simple faster rcnn pytorch
1.0.0
[MISE À JOUR:] J'ai encore simplifié le code à Pytorch 1.5, TorchVision 0.6, et remplacé le Roipool et NMS personnalisés par celui de TorchVision. Si vous voulez l'ancien code de version, veuillez vérifier la branche v1.0
Ce projet est une implémentation R-CNN simplifiée plus rapide basée sur CRÉRERCV et d'autres projets. J'espère que cela peut servir de code de démarrage pour ceux qui veulent connaître le détail de R-CNN plus rapide. Il vise à:
Et il a les fonctionnalités suivantes:
Train VGG16 sur trainval et test sur test Split.
Remarque : La formation montre un grand aléatoire, vous pourriez avoir besoin d'un peu de chance et plus d'époches de formation pour atteindre la plus haute carte. Cependant, il devrait être facile de dépasser la limite inférieure.
| Mise en œuvre | carte |
|---|---|
| papier d'origine | 0,699 |
| s'entraîner avec le modèle pré-entraîné CAFFE | 0,700-0,712 |
| Train avec un modèle TorchVision pré-entraîné | 0,685-0,701 |
| modèle converti à partir de CRUERERCV (rapporté 0,706) | 0,7053 |
| Mise en œuvre | GPU | Inférence | Standing |
|---|---|---|---|
| papier d'origine | K40 | 5 ips | N / A |
| Ce [1] | Titan XP | 14-15 ips | 6 ips |
| pytorch-faster-rcnn | Titan XP | 15-17fps | 6FPS |
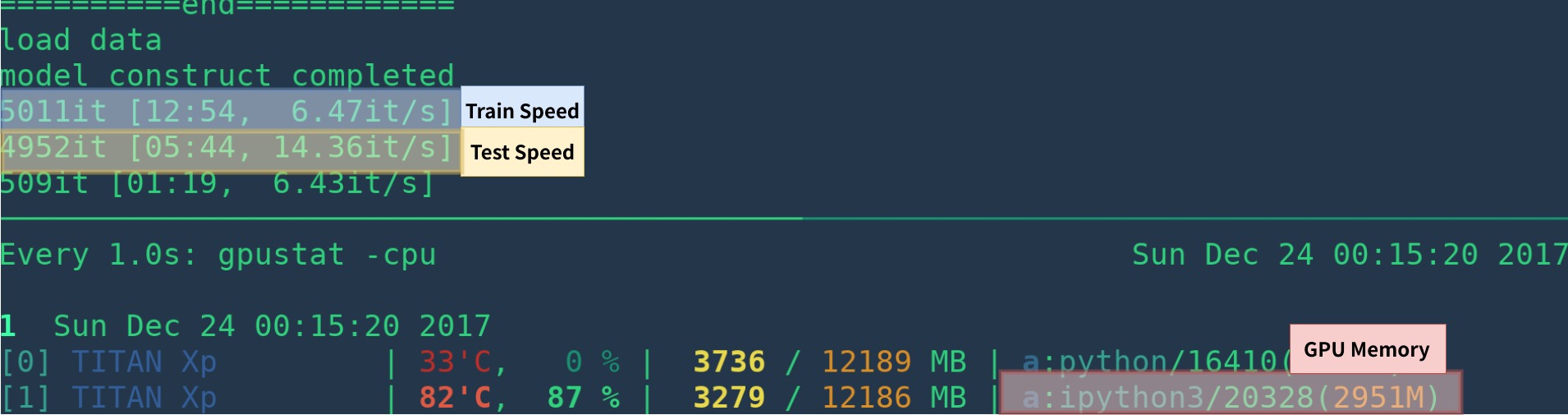
[1]: Assurez-vous d'installer correctement Cupy et qu'un seul programme s'exécute sur le GPU. La vitesse d'entraînement est sensible à votre statut de GPU. Voir le dépannage pour plus d'informations. De plus, c'est lent au début du programme - il a besoin de temps pour se réchauffer.
Cela pourrait être plus rapide en supprimant la visualisation, l'exploitation forestière, la moyenne des pertes, etc.
Voici un exemple de Create Environ à partir de zéro avec anaconda
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
Si vous n'utilisez pas Anaconda, alors:
Installez Pytorch avec GPU (le code est GPU uniquement), reportez-vous au site officiel
Installer d'autres dépendances: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
Commencez le Visdom pour la visualisation
nohup python -m visdom.server & Téléchargez le modèle pré-entraîné à partir de Google Drive ou Baidu Netdisk (PASSWD: SCXN)
Voir Demo.ipynb pour plus de détails.
Téléchargez la formation, la validation, les données de test et le vocdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar Extraire tous ces goudrons en un seul répertoire nommé VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarIl devrait avoir cette structure de base
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... Modifiez voc_data_dir CFG Élément dans utils/config.py , ou passez-le au programme en utilisant un argument comme --voc-data-dir=/path/to/VOCdevkit/VOC2007/ .
Si vous souhaitez utiliser le modèle de prétraitement CAFFE comme poids initial, vous pouvez fonctionner ci-dessous pour faire convertir les poids VGG16 à partir de Caffe, ce qui est le même que l'utilisation du papier d'origine.
python misc/convert_caffe_pretrain.pyCes scripts téléchargeraient le modèle pré-entraîné et le convertiraient au format compatible avec TorchVision. Si vous êtes en Chine et que vous ne pouvez pas télécharger le modèle Pretrain, vous pouvez vous référer à ce problème
Ensuite, vous pouvez spécifier où Caffe-Pretraind Model vgg16_caffe.pth stocké dans utils/config.py en définissant caffe_pretrain_path . Le chemin par défaut est ok.
Si vous souhaitez utiliser un modèle pré-entraîné depuis TorchVision, vous pouvez ignorer cette étape.
Remarque , le modèle pré-entraîné de la CAFE a montré de légères meilleures performances.
Remarque : le modèle de CAFE nécessite des images dans BGR 0-255, tandis que le modèle TorchVision nécessite des images en RVB et 0-1. Voir data/dataset.py pour plus de détails.
python train.py train --env= ' fasterrcnn ' --plot-every=100 Vous pouvez vous référer à utils/config.py pour plus d'argument.
Quelques arguments clés:
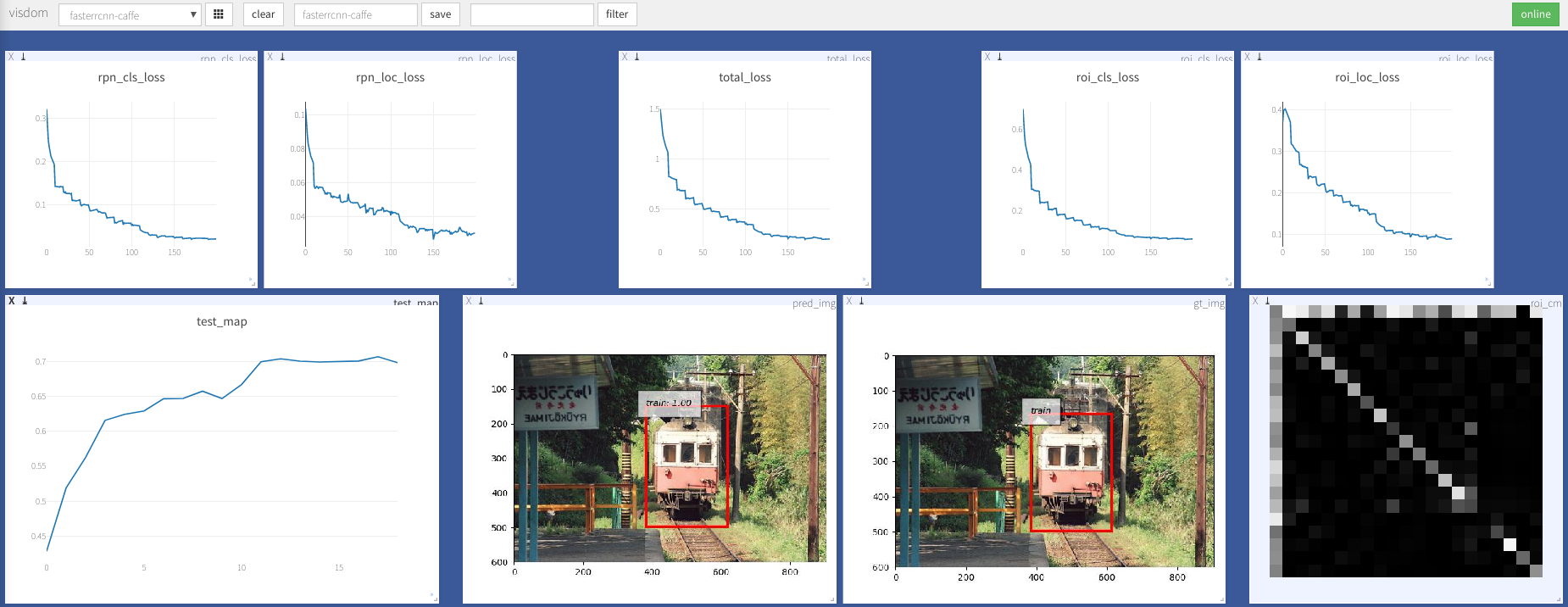
--caffe-pretrain=False : Utilisez le modèle Pretrain à partir de Caffe ou TorchVision (par défaut: Torchvison)--plot-every=n : visualiser la prédiction, la perte, etc. tous n lots.--env : Visdom Env pour la visualisation--voc_data_dir : où les données de COV stockées--use-drop : utilisez un abandon dans le ROI Head, par défaut faux--use-Adam : utilisez Adam au lieu de SGD, SGD par défaut. (Vous avez besoin de définir un lr très bas pour Adam)--load-path : Path du modèle pré-entraîné, par défaut None , s'il est spécifié, il serait chargé. Vous pouvez ouvrir un navigateur, visiter http://<ip>:8097 et voir la visualisation de la procédure de formation comme ci-dessous:
DatalOader: received 0 items of ancdata
Voir la discussion, il est bien fixé dans Train.py. Je pense donc que vous êtes libre de ce problème.
Prise en charge de Windows
Je n'ai pas de machine Windows avec GPU pour déboguer et la tester. Il est le bienvenu que quelqu'un puisse faire une demande de traction et le tester.
Ce travail s'appuie sur de nombreuses excellentes œuvres, notamment:
Licencié dans le cadre du MIT, voir la licence pour plus de détails.
Contribution bienvenue.
Si vous rencontrez un problème, n'hésitez pas à ouvrir un problème, mais trop occupé ces derniers temps.
Corrigez-moi si quelque chose est mal ou peu clair.
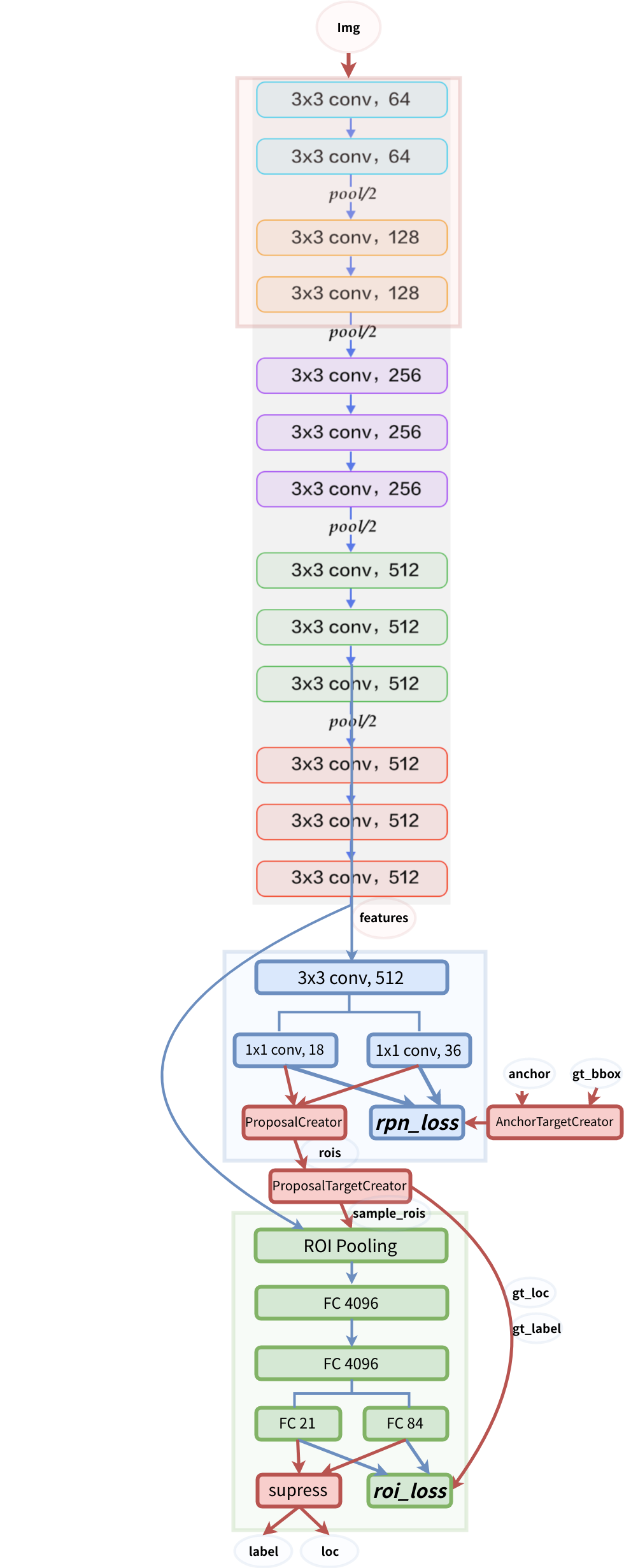
Structure du modèle