facenet pytorch
v2.5.3
También puede leer una versión traducida de este archivo en chino 简体中文版.
Este es un repositorio para los modelos Inception ResNet (V1) en Pytorch, previamente en VGGFace2 y Casia-Webface.
Los pesos del modelo de Pytorch se inicializaron utilizando parámetros portados por el repositorio de Facenet TensorFlow de David Sandberg.
También se incluye en este repositorio una implementación eficiente de Pytorch de MTCNN para la detección de la cara antes de la inferencia. Estos modelos también están previos a la aparición. Hasta donde sabemos, esta es la implementación de MTCNN más rápida disponible.
Instalar:
# With pip:
pip install facenet-pytorch
# or clone this repo, removing the '-' to allow python imports:
git clone https://github.com/timesler/facenet-pytorch.git facenet_pytorch
# or use a docker container (see https://github.com/timesler/docker-jupyter-dl-gpu):
docker run -it --rm timesler/jupyter-dl-gpu pip install facenet-pytorch && ipythonEn Python, Import Facenet-Pytorch e instanciar modelos:
from facenet_pytorch import MTCNN , InceptionResnetV1
# If required, create a face detection pipeline using MTCNN:
mtcnn = MTCNN ( image_size = < image_size > , margin = < margin > )
# Create an inception resnet (in eval mode):
resnet = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()Procesar una imagen:
from PIL import Image
img = Image . open ( < image path > )
# Get cropped and prewhitened image tensor
img_cropped = mtcnn ( img , save_path = < optional save path > )
# Calculate embedding (unsqueeze to add batch dimension)
img_embedding = resnet ( img_cropped . unsqueeze ( 0 ))
# Or, if using for VGGFace2 classification
resnet . classify = True
img_probs = resnet ( img_cropped . unsqueeze ( 0 )) Consulte help(MTCNN) y help(InceptionResnetV1) para obtener detalles de uso e implementación.
Ver: Modelos/Inception_Resnet_V1.py
Los siguientes modelos se han portado a Pytorch (con enlaces para descargar pytorch state_dict's):
| Nombre del modelo | Precisión de LFW (como se enumera aquí) | Conjunto de datos de capacitación |
|---|---|---|
| 20180408-102900 (111 MB) | 0.9905 | Casia-Webface |
| 20180402-114759 (107Mb) | 0.9965 | VGGFACE2 |
No hay necesidad de descargar manualmente el estado previo al estado de state_dict; Se descargan automáticamente en la instanciación del modelo y se almacenan en caché para uso futuro en el caché de la antorcha. Para usar un modelo de resnet de inicio (V1) para el reconocimiento/identificación facial en Pytorch, use:
from facenet_pytorch import InceptionResnetV1
# For a model pretrained on VGGFace2
model = InceptionResnetV1 ( pretrained = 'vggface2' ). eval ()
# For a model pretrained on CASIA-Webface
model = InceptionResnetV1 ( pretrained = 'casia-webface' ). eval ()
# For an untrained model with 100 classes
model = InceptionResnetV1 ( num_classes = 100 ). eval ()
# For an untrained 1001-class classifier
model = InceptionResnetV1 ( classify = True , num_classes = 1001 ). eval ()Ambos modelos previos a la pretrada fueron entrenados en imágenes de 160x160 PX, por lo que funcionará mejor si se aplicarán a las imágenes redimensionadas a esta forma. Para obtener los mejores resultados, las imágenes también deben recortarse en la cara utilizando MTCNN (ver más abajo).
De forma predeterminada, los modelos anteriores devolverán 512 incrustaciones de imágenes. Para habilitar la clasificación, en su lugar, pase classify=True al Constructor del modelo, o puede establecer el atributo de objeto después con model.classify = True . Para VGGFACE2, el modelo previamente provocado emitirá vectores logit de longitud 8631, y para vectores logit de longitud de longitud Casia-Webface de longitud 10575.
El reconocimiento facial se puede aplicar fácilmente a las imágenes sin procesar mediante la detección de caras utilizando MTCNN antes de calcular la incrustación o las probabilidades utilizando un modelo de resnet de inicio. El código de ejemplo en ejemplos/infer.ipynb proporciona una tubería de ejemplo completa que utiliza conjuntos de datos, dataloaders y procesamiento opcional de GPU.
MTCNN se puede usar para construir un sistema de seguimiento facial (usando el método MTCNN.detect() ). Se puede encontrar un ejemplo de seguimiento de cara completa en ejemplos/face_tracking.ipynb.

En la mayoría de las situaciones, la mejor manera de implementar el reconocimiento facial es usar los modelos previos al estado previo directamente, ya sea un algoritmo de agrupación o métricas de distancia simples para determinar la identidad de una cara. Sin embargo, si se requiere Finetuning (es decir, si desea seleccionar identidad en función de los registros de salida del modelo), se puede encontrar un ejemplo en ejemplos/finetune.ipynb.
Esta guía demuestra la funcionalidad del módulo MTCNN. Los temas cubiertos son:
Vea el cuaderno en Kaggle.
Este cuaderno demuestra el uso de tres paquetes de detección de rostros:
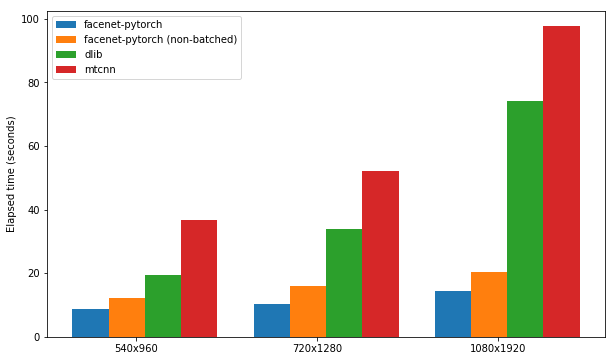
Cada paquete se prueba por su velocidad en la detección de las caras en un conjunto de 300 imágenes (todas las marcas de un video), con soporte de GPU habilitado. El rendimiento se basa en el kernel de cuaderno P100 de Kaggle. Los resultados se resumen a continuación.
| Paquete | FPS (1080x1920) | FPS (720x1280) | FPS (540x960) |
|---|---|---|---|
| facenet-pytorch | 12.97 | 20.32 | 25.50 |
| facenet-pytorch (no lotes) | 9.75 | 14.81 | 19.68 |
| dlib | 3.80 | 8.39 | 14.53 |
| mtcnn | 3.04 | 5.70 | 8.23 |
Vea el cuaderno en Kaggle.
Este algoritmo demuestra cómo lograr una detección de cara extremadamente eficiente específicamente en videos, aprovechando las similitudes entre los marcos adyacentes.
Vea el cuaderno en Kaggle.
El paquete y cualquiera de los cuadernos de ejemplo se puede ejecutar con Docker (o Nvidia-Docker) usando:
docker run --rm -p 8888:8888
-v ./facenet-pytorch:/home/jovyan timesler/jupyter-dl-gpu
-v < path to data > :/home/jovyan/data
pip install facenet-pytorch && jupyter lab Navegue a los ejemplos/ directorio y ejecute cualquiera de los cuadernos de Ipython.
Consulte Timesler/Jupyter-DL-GPU para los detalles del contenedor Docker.
Para usar este código en su propio Repo Git, recomiendo primero agregar este repositorio como un submódulo. Tenga en cuenta que el DASH ('-') en el nombre del repositorio debe eliminarse al clonarse como un submódulo, ya que romperá Python al importar:
git submodule add https://github.com/timesler/facenet-pytorch.git facenet_pytorch
Alternativamente, el código se puede instalar como un paquete utilizando PIP:
pip install facenet-pytorch
Consulte: Modelos/Utils/Tensorflow2pytorch.py
Tenga en cuenta que esta funcionalidad no es necesaria para usar los modelos en este repositorio, que dependen solo del state_dict de Pytorch guardado.
Después de la instanciación del modelo Pytorch, los pesos de cada capa se cargaron de capas equivalentes en los modelos de flujo de tensor de detención de Davidsandberg/Facenet.
Se ha probado la equivalencia de las salidas de los modelos TensorFlow originales y los modelos portados de Pytorch y son idénticos:
>>> compare_model_outputs(mdl, sess, torch.randn(5, 160, 160, 3).detach())
Passing test data through TF model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]])
Passing test data through PT model
tensor([[-0.0142, 0.0615, 0.0057, ..., 0.0497, 0.0375, -0.0838],
[-0.0139, 0.0611, 0.0054, ..., 0.0472, 0.0343, -0.0850],
[-0.0238, 0.0619, 0.0124, ..., 0.0598, 0.0334, -0.0852],
[-0.0089, 0.0548, 0.0032, ..., 0.0506, 0.0337, -0.0881],
[-0.0173, 0.0630, -0.0042, ..., 0.0487, 0.0295, -0.0791]],
grad_fn=<DivBackward0>)
Distance 1.2874517096861382e-06
Para volver a ejecutar la conversión de los parámetros de flujo de tensor en el modelo Pytorch, asegúrese de clonar este repositorio con submódulos , ya que el repositorio de Davidsandberg/Facenet se incluye como un submódulo y se requieren partes para la conversión.
Repo Facenet de David Sandberg: https://github.com/davidsandberg/facenet
F. Schroff, D. Kalenichenko, J. Philbin. Facenet: una incrustación unificada para el reconocimiento y la agrupación de la cara , ARXIV: 1503.03832, 2015. PDF
Q. Cao, L. Shen, W. Xie, Om Parkhi, A. Zisserman. VGGFACE2: Un conjunto de datos para reconocer la cara a través de Pose and Age , Conferencia Internacional sobre Reconocimiento Automático de la cara y Gestes, 2018. PDF
D. Yi, Z. Lei, S. Liao y Sz Li. Casiawebface: Learning Face Representation desde cero , ARXIV: 1411.7923, 2014. PDF
K. Zhang, Z. Zhang, Z. Li y Y. Qiao. Detección y alineación de la cara conjunta utilizando redes convolucionales en cascada multitarea , IEEE Signal Processing Letters, 2016. PDF


