simple faster rcnn pytorch
1.0.0
[Обновление:] Я дополнительно упростил код на Pytorch 1.5, Torchvision 0.6 и заменил индивидуальную Ops Roipool и NMS на то, что от Toothvision. Если вы хотите код старой версии, пожалуйста, загляните в филиал v1.0
Этот проект представляет собой упрощенную реализацию R-CNN на основе цепочки и других проектов. Я надеюсь, что это может служить кодом начала для тех, кто хочет узнать детали более быстрого R-CNN. Это направлено на:
И у него есть следующие функции:
VGG16 поезда на trainval и тестируйте на test разделении.
Примечание . Обучение показывает большую случайность, вам может потребоваться немного удачи и больше эпох тренировок, чтобы достичь самой высокой карты. Тем не менее, должно быть легко превзойти нижнюю границу.
| Выполнение | карта |
|---|---|
| Происхождение бумаги | 0,699 |
| Поезд с моделью с кофе | 0,700-0,712 |
| Поезд с предварительной моделью Torchvision | 0,685-0,701 |
| модель преобразована из цепного заведения (сообщено 0,706) | 0,7053 |
| Выполнение | Графический процессор | Вывод | Обучение |
|---|---|---|---|
| Происхождение бумаги | K40 | 5 кадров в секунду | НА |
| Это [1] | Титан XP | 14-15 кадров в секунду | 6 кадров в секунду |
| Pytorch-быстрее-Rcnn | Титан XP | 15-17 кадров в секунду | 6fps |
[1]: Убедитесь, что вы правильно установите Cupy, и только одна программа работает на GPU. Скорость обучения чувствительна к вашему статусу GPU. Смотрите устранение неполадок для получения дополнительной информации. Более того, это медленное в начале программы - ему нужно время, чтобы согреться.
Это может быть быстрее путем удаления визуализации, ведения журнала, усреднения потерь и т. Д.
Вот пример создания среды с нуля с anaconda
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
Если вы не используете Anaconda, то:
Установите Pytorch с помощью графического процессора (код только для графического процессора), см. Официальный веб-сайт
Установить другие зависимости: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
Начните визуализацию для визуализации
nohup python -m visdom.server & Скачать предварительную модель с Google Drive или Baidu NetDisk (Passwd: SCXN)
Смотрите Demo.ipynb для более подробной информации.
Загрузите обучение, проверку, тестовые данные и Vocdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar Извлеките все эти TARS в один каталог под названием VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarУ него должна быть эта основная структура
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... Измените voc_data_dir cfg элемент в utils/config.py или передайте его в программу, используя такие аргументы, как --voc-data-dir=/path/to/VOCdevkit/VOC2007/ .
Если вы хотите использовать модель Caffe-Pretrain в качестве начального веса, вы можете работать ниже, чтобы получить веса VGG16, преобразованные из Caffe, что совпадает с использованием источника.
python misc/convert_caffe_pretrain.pyЭти сценарии будут загружать предварительную модель и преобразовать ее в формат, совместимый с Torchvision. Если вы находитесь в Китае и не можете загрузить модель предварительного дорода, вы можете ссылаться на эту проблему
Затем вы можете указать, где Caffe-Pretraind Model vgg16_caffe.pth хранится в utils/config.py , установив caffe_pretrain_path . Путь по умолчанию в порядке.
Если вы хотите использовать предварительную модель из Torchvision, вы можете пропустить этот шаг.
Обратите внимание , что предварительная модель Caffe показала незначительную лучшую производительность.
Примечание . Модель CAFFE требует изображений в BGR 0-255, в то время как модель Torchvision требует изображений в RGB и 0-1. См. data/dataset.py для получения более подробной информации.
python train.py train --env= ' fasterrcnn ' --plot-every=100 Вы можете обратиться к utils/config.py для получения дополнительного аргумента.
Некоторые ключевые аргументы:
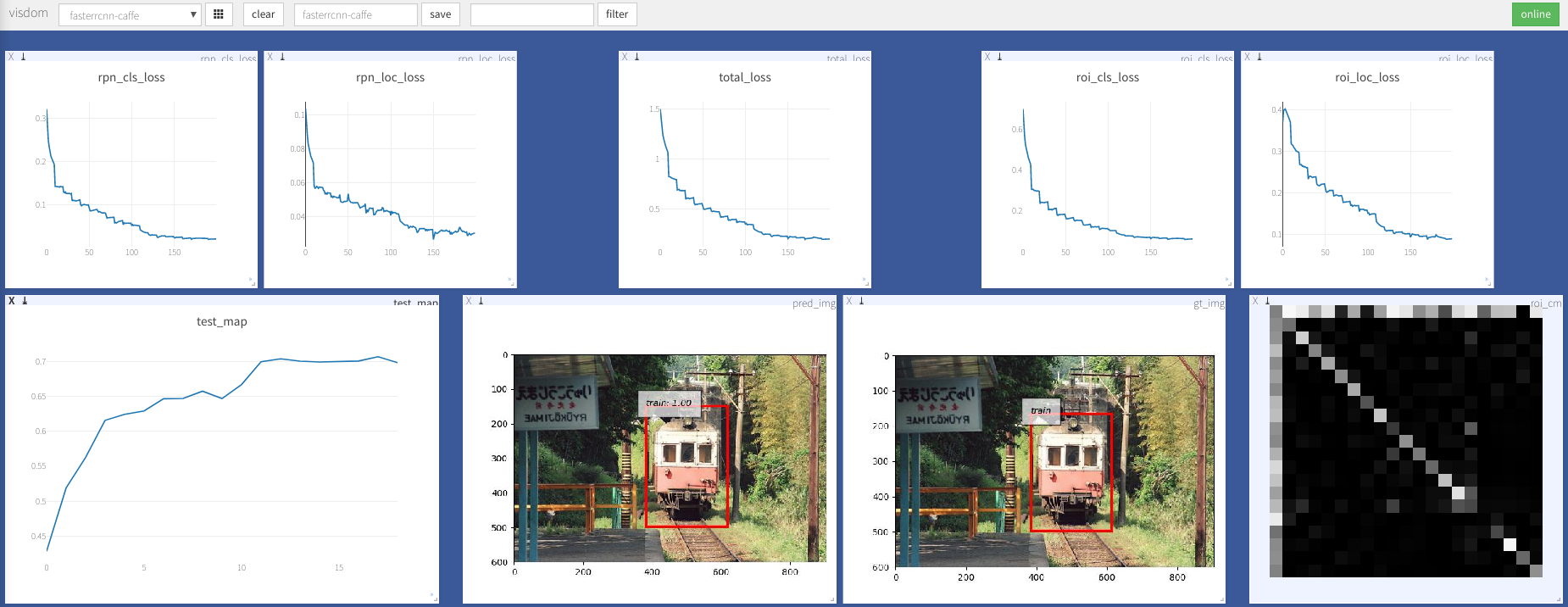
--caffe-pretrain=False : используйте модель предварительного положения из Caffe или Torchvision (по умолчанию: Torchvison)--plot-every=n : визуализируйте прогноз, потери и т. Д. Каждые n партии.--env : Visdom Env для визуализации--voc_data_dir : где хранятся данные VOC--use-drop : используйте выброс в roi Head, по умолчанию false--use-Adam : Используйте Адам вместо SGD, SGD по умолчанию. (Вам нужно установить очень низкий lr для Адама)--load-path : предварительный путь модели, по умолчанию None , если он указан, он будет загружен. Вы можете открыть браузер, посетить http://<ip>:8097 и увидеть визуализацию процедуры обучения, как ниже:
DataLoader: received 0 items of ancdata
См. Обсуждение, это Alreadly Ficking in train.py. Так что я думаю, что вы свободны от этой проблемы.
Поддержка Windows
У меня нет машины Windows с графическим процессором для отладки и проверки его. Это приветствуется, если кто -то может сделать запрос на привлечение и проверить его.
Эта работа основана на многих отличных работах, которые включают в себя:
Лицензировано в соответствии с MIT, см. Лицензию для более подробной информации.
Вклад приветствуется.
Если вы столкнетесь с какой -либо проблемой, не стесняйтесь открывать проблему, но в последнее время слишком заняты.
Поправьте меня, если что -то не так или неясно.
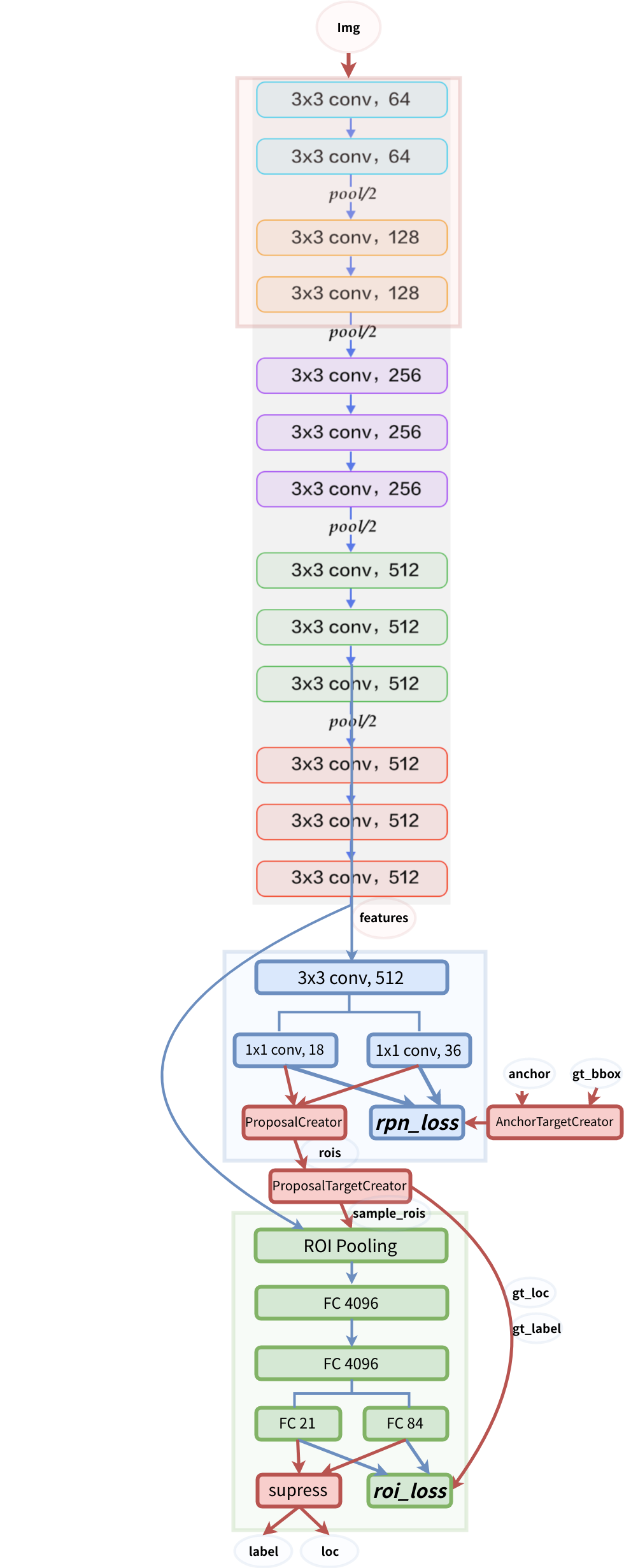
структура модели