facenet pytorch
v2.5.3
Vous pouvez également lire une version traduite de ce fichier en chinois 简体中文版.
Il s'agit d'un référentiel pour les modèles RESNET de création (V1) dans Pytorch, prétraité sur VGGFace2 et Casia-webface.
Les poids des modèles Pytorch ont été initialisés à l'aide de paramètres portés à partir du repo Facenet Tensorflow de David Sandberg.
Ce dépôt comprend également une implémentation Pytorch efficace de MTCNN pour la détection du visage avant l'inférence. Ces modèles sont également pré-entraînés. À notre connaissance, il s'agit de l'implémentation MTCNN la plus rapide disponible.
Installer:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipythonDans Python, importez des modèles Facenet-Pytorch et instanciés:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()Traiter une image:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 )) Voir help(MTCNN) et help(InceptionResnetV1) pour les détails d'utilisation et d'implémentation.
Voir: Modèles / INCEPTION_RESNET_V1.py
Les modèles suivants ont été portés sur Pytorch (avec des liens pour télécharger Pytorch State_Dict's):
| Nom du modèle | Précision LFW (comme indiqué ici) | Ensemble de données de formation |
|---|---|---|
| 20180408-102900 (111 Mo) | 0,9905 | Casia-webface |
| 20180402-114759 (107 Mo) | 0,9965 | Vggface2 |
Il n'est pas nécessaire de télécharger manuellement le state_dict prétrainé; Ils sont téléchargés automatiquement sur l'instanciation du modèle et mis en cache pour une utilisation future dans le cache de torche. Pour utiliser un modèle Resnet (V1) de création pour la reconnaissance / l'identification faciale dans Pytorch, utilisation:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()Les deux modèles pré-entraînés ont été formés sur des images 160x160 px, donc fonctionneront mieux si elles sont appliquées aux images redimensionnées à cette forme. Pour de meilleurs résultats, les images doivent également être recadrées sur le visage en utilisant MTCNN (voir ci-dessous).
Par défaut, les modèles ci-dessus renvoient des intégres d'images à 512 dimensions. Pour activer la classification à la place, passez classify=True au constructeur du modèle, soit vous pouvez définir l'attribut objet par la suite avec model.classify = True . Pour VGGFace2, le modèle pré-entraîné sortira les vecteurs logit de la longueur 8631 et pour les vecteurs logit Casia-Webface de la longueur 10575.
La reconnaissance du visage peut être facilement appliquée aux images brutes en détectant d'abord les faces en utilisant le mtcnn avant de calculer l'intégration ou les probabilités à l'aide d'un modèle RESNET de création. L'exemple de code à Exemples / Infer.ipynb fournit un exemple complet de pipeline en utilisant des ensembles de données, des dataloaders et un traitement GPU en option.
MTCNN peut être utilisé pour construire un système de suivi du visage (en utilisant la méthode MTCNN.detect() ). Un exemple de suivi du visage complet peut être trouvé sur des exemples / face_tracking.ipynb.

Dans la plupart des situations, la meilleure façon de mettre en œuvre la reconnaissance du visage est d'utiliser directement les modèles pré-entraînés, soit avec un algorithme de clustering ou des métriques de distance simples pour déterminer l'identité d'un visage. Cependant, si la finetuning est requise (c'est-à-dire, si vous souhaitez sélectionner l'identité en fonction des logits de sortie du modèle), un exemple peut être trouvé sur des exemples / finetune.ipynb.
Ce guide démontre la fonctionnalité du module MTCNN. Les sujets abordés sont:
Voir le cahier sur Kaggle.
Ce cahier montre l'utilisation de trois packages de détection de visage:
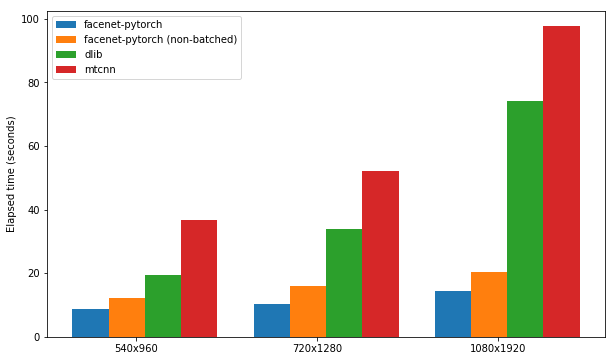
Chaque package est testé pour sa vitesse dans la détection des faces dans un ensemble de 300 images (toutes les cadres d'une vidéo), avec le support GPU activé. Les performances sont basées sur le noyau de carnet P100 de Kaggle. Les résultats sont résumés ci-dessous.
| Emballer | FPS (1080x1920) | FPS (720x1280) | FPS (540x960) |
|---|---|---|---|
| facenet-pytorch | 12.97 | 20.32 | 25.50 |
| Facenet-Pytorch (non-dossier) | 9.75 | 14.81 | 19.68 |
| dlib | 3.80 | 8.39 | 14.53 |
| MTCNN | 3.04 | 5.70 | 8.23 |
Voir le cahier sur Kaggle.
Cet algorithme montre comment réaliser une détection de visage extrêmement efficace spécifiquement dans les vidéos, en tirant parti des similitudes entre les cadres adjacents.
Voir le cahier sur Kaggle.
Le package et l'un des exemples de carnets peuvent être exécutés avec Docker (ou Nvidia-Docker) en utilisant:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab Accédez aux exemples / répertoires et exécutez l'un des ordinateurs portables IPython.
Voir Timesler / Jupyter-DL-GPU pour les détails du conteneur Docker.
Pour utiliser ce code dans votre propre dépôt git, je recommande d'abord d'ajouter ce référentiel en sous-module. Notez que le tableau de bord ('-') dans le nom de répension doit être supprimé lors du clonage en tant que sous-module car il cassera Python lors de l'importation:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
Alternativement, le code peut être installé comme un package à l'aide de PIP:
pip install facenet-pytorch
Voir: modèles / utils / tensorflow2pytorch.py
Notez que cette fonctionnalité n'est pas nécessaire pour utiliser les modèles de ce dépôt, qui ne dépendent que des Pytorch state_dict enregistrés.
Après l'instanciation du modèle Pytorch, les poids de chaque couche ont été chargés à partir de couches équivalentes dans les modèles Tensorflow pré-entraînés de Davidsandberg / Facenet.
L'équivalence des sorties des modèles TensorFlow d'origine et des modèles porteurs de Pytorch a été testée et est identique:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
Afin de réintégrer la conversion des paramètres de tensorflow dans le modèle Pytorch, vous assurez de cloner ce référentiel avec des sous-modules , car le repo Davidsandberg / facenet est inclus comme sous-module et des parties de celui-ci sont nécessaires pour la conversion.
Repo Facenet de David Sandberg: https://github.com/davidsandberg/facenet
F. Schroff, D. Kalenichenko, J. Philbin. Facenet: une intégration unifiée pour la reconnaissance faciale et le clustering , Arxiv: 1503.03832, 2015. PDF
Q. Cao, L. Shen, W. Xie, Om Parkhi, A. Zisserman. VGGFace2: un ensemble de données pour la reconnaissance du visage à travers la pose et l'âge , Conférence internationale sur le visage automatique et la reconnaissance des gestes, 2018. PDF
D. Yi, Z. Lei, S. Liao et Sz Li. CasiaWebface: Apprentissage de la représentation du visage à partir de zéro , Arxiv: 1411.7923, 2014. PDF
K. Zhang, Z. Zhang, Z. Li et Y. Qiao. Détection et alignement du visage conjoint à l'aide de réseaux convolutionnels en cascade multitâche , Leee Signal Processing Letters, 2016. PDF


