simple faster rcnn pytorch
1.0.0
[ACTUALIZACIÓN:] He simplificado aún más el código a Pytorch 1.5, TorchVision 0.6 y reemplazar el OPS ROIPOOL y NMS personalizado con el de TorchVision. Si desea el código de versión anterior, consulte la rama v1.0
Este proyecto es una implementación de R-CNN más rápida simplificada basada en CainCRV y otros proyectos. Espero que pueda servir como un código de inicio para aquellos que desean conocer los detalles de R-CNN más rápido. Su objetivo es:
Y tiene las siguientes características:
VGG16 Tren en trainval y prueba en la división test .
Nota : El entrenamiento muestra una gran aleatoriedad, es posible que necesite un poco de suerte y más épocas de entrenamiento para alcanzar el mapa más alto. Sin embargo, debería ser fácil superar el límite inferior.
| Implementación | mapa |
|---|---|
| papel de origen | 0.699 |
| Entrena con modelo de caffe | 0.700-0.712 |
| tren con modelo de vape de antorchas | 0.685-0.701 |
| Modelo convertido de ChainerCV (informado 0.706) | 0.7053 |
| Implementación | GPU | Inferencia | Entrenamiento |
|---|---|---|---|
| papel de origen | K40 | 5 fps | N / A |
| Esto [1] | Titan XP | 14-15 fps | 6 fps |
| Pytorch-Faster-Rcnn | Titan XP | 15-17 fps | 6 fps |
[1]: asegúrese de instalar Cupy correctamente y solo un programa se ejecuta en la GPU. La velocidad de entrenamiento es sensible al estado de su GPU. Vea la solución de problemas para obtener más información. Morever es lento al comienzo del programa: necesita tiempo para calentarse.
Podría ser más rápido eliminando la visualización, la registro, el promedio de la pérdida, etc.
Aquí hay un ejemplo de creación ambiente desde cero con anaconda
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
Si no usa Anaconda, entonces:
Instalar Pytorch con GPU (el código es solo de GPU), consulte el sitio web oficial
Instale otras dependencias: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
Comience a Visdom para su visualización
nohup python -m visdom.server & Descargue el modelo previo a Google Drive o Baidu NetDisk (PASSWD: SCXN)
Ver Demo.ipynb para obtener más detalles.
Descargue la capacitación, validación, datos de prueba y vocdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar Extraiga todos estos alquitrán en un directorio llamado VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarDebería tener esta estructura básica
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... Modifique el elemento voc_data_dir CFG en utils/config.py , o pase para programar usando argumentos como --voc-data-dir=/path/to/VOCdevkit/VOC2007/ .
Si desea utilizar el modelo Caffe-Pretrain como peso inicial, puede ejecutar a continuación para obtener los pesos VGG16 convertidos de Caffe, que es lo mismo que el uso de papel de origen.
python misc/convert_caffe_pretrain.pyEstos scripts descargarían el modelo previamente y lo convertirían en el formato compatible con TorchVision. Si está en China y no puede descargar el modelo Pretrain, puede consultar este tema
Luego, puede especificar dónde el modelo Caffe-Pretraind vgg16_caffe.pth almacenado en utils/config.py configurando caffe_pretrain_path . La ruta predeterminada está bien.
Si desea utilizar el modelo previo a la vía previa de TorchVision, puede omitir este paso.
Tenga en cuenta que el modelo de caffe previamente ha mostrado un ligero mejor rendimiento.
Nota : El modelo CAFFE requiere imágenes en BGR 0-255, mientras que el modelo TorchVision requiere imágenes en RGB y 0-1. Consulte data/dataset.py para obtener más detalles.
python train.py train --env= ' fasterrcnn ' --plot-every=100 Puede consultar utils/config.py para obtener más argumentos.
Algunos argumentos clave:
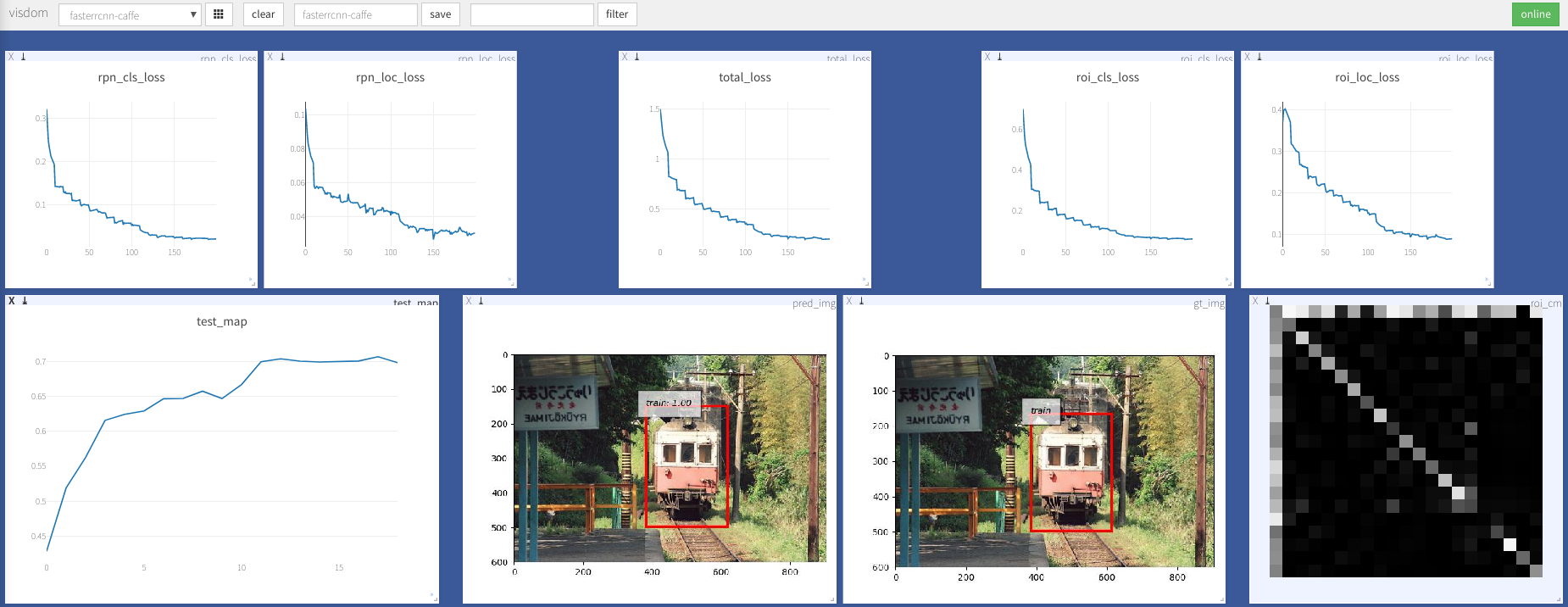
--caffe-pretrain=False : use el modelo de pretrin de cafe o antorchvision (predeterminado: torcedvison)--plot-every=n : visualizar la predicción, la pérdida, etc. cada n lotes.--env : Visdom env para visualización--voc_data_dir : donde se almacenan los datos de VOC--use-drop : use la descarga en la cabeza de ROI, falso predeterminado--use-Adam : use Adam en lugar de SGD, SGD predeterminado. (Necesitas establecer un lr muy bajo para Adam)--load-path : ruta del modelo previamente, predeterminado None , si se especifica, se cargaría. Puede abrir el navegador, visitar http://<ip>:8097 y ver la visualización del procedimiento de capacitación como se muestra a continuación:
Dataloader: received 0 items of ancdata
Vea la discusión, se fija en Train.py. Así que creo que estás libre de este problema.
Soporte de Windows
No tengo Windows Machine con GPU para depurarla y probarla. Es bienvenido si alguien pudiera hacer una solicitud de extracción y probarla.
Este trabajo se basa en muchas obras excelentes, que incluyen:
Licenciado bajo MIT, vea la licencia para obtener más detalle.
Contribución bienvenida.
Si encuentra algún problema, no dude en abrir un problema, pero demasiado ocupado últimamente.
Corrígeme si algo está mal o no está claro.
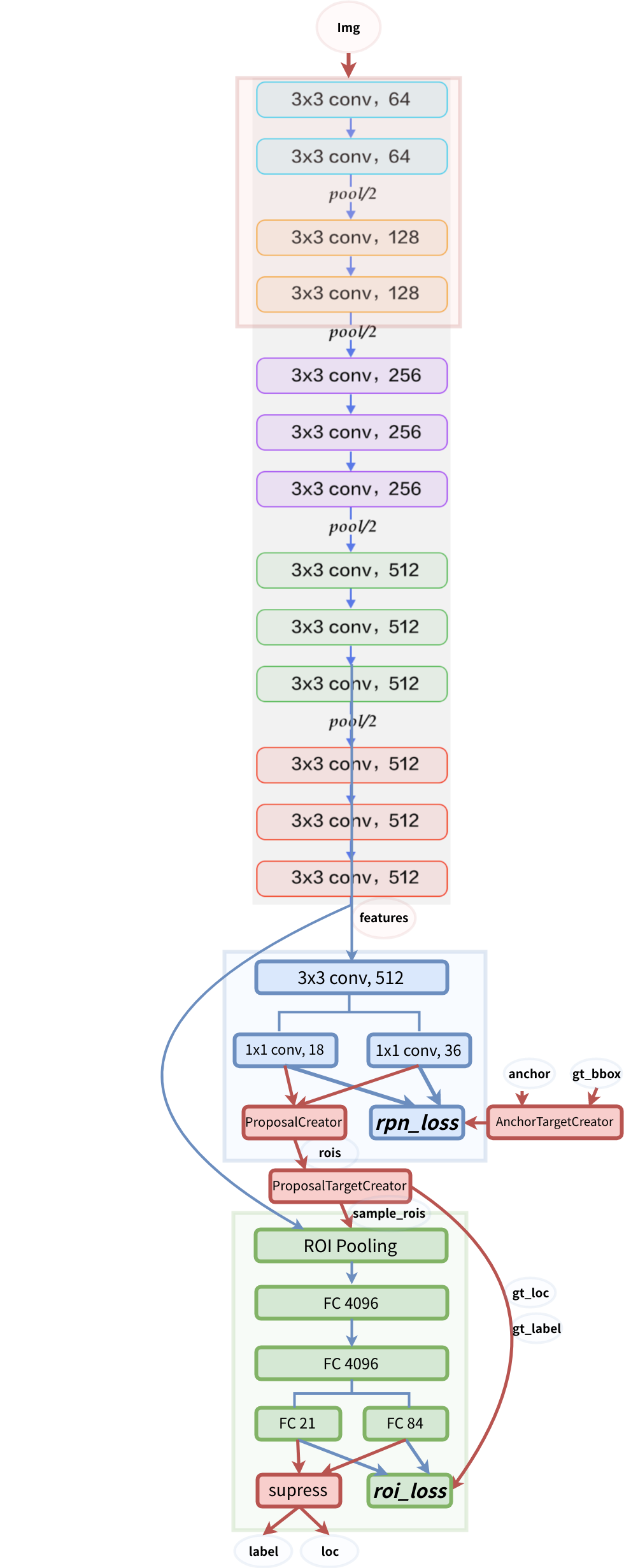
estructura modelo