facenet pytorch
v2.5.3
また、このファイルの翻訳されたバージョンを中国語で読むこともできます。
これは、PytorchのInception Resnet(V1)モデルのリポジトリであり、VGGFace2およびCasia-Webfaceで前提とされています。
Pytorchモデルの重みは、David SandbergのTensorflow Facenet Repoから移植されたパラメーターを使用して初期化されました。
また、このリポジトリには、推論前の顔検出のためのMTCNNの効率的なPytorch実装も含まれています。これらのモデルも事前に処理されています。私たちの知る限り、これは利用可能な最速のMTCNN実装です。
インストール:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipythonPythonでは、Facenet-Pytorchをインポートし、インスタンスモデルをインスタンス化します。
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()画像を処理する:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 ))使用法と実装の詳細についてはhelp(MTCNN)およびhelp(InceptionResnetV1)を参照してください。
参照:モデル/inception_resnet_v1.py
次のモデルは、Pytorchに移植されています(Pytorch State_Dictのダウンロードへのリンクを使用):
| モデル名 | LFWの精度(ここにリストされている) | トレーニングデータセット |
|---|---|---|
| 20180408-102900(111MB) | 0.9905 | Casia-Webface |
| 20180402-114759(107MB) | 0.9965 | vggface2 |
事前に守られたstate_dictを手動でダウンロードする必要はありません。それらはモデルインスタンス化で自動的にダウンロードされ、トーチキャッシュで将来使用するためにキャッシュされます。 Inception Resnet(V1)モデルを使用するには、Pytorchでの顔認識/識別のために、次を使用します。
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()どちらの前のモデルも160x160 PX画像でトレーニングされているため、この形状にサイズ変更された画像に適用されると最適に機能します。最良の結果を得るには、MTCNNを使用して画像を顔にトリミングする必要があります(以下を参照)。
デフォルトでは、上記のモデルは512次元の画像の埋め込みを返します。代わりに分類を有効にするには、Pass classify=True to the Model Constructorにかかるか、その後model.classify = Trueでオブジェクト属性を設定できます。 VGGFACE2の場合、前処理されたモデルは長さ8631のロジットベクトルを出力し、長さ10575のcasia-webfaceロジットベクトルの出力ベクトルを出力します。
Inception ResNetモデルを使用して埋め込みまたは確率を計算する前に、MTCNNを使用して最初に顔を検出することにより、顔認識を生の画像に簡単に適用できます。 Examples/dempynbのサンプルコードは、データセット、データローダー、およびオプションのGPU処理を使用した完全な例のパイプラインを提供します。
MTCNNを使用して、フェイストラッキングシステムを構築できます( MTCNN.detect()メソッドを使用)。 FACE_TRACKING.IPYNBには、完全な顔の追跡の例があります。

ほとんどの状況では、顔認識を実装する最良の方法は、クラスタリングアルゴリズムまたは単純な距離メトリックのいずれかを使用して、顔のアイデンティティを決定するための単純な距離メトリックのいずれかを使用して、前提条件のモデルを直接使用することです。ただし、Finetuningが必要な場合(つまり、モデルの出力ロジットに基づいてIDを選択する場合)、Examples/Finetune.ipynbで例を見つけることができます。
このガイドは、MTCNNモジュールの機能を示しています。カバーされているトピックは次のとおりです。
Kaggleのノートブックを参照してください。
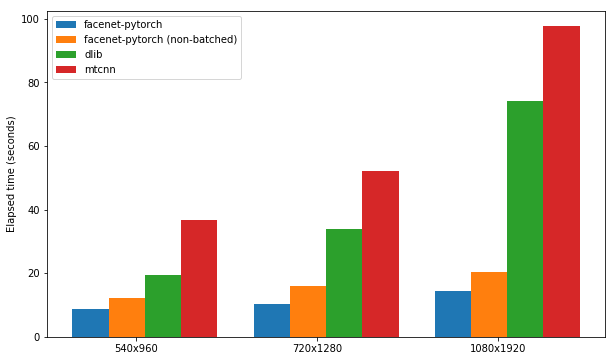
このノートブックは、3つの顔検出パッケージの使用を示しています。
各パッケージは、GPUサポートを有効にして、300枚の画像のセット(1つのビデオからのすべてのフレーム)のセット(すべてのフレーム)で顔を検出する速度をテストします。パフォーマンスは、KaggleのP100ノートブックカーネルに基づいています。結果を以下に要約します。
| パッケージ | FPS(1080x1920) | FPS(720x1280) | FPS(540x960) |
|---|---|---|---|
| FaceNet-Pytorch | 12.97 | 20.32 | 25.50 |
| FaceNet-Pytorch(バッチなし) | 9.75 | 14.81 | 19.68 |
| dlib | 3.80 | 8.39 | 14.53 |
| mtcnn | 3.04 | 5.70 | 8.23 |
Kaggleのノートブックを参照してください。
このアルゴリズムは、隣接するフレーム間の類似性を活用することにより、ビデオで特に非常に効率的な顔検出を実現する方法を示しています。
Kaggleのノートブックを参照してください。
パッケージとノートブックの例は、以下を使用してDocker(またはnvidia-docker)で実行できます。
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab 例/ディレクトリに移動し、iPythonノートブックを実行します。
Dockerコンテナの詳細については、Timesler/Jupyter-DL-GPUを参照してください。
このコードを独自のGITリポジトリで使用するには、最初にこのリポジトリをサブモジュールとして追加することをお勧めします。リポジトリ名のダッシュ( ' - ')は、サブモジュールとしてクローニングするときに削除する必要があることに注意してください。
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
または、コードをPIPを使用してパッケージとしてインストールすることもできます。
pip install facenet-pytorch
参照:モデル/utils/tensorflow2pytorch.py
この機能は、保存されているPytorch state_dictのみに依存するこのレポでモデルを使用するために必要ではないことに注意してください。
Pytorchモデルのインスタンス化に続いて、各層の重みは、Davidsandberg/Facenetの前提条件のTensorflowモデルの同等の層からロードされました。
元のTensorflowモデルとPytorchポートされたモデルからの出力の等価性がテストされており、同一です。
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
TensorflowパラメーターのPytorchモデルへの変換を再実行するには、Davidsandberg/Facenet Repoがサブモジュールとして含まれているため、サブモジュールでこのレポをクローンすることを確認し、変換にはその一部が必要です。
David SandbergのFacenet Repo:https://github.com/davidsandberg/facenet
F.シュロフ、D。カレニチェンコ、J。フィルビン。 FACENET:顔認識とクラスタリングのための統一埋め込み、arxiv:1503.03832、2015。PDF
Q. Cao、L。Shen、W。Xie、Om Parkhi、A。Zisserman。 VGGFACE2:ポーズと年齢の顔を認識するためのデータセット、自動面とジェスチャー認識に関する国際会議、2018。PDF
D. Yi、Z。Lei、S。Liao、SZ Li。 casiawebface:ゼロから顔の表現を学ぶ、arxiv:1411.7923、2014。PDF
K. Zhang、Z。Zhang、Z。Li、Y。Qiao。マルチタスクカスケード畳み込みネットワークを使用した共同顔面検出とアライメント、IEEE信号処理レター、2016。PDF


