 12.97 | 20.32 | 25.50 |
| Spaceet-Pytorch (nicht begegnet) | 9.75 | 14.81 | 19.68 |
| DLIB | 3.80 | 8.39 | 14.53 |
| mtcnn | 3.04 | 5.70 | 8.23 |
Siehe das Notizbuch auf Kaggle.
Dieser Algorithmus zeigt, wie sie in Videos eine äußerst effiziente Gesichtserkennung erzielen können, indem sie Ähnlichkeiten zwischen benachbarten Rahmen nutzen.
Siehe das Notizbuch auf Kaggle.
Das Paket und ein beliebiges Beispiel-Notizbücher können mit Docker (oder Nvidia-Docker) mit:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab Navigieren Sie zu den Beispielen/ Verzeichnissen und führen Sie eine der Ipython -Notizbücher aus.
In Timesler/Jupyter-DL-GPU finden Sie Details von Docker Container.
Um diesen Code in Ihrem eigenen Git -Repo zu verwenden, empfehle ich, dieses Repo zunächst als Submodul hinzuzufügen. Beachten Sie, dass der Dash ('-') im Repo-Namen beim Klonen als Submodul entfernt werden sollte, da er beim Import Python brechen wird:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
Alternativ kann der Code mit PIP als Paket installiert werden:
pip install facenet-pytorch
Siehe: Models/Utils/TensorFlow2PyTorch.py
Beachten Sie, dass diese Funktionalität nicht benötigt wird, um die Modelle in diesem Repo zu verwenden, die nur von den gespeicherten Pytorch state_dict 's abhängen.
Nach der Instanziierung des Pytorch -Modells wurden die Gewichte der einzelnen Schicht aus äquivalenten Schichten in den vorgezogenen Tensorflow -Modellen von Davidsandberg/Spacenet geladen.
Die Äquivalenz der Ausgänge aus den ursprünglichen Tensorflow-Modellen und den Pytorch-portierten Modellen wurden getestet und sind identisch:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
Um die Umwandlung von Tensorflow-Parametern in das Pytorch-Modell erneut auszuführen, stellen Sie sicher, dass Sie dieses Repo mit Submodulen klonen, da das Davidsandberg/Spaceet-Repo als Submodul enthalten ist und Teile davon für die Umwandlung erforderlich sind.
David Sandbergs Faceet Repo: https://github.com/davidsandberg/facenet
F. Schroff, D. Kalenichenko, J. Philbin. FACENET: Eine einheitliche Einbettung für Gesichtserkennung und Clustering , ARXIV: 1503.03832, 2015. PDF
Q. Cao, L. Shen, W. Xie, Om Parkhi, A. Zisserman. VGGFace2: Ein Datensatz zur Erkennung von Gesicht und Alter , internationale Konferenz über automatische Gesicht und Gestenerkennung, 2018. PDF
D. Yi, Z. Lei, S. Liao und SZ Li. Casiawebface: Lerngesichtsrepräsentation von Grund auf , Arxiv: 1411.7923, 2014. PDF
K. Zhang, Z. Zhang, Z. Li und Y. Qiao. Erkennung und Ausrichtung der gemeinsamen Gesichtsausrichtung unter Verwendung von kaskadierten Faltungsnetzen mit Multitasking , IEEE Signal Processing Letters, 2016. PDF


