simple faster rcnn pytorch
1.0.0
[更新:]さらにコードをPytorch 1.5、Torchvision 0.6に簡素化し、カスタマイズされたOps RoipoolとNMSをTorchvisionのものに置き換えました。古いバージョンコードが必要な場合は、ブランチv1.0をチェックアウトしてください
このプロジェクトは、ChainERCVおよびその他のプロジェクトに基づいた簡素化された高速のR-CNN実装です。より高速なR-CNNの詳細を知りたい人のための開始コードとして役立つことを願っています。それは次のことを目指しています:
そして、それには次の機能があります:
vgg16 trainvalで列車とtest分割でテストします。
注:トレーニングには大きなランダム性が示されています。最高のマップに到達するには、少し運とトレーニングのエポックが必要になる場合があります。ただし、下限を超えるのは簡単なはずです。
| 実装 | 地図 |
|---|---|
| 起源の論文 | 0.699 |
| Caffe Treaded Modelでトレーニングします | 0.700-0.712 |
| Torchvisionの前のモデルでトレーニングします | 0.685-0.701 |
| ChainERCVから変換されたモデル(報告された0.706) | 0.7053 |
| 実装 | GPU | 推論 | トレーニング |
|---|---|---|---|
| 起源の論文 | K40 | 5 fps | Na |
| これ[1] | タイタンXP | 14-15 fps | 6 fps |
| pytorch-faster-rcnn | タイタンXP | 15-17fps | 6fps |
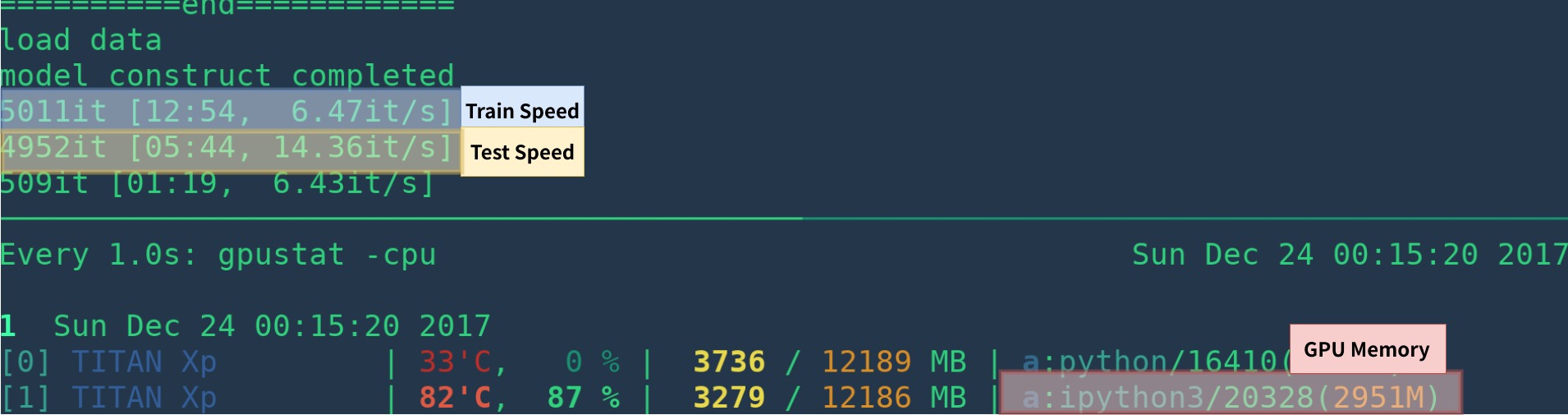
[1]:Cupyを正しくインストールし、GPUで実行されるプログラムは1つだけインストールしてください。トレーニング速度は、GPUステータスに敏感です。詳細については、トラブルシューティングを参照してください。さらに、プログラムの開始時は遅いです - ウォームアップするには時間が必要です。
視覚化、ロギング、平均損失などを削除することにより、より速くなる可能性があります。
anacondaと一緒にゼロから環境を作成する例は次のとおりです
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
アナコンダを使用しない場合は、
GPU(コードはGPUのみです)にPytorchをインストールするには、公式Webサイトを参照してください
その他の依存関係をインストール: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
視覚化のために目を開始します
nohup python -m visdom.server & Google DriveまたはBaidu Netdisk(PassWD:SCXN)から事前に守られたモデルをダウンロードしてください
詳細については、demo.ipynbを参照してください。
トレーニング、検証、テストデータ、Vocdevkitをダウンロードします
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tarこれらすべてのタールをVOCdevkitという名前の1つのディレクトリに抽出します
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarこの基本構造が必要です
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... utils/config.pyのvoc_data_dir cfgアイテムを変更するか、 --voc-data-dir=/path/to/VOCdevkit/VOC2007/のような引数を使用してプログラムに渡します。
Caffe-Pretrainモデルを初期重量として使用する場合は、以下で実行して、Origin Paperの使用と同じCaffeから変換されるVGG16の重みを取得できます。
python misc/convert_caffe_pretrain.pyこのスクリプトは、前処理されたモデルをダウンロードし、TorchVisionと互換性のある形式に変換します。あなたが中国にいて、プレレインモデルをダウンロードできない場合は、この問題を参照することができます
次に、 caffe_pretrain_pathを設定して、 utils/config.pyで保存されているCaffe-pretraindモデルvgg16_caffe.pth指定できます。デフォルトのパスはOKです。
Torchvisionの前提型モデルを使用する場合は、この手順をスキップできます。
注意してください、Caffe Tretrained Modelのパフォーマンスがわずかに優れていることに注意してください。
注:CaffeモデルにはBGR 0-255の画像が必要ですが、TorchvisionモデルではRGBと0-1の画像が必要です。詳細については、 data/dataset.pyを参照してください。
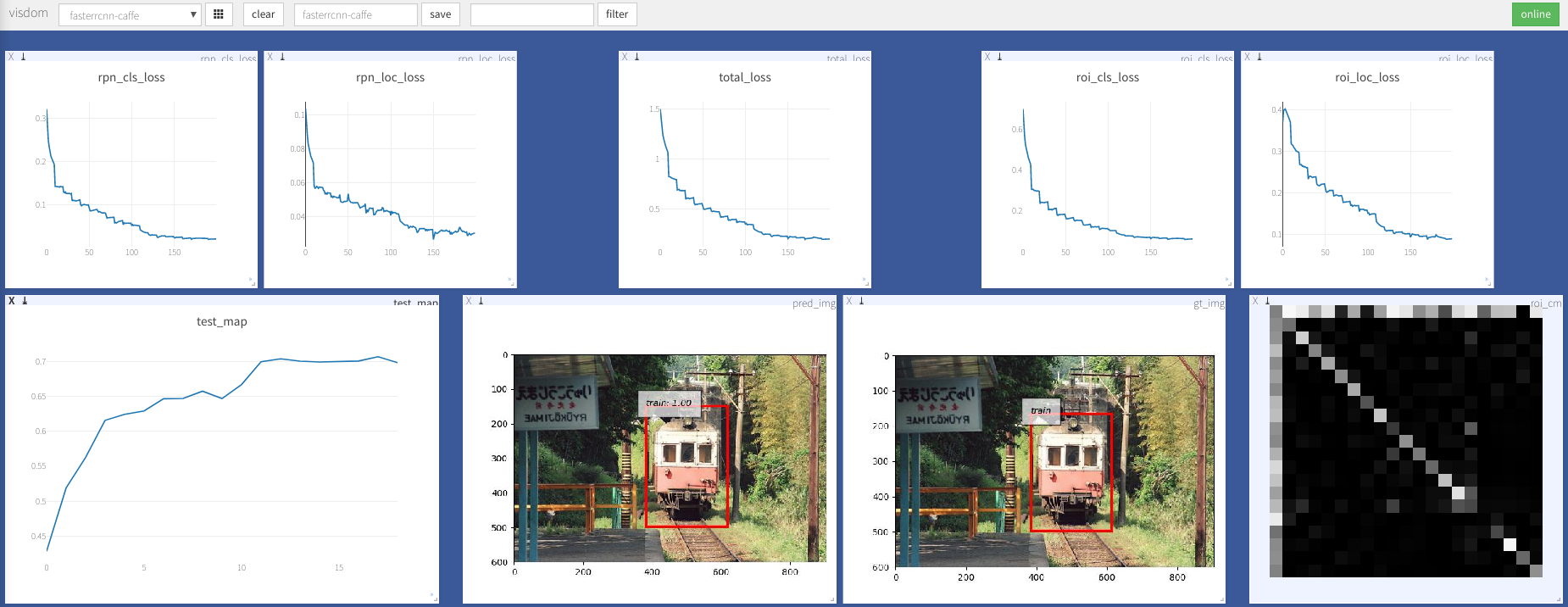
python train.py train --env= ' fasterrcnn ' --plot-every=100より多くの引数についてはutils/config.pyを参照できます。
いくつかの重要な議論:
--caffe-pretrain=False :CaffeまたはTorchvisionのプレレインモデルを使用します(デフォルト:Torchvison)--plot-every=n :すべてのnバッチを視覚化、損失などを視覚化します。--env :視覚化のvisom env--voc_data_dir :VOCデータが保存されている場所--use-drop :ROIヘッドでドロップアウトを使用し、デフォルトのFalseを使用します--use-Adam :SGDの代わりにADAMを使用します。デフォルトSGD。 (アダムのために非常に低いlrを設定する必要があります)--load-path :前処理されたモデルパス、デフォルトNone 、指定されている場合、ロードされます。ブラウザを開いて、 http://<ip>:8097にアクセスして、以下のトレーニング手順の視覚化をご覧ください。
Dataloader: received 0 items of ancdata
議論を参照してください、それはTrain.pyですべて読みにも修正されています。ですから、あなたはこの問題から解放されていると思います。
Windowsサポート
GPUを備えたWindowsマシンは、デバッグしてテストしていません。誰かがプルリクエストを行い、それをテストできれば歓迎されます。
この作品は、以下を含む多くの優れた作品に基づいています。
MITでライセンスを取得して、詳細についてはライセンスを参照してください。
貢献を歓迎します。
問題が発生した場合は、お気軽に問題を開いてください。最近は忙しすぎてください。
何かが間違っているか、不明確である場合は修正してください。
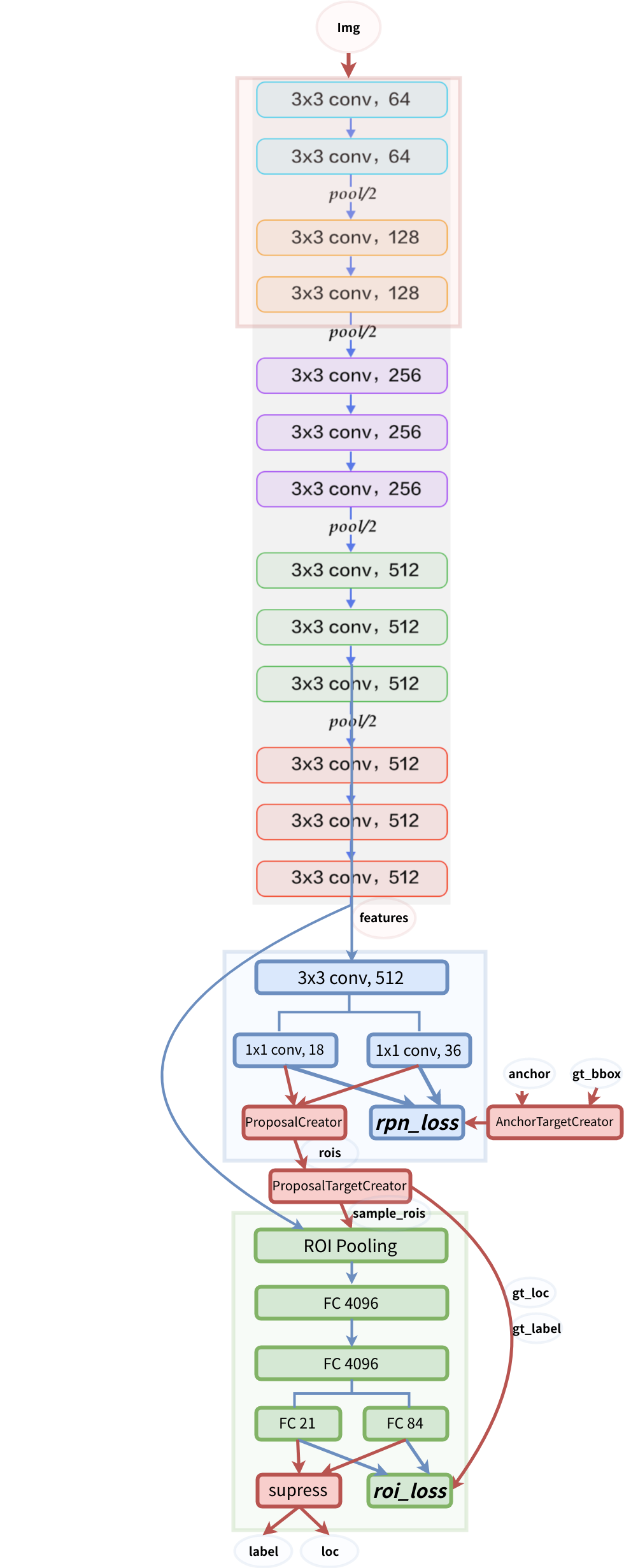
モデル構造