facenet pytorch
v2.5.3
يمكنك أيضًا قراءة نسخة مترجمة من هذا الملف باللغة الصينية 简体中文版.
هذا هو مستودع لنماذج RESNET (V1) Inception في Pytorch ، pretRained على VGGFAFC2 و Casia-Webface.
تم تهيئة أوزان نموذج Pytorch باستخدام معلمات تم نقلها من David Sandberg Tensorflow FaceNet Repo.
كما تم تضمينه في هذا الريبو هو تطبيق Pytorch فعال لـ MTCNN للكشف عن الوجه قبل الاستدلال. هذه النماذج هي أيضا ما قبل. على حد علمنا ، هذا هو أسرع تطبيق MTCNN المتاح.
ثَبَّتَ:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipythonفي Python ، استيراد النماذج FaceNet-Pytorch و Instantiate:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()معالجة صورة:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 )) انظر help(MTCNN) help(InceptionResnetV1) لتفاصيل الاستخدام والتنفيذ.
انظر: النماذج/inception_resnet_v1.py
تم نقل النماذج التالية إلى Pytorch (مع روابط لتنزيل Pytorch State_Dict's):
| اسم النموذج | دقة LFW (كما هو مدرج هنا) | مجموعة بيانات التدريب |
|---|---|---|
| 20180408-102900 (111 ميجابايت) | 0.9905 | Casia-Webface |
| 20180402-114759 (107MB) | 0.9965 | vggface2 |
ليست هناك حاجة لتنزيل state_dict المسبق يدويًا ؛ يتم تنزيلها تلقائيًا على مثيل النموذج وتخزين مؤقتًا للاستخدام في المستقبل في ذاكرة التخزين المؤقت للشكل. لاستخدام نموذج RESNET (V1) للبدء للتعرف على الوجه/تحديد الهوية في Pytorch ، استخدم:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()تم تدريب كلا النموذجين المسبق على صور 160 × 160 بكسل ، لذلك سيؤدي أفضل ما إذا تم تطبيقه على الصور المقيدة على هذا الشكل. للحصول على أفضل النتائج ، يجب أيضًا اقتصاص الصور على الوجه باستخدام MTCNN (انظر أدناه).
بشكل افتراضي ، ستعود النماذج أعلاه 512-التضمينات الأبعاد للصور. لتمكين التصنيف بدلاً من ذلك ، إما PASS classify=True إلى مُنشئ النموذج ، أو يمكنك تعيين سمة الكائن بعد ذلك باستخدام model.classify = True . بالنسبة لـ VGGFAFC2 ، سيقوم النموذج المسبق بإخراج ناقلات Logit ذات الطول 8631 ، وللحوافات Logit Casia-Webface ذات الطول 10575.
يمكن تطبيق التعرف على الوجه بسهولة على الصور الأولية عن طريق اكتشاف الوجوه أولاً باستخدام MTCNN قبل حساب التضمين أو الاحتمالات باستخدام نموذج RESNET Inception. يوفر رمز المثال في أمثلة/inpervy.IpyNB خط أنابيب مثال كامل باستخدام مجموعات البيانات ، dataloaders ، ومعالجة GPU اختيارية.
يمكن استخدام MTCNN لإنشاء نظام تتبع الوجه (باستخدام طريقة MTCNN.detect() ). يمكن العثور على مثال تتبع الوجه الكامل في أمثلة/face_tracking.ipynb.

في معظم المواقف ، تتمثل أفضل طريقة لتنفيذ التعرف على الوجه في استخدام النماذج المسبقة مباشرة ، إما مع خوارزمية التجميع أو مقاييس مسافة بسيطة لتحديد هوية الوجه. ومع ذلك ، إذا كان التهوية اللازمة (أي ، إذا كنت ترغب في تحديد الهوية بناءً على سجلات إخراج النموذج) ، فيمكن العثور على مثال على الأمثلة/finetune.ipynb.
يوضح هذا الدليل وظيفة وحدة MTCNN. الموضوعات المغطاة هي:
انظر دفتر الملاحظات على Kaggle.
يوضح هذا الكمبيوتر الدفتري استخدام ثلاث حزم اكتشاف الوجه:
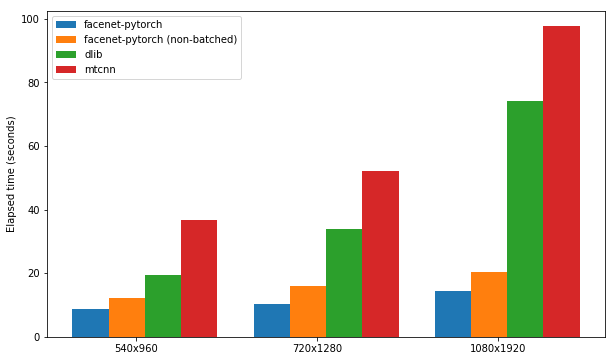
يتم اختبار كل حزمة لسرعتها في اكتشاف الوجوه في مجموعة من 300 صورة (جميع الإطارات من مقطع فيديو واحد) ، مع تمكين دعم GPU. يعتمد الأداء على Kaggle's P100 Notebook kernel. النتائج ملخصة أدناه.
| طَرد | FPS (1080x1920) | FPS (720 × 1280) | FPS (540x960) |
|---|---|---|---|
| FaceNet-Pytorch | 12.97 | 20.32 | 25.50 |
| FaceNet-Pytorch (غير مدفوعة) | 9.75 | 14.81 | 19.68 |
| Dlib | 3.80 | 8.39 | 14.53 |
| mtcnn | 3.04 | 5.70 | 8.23 |
انظر دفتر الملاحظات على Kaggle.
توضح هذه الخوارزمية كيفية تحقيق اكتشاف الوجه فعال للغاية على وجه التحديد في مقاطع الفيديو ، من خلال الاستفادة من أوجه التشابه بين الإطارات المجاورة.
انظر دفتر الملاحظات على Kaggle.
يمكن تشغيل الحزمة وأي أجهزة الكمبيوتر المحمولة على سبيل المثال باستخدام Docker (أو Nvidia-Docker) باستخدام:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab انتقل إلى الأمثلة/ الدليل وتشغيل أي من دفاتر Ipython.
انظر Timeler/Jupyter-DL-GPU للحصول على تفاصيل حاوية Docker.
لاستخدام هذا الرمز في ريبو GIT الخاص بك ، أوصي أولاً بإضافة هذا الريبو كوحدة فرعية. لاحظ أنه يجب إزالة اندفاعة ('-') في اسم الريبو عند الاستنساخ كوحدة فرعية لأنها ستحطم python عند الاستيراد:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
بدلاً من ذلك ، يمكن تثبيت الرمز كحزمة باستخدام PIP:
pip install facenet-pytorch
انظر: النماذج/utils/tensorflow2pytorch.py
لاحظ أن هذه الوظيفة ليست ضرورية لاستخدام النماذج في هذا الريبو ، والتي تعتمد فقط على Pytorch state_dict المحفوظ.
بعد تثبيت نموذج Pytorch ، تم تحميل أوزان كل طبقة من طبقات مكافئة في نماذج Tensorflow المسبقة من Davidsandberg/FaceNet.
تم اختبار معادلة المخرجات من نماذج TensorFlow الأصلية والنماذج المنبثقة Pytorch وهي متطابقة:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
من أجل إعادة تشغيل تحويل معلمات Tensorflow إلى نموذج Pytorch ، تأكد من استنساخ هذا الريبو مع العارض الفرعي ، حيث يتم تضمين Davidsandberg/FaceNet Respo كوحدة فرعية وأجزاء منه مطلوبة للتحويل.
David Sandberg's FaceNet: https://github.com/davidsandberg/facenet
F. Schroff ، D. Kalenichenko ، J. Philbin. FaceNet: تضمين موحد للتعرف على الوجه والتجميع ، Arxiv: 1503.03832 ، 2015.
Q. Cao ، L. Shen ، W. Xie ، Om Parkhi ، A. Zisserman. VGGFAFC2: مجموعة بيانات للتعرف على الوجه عبر العصر والعمر ، المؤتمر الدولي للوجه التلقائي والإيماءات ، 2018. PDF
D. Yi ، Z. Lei ، S. Liao and Sz Li. Casiawebface: تمثيل الوجه التعلم من الصفر ، Arxiv: 1411.7923 ، 2014. PDF
K. Zhang ، Z. Zhang ، Z. Li and Y. Qiao. الكشف عن الوجه المشترك ومحاذاة باستخدام شبكات تلافيفية متعددة المهام ، رسائل معالجة إشارة IEEE ، 2016. PDF


