simple faster rcnn pytorch
1.0.0
[更新:]我將代碼進一步簡化為Pytorch 1.5,Torchvision 0.6,然後用Torchvision替換自定義的OPS Roipool和NMS。如果您需要舊版本代碼,請簽出分支V1.0
該項目是基於ChainERCV和其他項目的簡化速度更快的R-CNN實現。我希望它可以作為想要了解更快R-CNN細節的人的開始代碼。它的目的是:
它具有以下功能:
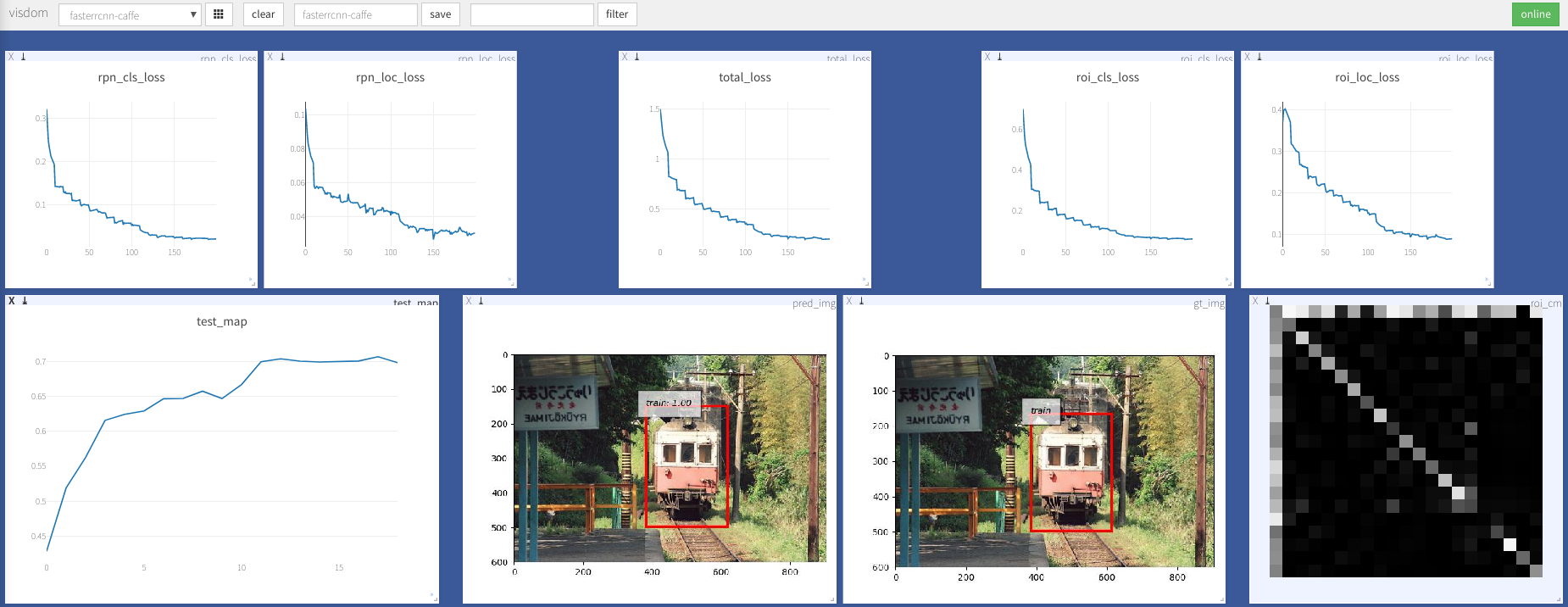
VGG16 trainval上的火車和test拆分測試。
注意:培訓表現出極大的隨機性,您可能需要一些運氣和更多的培訓時期才能達到最高地圖。但是,它應該很容易超過下限。
| 執行 | 地圖 |
|---|---|
| 起源紙 | 0.699 |
| 用咖啡館預算的模型訓練 | 0.700-0.712 |
| 用火炬訓練的訓練模型 | 0.685-0.701 |
| 從ChainERCV轉換的模型(報導0.706) | 0.7053 |
| 執行 | GPU | 推理 | 火車 |
|---|---|---|---|
| 起源紙 | K40 | 5 fps | na |
| 這個[1] | 泰坦XP | 14-15 fps | 6 fps |
| pytorch-faster-rcnn | 泰坦XP | 15-17fps | 6fps |
[1]:確保您正確安裝CUPY,並且在GPU上僅運行一個程序。訓練速度對您的GPU狀態很敏感。有關更多信息,請參見故障排除。此外,它在程序開始時很慢 - 它需要時間進行熱身。
通過刪除可視化,記錄,平均損失等,可能會更快。
這是用anaconda從頭開始創建環境的示例
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
如果您不使用Anaconda,則:
使用GPU安裝Pytorch(代碼僅GPU),請參閱官方網站
安裝其他依賴關係: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
開始視覺以進行可視化
nohup python -m visdom.server & 從Google Drive或Baidu NetDisk(PASSWD:SCXN)下載驗證的模型
有關更多詳細信息,請參見Demo.ipynb。
下載培訓,驗證,測試數據和VOCDEVKIT
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar將所有這些焦油提取到一個名為VOCdevkit的目錄中
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar它應該具有這種基本結構
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ...修改utils/config.py中的voc_data_dir CFG項目,或使用諸如--voc-data-dir=/path/to/VOCdevkit/VOC2007/參數傳遞給程序。
如果您想將CAFFE-PRORTRAIN模型用作初始權重,則可以在下面運行以從Caffe轉換為VGG16權重,這與原始紙張的使用相同。
python misc/convert_caffe_pretrain.py該腳本將下載驗證的模型,並將其轉換為與Torchvision兼容的格式。如果您在中國並且無法下載驗證碼模型,則可以參考此問題
然後,您可以通過設置caffe_pretrain_path來指定caffe-pretraind模型vgg16_caffe.pth存儲在utils/config.py中的位置。默認路徑還可以。
如果您想使用Torchvision預算的模型,則可以跳過此步驟。
注意,咖啡館預算的模型顯示出略有更好的性能。
注意:CAFFE模型需要BGR 0-255中的圖像,而Torchvision模型則需要RGB和0-1中的圖像。有關更多詳細信息,請參見data/dataset.py 。
python train.py train --env= ' fasterrcnn ' --plot-every=100您可以參考utils/config.py以獲取更多參數。
一些關鍵論點:
--caffe-pretrain=False :使用Caffe或Torchvision的預處理模型(默認:Torchvison)--plot-every=n :可視化預測,損失等n批次。--env :可視化的vivdom env--voc_data_dir :存儲VOC數據的位置--use-drop :在ROI頭中使用輟學,默認為false--use-Adam :使用ADAM代替SGD,默認SGD。 (您需要為亞當設置非常低的lr )--load-path :驗證的模型路徑,默認值None ,如果指定,則將加載。您可以打開瀏覽器,請訪問http://<ip>:8097 ,請參見以下培訓過程的可視化:
數據加載器: received 0 items of ancdata
參見討論,它是在train.py中固定的。因此,我認為您沒有這個問題。
Windows支持
我沒有帶有GPU的Windows Machine進行調試和測試。不客氣,如果有人可以提出請求並進行測試。
這項工作以許多出色的作品為基礎,其中包括:
根據MIT許可,請參閱許可證以獲取更多詳細信息。
歡迎捐款。
如果您遇到任何問題,請隨時打開一個問題,但最近太忙了。
如果有任何錯誤或不清楚的情況,請糾正我。
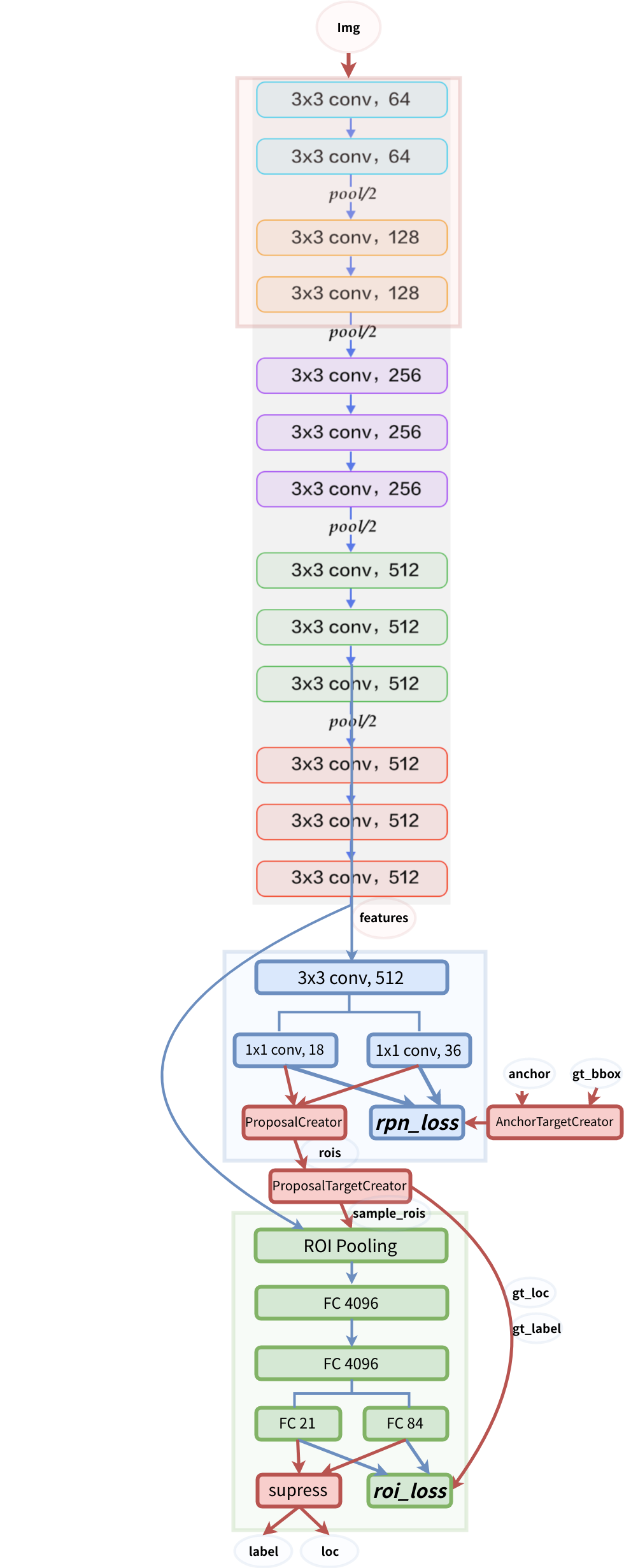
模型結構