simple faster rcnn pytorch
1.0.0
[ATUALIZAÇÃO:] Simplifiquei ainda mais o código para Pytorch 1.5, Torchvision 0.6 e substituo o OPS ROIPOOL e NMS personalizados pelo Torchvision. Se você deseja o código da versão antiga, consulte o ramo v1.0
Este projeto é uma implementação R-CNN mais rápida simplificada , baseada no ChelaRERCV e em outros projetos. Espero que possa servir como um código de início para quem deseja conhecer os detalhes de R-CNN mais rápido. Pretende:
E tem os seguintes recursos:
VGG16 Trem em trainval e teste na divisão test .
NOTA : O treinamento mostra grande aleatoriedade, você pode precisar de um pouco de sorte e mais épocas de treinamento para alcançar o mapa mais alto. No entanto, deve ser fácil superar o limite inferior.
| Implementação | mapa |
|---|---|
| papel de origem | 0,699 |
| Treine com o modelo pré -terenciado de Caffe | 0,700-0.712 |
| Treine com o modelo pré -terenciado Torchvision | 0,685-0.701 |
| Modelo convertido do ChelaRCV (relatado 0,706) | 0,7053 |
| Implementação | GPU | Inferência | Treinando |
|---|---|---|---|
| papel de origem | K40 | 5 fps | N / D |
| Isso [1] | Titan XP | 14-15 fps | 6 fps |
| Pytorch-Fast-RCNN | Titan XP | 15-17fps | 6fps |
[1]: Certifique -se de instalar o Cupy corretamente e apenas um programa executado na GPU. A velocidade de treinamento é sensível ao seu status de GPU. Consulte Solução de problemas para obter mais informações. Além disso, é lento no início do programa - ele precisa de tempo para se aquecer.
Pode ser mais rápido removendo a visualização, a extração de madeira, a perda média etc.
Aqui está um exemplo de Criar Environ do zero com anaconda
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
Se você não usa Anaconda, então:
Instale o Pytorch com a GPU (o código é somente GPU), consulte o site oficial
Instale outras dependências: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
Comece o visdom para visualização
nohup python -m visdom.server & Faça o download do modelo pré -terenciado do Google Drive ou Baidu NetDisk (Passwd: SCXN)
Veja Demo.ipynb para obter mais detalhes.
Faça o download do treinamento, validação, dados de teste e vocdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar Extraia todos esses alcatrões em um diretório chamado VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarDeve ter essa estrutura básica
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... modificar voc_data_dir cfg item em utils/config.py , ou passe para programar usando argumento como --voc-data-dir=/path/to/VOCdevkit/VOC2007/ .
Se você deseja usar o modelo de pré-fixação do Caffe como peso inicial, pode ser executado abaixo para que os pesos VGG16 convertidos da Caffe, o que é o mesmo que o uso do papel de origem.
python misc/convert_caffe_pretrain.pyEsses scripts baixam o modelo pré -terenciado e o converteriam no formato compatível com a Torchvision. Se você estiver na China e não pode baixar o modelo de pré -train, pode se referir a este problema
Em seguida, você pode especificar onde o modelo CAFFE-PRETRAIND vgg16_caffe.pth armazenado no utils/config.py definindo caffe_pretrain_path . O caminho padrão está ok.
Se você deseja usar o modelo pré -terenciado da Torchvision, poderá pular esta etapa.
Observe que o modelo pré -terenciado de Caffe mostrou um pequeno desempenho melhor.
NOTA : O modelo Caffe requer imagens no BGR 0-255, enquanto o modelo de tocisão requer imagens em RGB e 0-1. Consulte data/dataset.py para obter mais detalhes.
python train.py train --env= ' fasterrcnn ' --plot-every=100 Você pode se referir a utils/config.py para obter mais argumentos.
Alguns argumentos -chave:
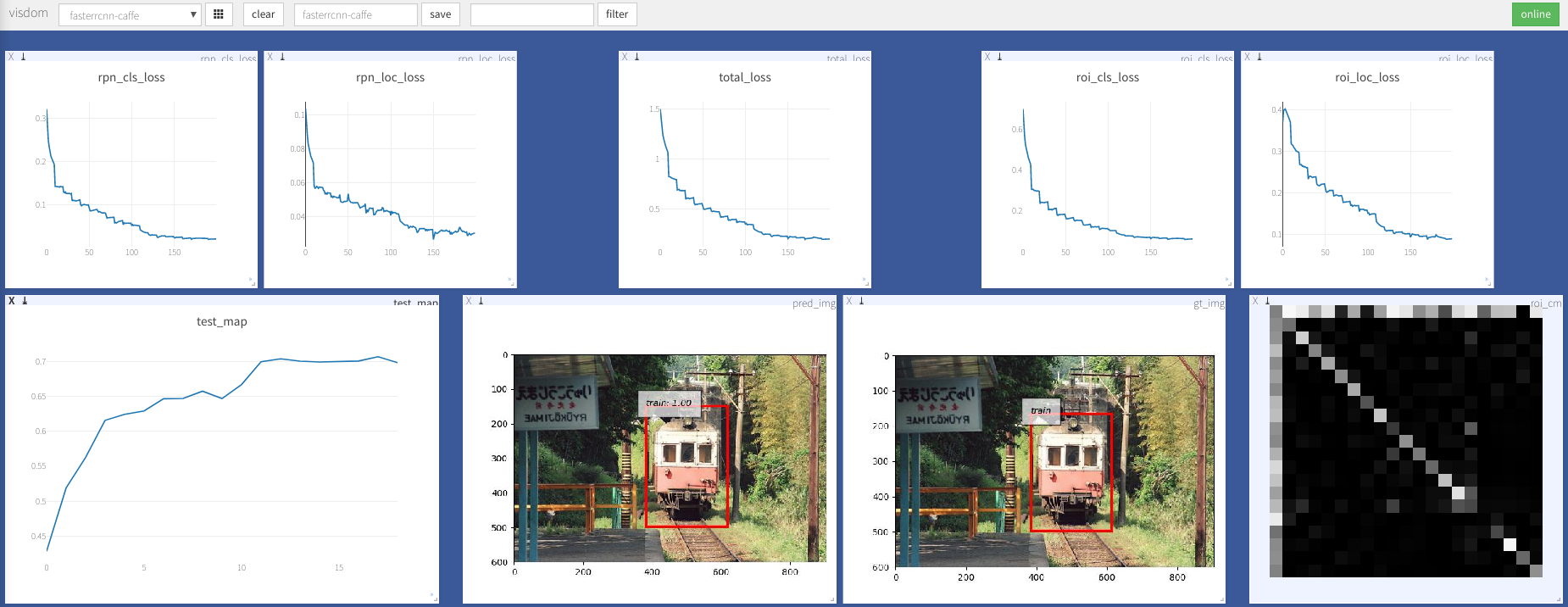
--caffe-pretrain=False : use o modelo de pré-train de Caffe ou Torchvision (Padrão: Torchvison)--plot-every=n : visualize previsão, perda etc. todos os n lotes n.--env : Visdom Env para visualização--voc_data_dir : onde os dados VOC armazenados--use-drop : Use o abandono do ROI Head, padrão false--use-Adam : Use Adam em vez de SGD, SGD padrão. (Você precisa definir um lr muito baixo para Adam)--load-path : caminho do modelo pré-terenciado, padrão None , se for especificado, seria carregado. Você pode abrir o navegador, visite http://<ip>:8097 e ver a visualização do procedimento de treinamento como abaixo:
Dataloader: received 0 items of ancdata
Veja a discussão, está totalmente corrigido em trem.py. Então eu acho que você está livre desse problema.
Suporte ao Windows
Não tenho Windows Machine com GPU para depurar e testá -la. É bem -vindo se alguém puder fazer uma solicitação de tração e testá -lo.
Este trabalho se baseia em muitos trabalhos excelentes, que incluem:
Licenciado no MIT, consulte a licença para obter mais detalhes.
Contribuição bem -vinda.
Se você encontrar algum problema, fique à vontade para abrir um problema, mas muito ocupado ultimamente.
Corrija -me se alguma coisa estiver errada ou pouco clara.
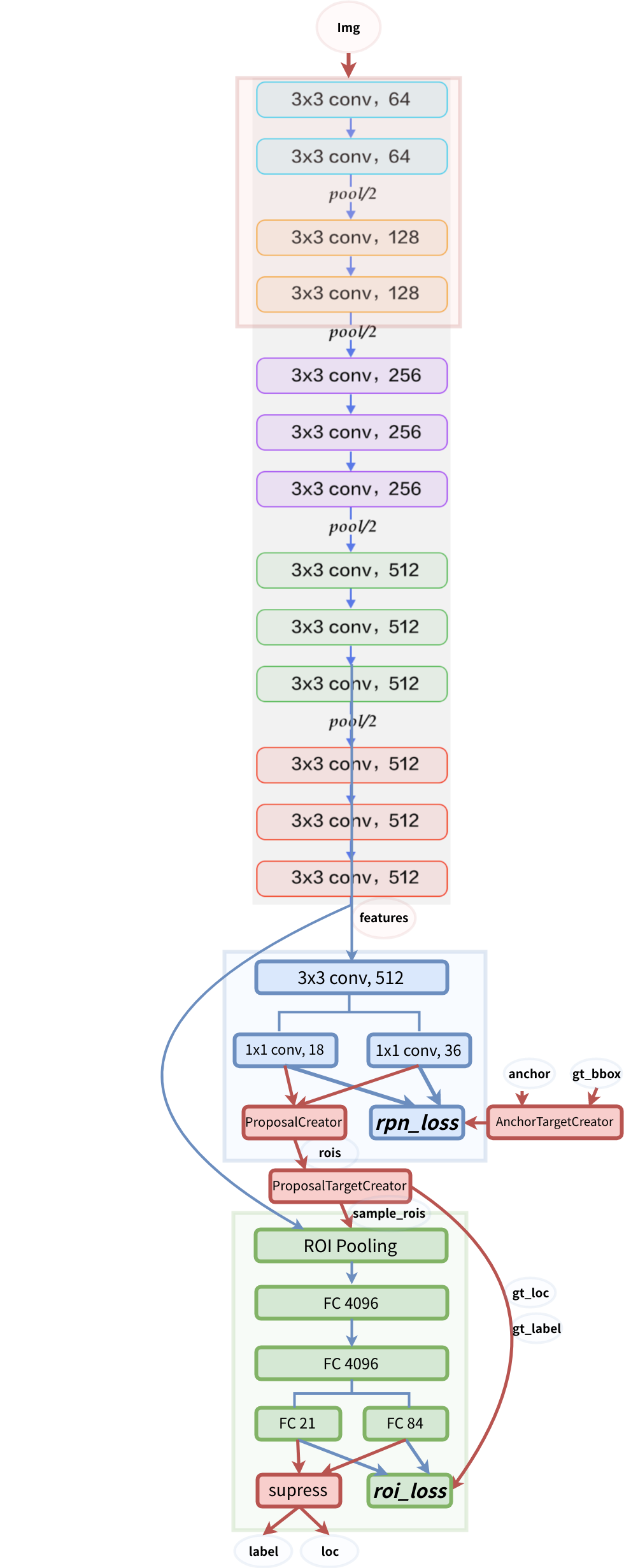
Estrutura do modelo