facenet pytorch
v2.5.3
您还可以用中文读取此文件的翻译版本。
这是在Pytorch中启动重新系统(V1)模型的存储库,在VGGFACE2和CASIA-WEBFACE上进行了预定。
使用David Sandberg的Tensorflow Facenet Repo移植的参数初始化了Pytorch模型权重。
此存储库还包括在推理之前有效的MTCNN的Pytorch实现。这些模型也经过概述。据我们所知,这是最快的MTCNN实现。
安装:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipython在Python中,进口面向托管和实例化模型:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()处理图像:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 ))有关使用和实施详细信息,请参见help(MTCNN)和help(InceptionResnetV1) 。
请参阅:型号/inception_resnet_v1.py
以下模型已移植到Pytorch(带有下载pytorch state_dict的链接):
| 模型名称 | LFW准确性(此处列出) | 培训数据集 |
|---|---|---|
| 20180408-102900(111MB) | 0.9905 | casia-webface |
| 20180402-114759(107MB) | 0.9965 | vggface2 |
无需手动下载验证的state_dict;它们会自动下载有关模型实例化的下载,并缓存以供将来在火炬缓存中使用。要在Pytorch中使用Inception Resnet(V1)模型进行面部识别/识别,请使用:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()在160x160 PX图像上训练了两个预审计的模型,因此,如果应用于调整该形状的图像,则可以表现最佳。为了获得最佳效果,也应使用MTCNN将图像裁剪到面部(见下文)。
默认情况下,上述模型将返回图像的512维嵌入。相反,要启用分类,要么将classify=True to Model构造函数,也可以随后使用model.classify = True设置对象属性。对于VGGFACE2,验证的模型将输出长度为8631的logit向量,对于长度10575的Casia-Webface logit向量。
通过使用MTCNN检测面部,可以在使用Inception Resnet模型计算嵌入或概率之前首先检测面部,从而轻松地应用面部识别。示例中的示例代码/celeb.ipynb提供了一个完整的示例管道,利用数据集,数据编载程序和可选的GPU处理。
MTCNN可用于构建面部跟踪系统(使用MTCNN.detect()方法)。可以在示例/face_tracking.ipynb上找到一个完整的面部跟踪示例。

在大多数情况下,实现面部识别的最佳方法是直接使用验证模型,使用聚类算法或简单的距离指标来确定面部的身份。但是,如果需要列式调整(即,如果要根据模型的输出逻辑选择身份),则可以在示例/finetune.ipynb中找到一个示例。
本指南说明了MTCNN模块的功能。涵盖的主题是:
请参阅Kaggle上的笔记本。
本笔记本展示了三个面部检测包的使用:
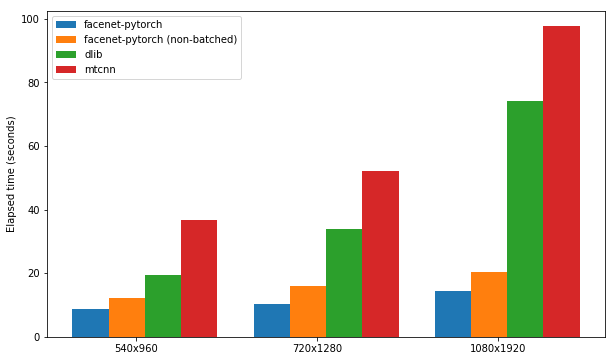
测试了每个软件包的速度,以检测一组300张图像(一个视频中的所有帧),并启用了GPU支持。性能基于Kaggle的P100笔记本内核。结果总结下面。
| 包裹 | FPS(1080x1920) | FPS(720x1280) | FPS(540x960) |
|---|---|---|---|
| Facenet-Pytorch | 12.97 | 20.32 | 25.50 |
| FaceNet-Pytorch(非批处理) | 9.75 | 14.81 | 19.68 |
| Dlib | 3.80 | 8.39 | 14.53 |
| mtcnn | 3.04 | 5.70 | 8.23 |
请参阅Kaggle上的笔记本。
该算法通过利用相邻框架之间的相似性来演示如何在视频中专门实现非常有效的面部检测。
请参阅Kaggle上的笔记本。
软件包和任何示例笔记本可以使用Docker(或Nvidia-Docker)运行:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab 导航到示例/目录并运行任何IPYTHON笔记本电脑。
有关Docker容器的详细信息,请参见时代/Jupyter-DL-GPU。
要在您自己的git repo中使用此代码,我建议首先将此仓库添加为子模块。请注意,在以s子管子为克时,应删除存储库名称中的仪表板(' - '),因为导入时会破坏python:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
另外,可以使用PIP作为软件包安装代码:
pip install facenet-pytorch
请参阅:型号/utils/tensorflow2pytorch.py
请注意,不需要此功能即可使用此存储库中的模型,这仅取决于已保存的pytorch state_dict的s。
在实例化Pytorch模型后,每层的重量都是从Davidsandberg/FaceNet预验证的张量模型中的等效层加载的。
原始张量流模型和Pytorch型模型的输出的等效性已经进行了测试,并且是相同的:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
为了将Tensorflow参数重新运行到Pytorch模型中,请确保您用子模型克隆此存储库,因为将DavidSandberg/FaceNet Repo作为子模块包括在内,并且部分需要进行转换。
大卫·桑德伯格(David Sandberg
F. Schroff,D。Kalenichenko,J。Philbin。面部:面部识别和聚类的统一嵌入,ARXIV:1503.03832,2015。PDF
Q. Cao,L。Shen,W。Xie,Om Parkhi,A。Zisserman。 VGGFACE2:一个用于识别姿势和年龄面孔的数据集,2018年自动面部和手势识别国际会议。PDF
D. Yi,Z。Lei,S。Liao和Sz li。 casiawebface:从头开始学习面部表现,arxiv:1411.7923,2014。PDF
K. Zhang,Z. Zhang,Z。Li和Y. Qiao。使用多任务级联卷积网络的联合面部检测和对齐方式,IEEE信号处理信,2016年。PDF


