simple faster rcnn pytorch
1.0.0
[UPDATE:] Ich habe den Code weiter zu Pytorch 1.5, Torchvision 0.6 und den angepassten Ops -Roipool und NMS durch das aus Torchvision vereinfacht. Wenn Sie den alten Versionscode wünschen, können Sie die Filiale v1.0 auschecken
Dieses Projekt ist eine vereinfachte , schnellere R-CNN-Implementierung auf der Grundlage von ChainerCV und anderen Projekten. Ich hoffe, es kann als Startcode für diejenigen dienen, die das Detail eines schnelleren R-CNN kennenlernen möchten. Es zielt darauf ab,:
Und es hat die folgenden Funktionen:
VGG16 Zug bei trainval und Test auf test geteilt.
Hinweis : Das Training zeigt große Zufälligkeit. Möglicherweise benötigen Sie ein bisschen Glück und mehr Epochen des Trainings, um die höchste Karte zu erreichen. Es sollte jedoch leicht sein, die untere Grenze zu übertreffen.
| Durchführung | Karte |
|---|---|
| Herkunftspapier | 0,699 |
| Zug mit Caffees vorgeläutetem Modell | 0,700-0.712 |
| Zug mit Torchvision vor dem vorbereiteten Modell | 0,685-0,701 |
| Modell, das aus ChainerCV umgewandelt wurde (gemeldet 0,706) | 0,7053 |
| Durchführung | GPU | Schlussfolgerung | Training |
|---|---|---|---|
| Herkunftspapier | K40 | 5 fps | N / A |
| Dies [1] | Titan XP | 14-15 fps | 6 fps |
| Pytorch-Faste-Rcnn | Titan XP | 15-17fps | 6fps |
[1]: Stellen Sie sicher, dass Sie Cupy richtig installieren und nur ein Programm in der GPU ausgeführt werden. Die Trainingsgeschwindigkeit ist empfindlich für Ihren GPU -Status. Weitere Informationen finden Sie unter Fehlerbehebung. Darüber hinaus ist es zu Beginn des Programms langsam - es braucht Zeit, um sich aufzuwärmen.
Es könnte schneller sein, indem Visualisierung, Protokollierung, Mittelwertverlust usw. entfernt werden.
Hier ist ein Beispiel für Create Environ von Grund auf neu mit anaconda
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
Wenn Sie Anaconda nicht verwenden, dann:
Installieren Sie PyTorch mit GPU (Code sind nur GPU), siehe offizielle Website
Installieren Sie andere Abhängigkeiten: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
Starten Sie die Visualisierung zur Visualisierung
nohup python -m visdom.server & Laden Sie vorgeladen von Google Drive oder Baidu NetDisk (PassWD: SCXN) herunter.
Weitere Details finden Sie unter Demo.ipynb.
Laden Sie das Training, die Validierung, die Testdaten und das VocDevkit herunter
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar Extrahieren Sie alle diese Tars in ein Verzeichnis namens VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarEs sollte diese Grundstruktur haben
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... Ändern Sie voc_data_dir CFG-Element in utils/config.py oder übergeben Sie es mit Argument wie --voc-data-dir=/path/to/VOCdevkit/VOC2007/ .
Wenn Sie das Kaffe-Vorstufe als anfängliches Gewicht verwenden möchten, können Sie unten laufen, um VGG16-Gewichte aus der Kaffe umgewandelt zu lassen, was dem Ursprungspapier verwendet wird.
python misc/convert_caffe_pretrain.pyDiese Skripte würden ein vorgezogenes Modell herunterladen und es in das mit Torchvision kompatibele Format konvertieren. Wenn Sie in China sind und das Vorbereitungsmodell nicht herunterladen können, können Sie sich auf dieses Problem beziehen
Anschließend können Sie angeben, wo das Caffe-Pretraind-Modell vgg16_caffe.pth in utils/config.py gespeichert wird, indem Sie caffe_pretrain_path einstellen. Der Standardpfad ist in Ordnung.
Wenn Sie aus Torchvision ein vorgezogenes Modell verwenden möchten, können Sie diesen Schritt überspringen.
Beachten Sie , dass das vorbereitete Modell von Caffe eine geringfügige bessere Leistung gezeigt hat.
HINWEIS : Das Caffe-Modell benötigt Bilder in BGR 0-255, während das Torchvision-Modell Bilder in RGB und 0-1 benötigt. Weitere Informationen finden Sie data/dataset.py .
python train.py train --env= ' fasterrcnn ' --plot-every=100 Weitere Argumente finden Sie unter utils/config.py .
Einige wichtige Argumente:
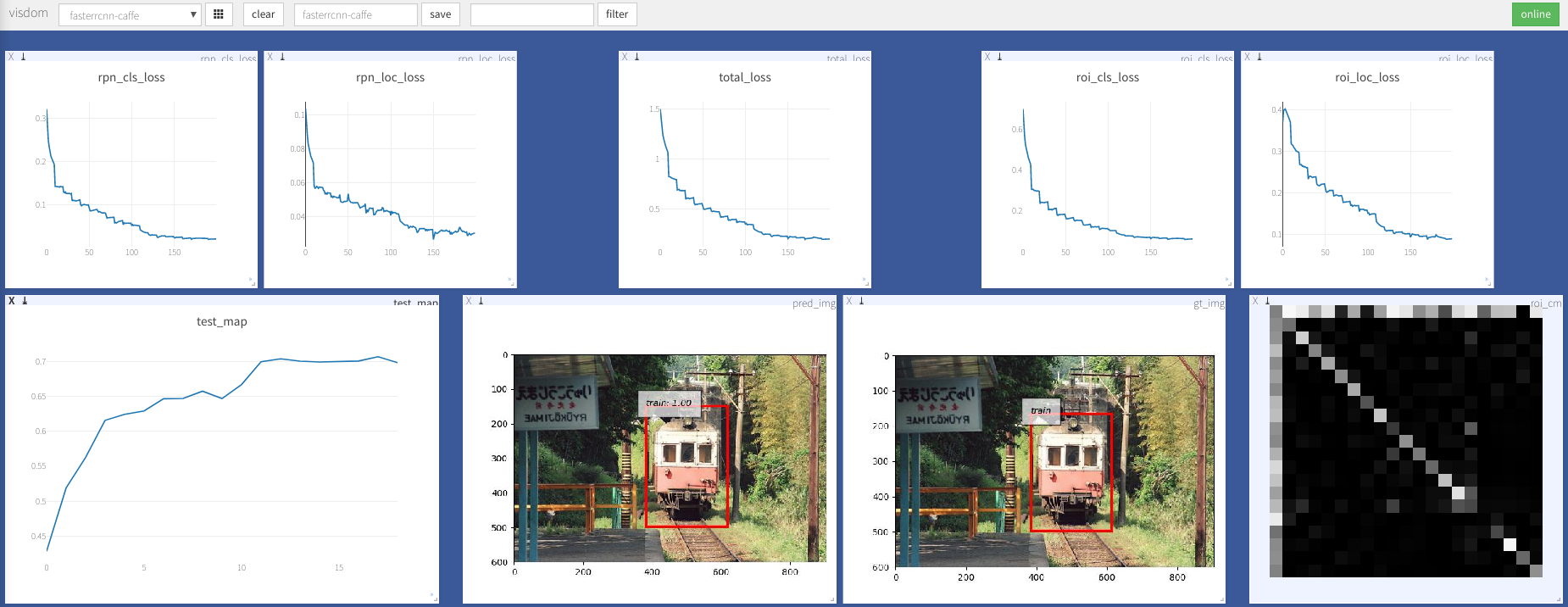
--caffe-pretrain=False : Verwenden Sie das Vorab-Modell aus Kaffe oder Torchvision (Standard: Torchvison)--plot-every=n : Visualisieren Sie Vorhersage, Verlust usw. Alle n Stapel.--env : Visdom Env für die Visualisierung--voc_data_dir : Wo die VOC-Daten gespeichert sind--use-drop : Verwenden Sie Dropout im ROI-Kopf, Standard Falsches--use-Adam : Verwenden Sie Adam anstelle von SGD, Standard SGD. (Sie müssen ein sehr niedriges lr für Adam festlegen)--load-path : Vorbereitete Modellpfad, Standard- None , wenn er angegeben wird, würde er geladen. Sie können Browser öffnen, http://<ip>:8097 besuchen und die Visualisierung des Trainingsverfahrens wie unten sehen:
Dataloader: received 0 items of ancdata
Siehe Diskussion, es ist allgemein in Train.py repariert. Ich denke, Sie sind frei von diesem Problem.
Windows -Unterstützung
Ich habe keine Windows -Maschine mit GPU, um es zu debuggen und zu testen. Es ist willkommen, wenn jemand eine Pull -Anfrage stellen und sie testen könnte.
Diese Arbeit baut auf vielen hervorragenden Werken auf, darunter:
Unter MIT lizenziert, siehe Lizenz für weitere Details.
Beitrag Willkommen.
Wenn Sie auf ein Problem stoßen, können Sie ein Problem öffnen, aber in letzter Zeit zu beschäftigt.
Korrigieren Sie mich, wenn etwas falsch oder unklar ist.
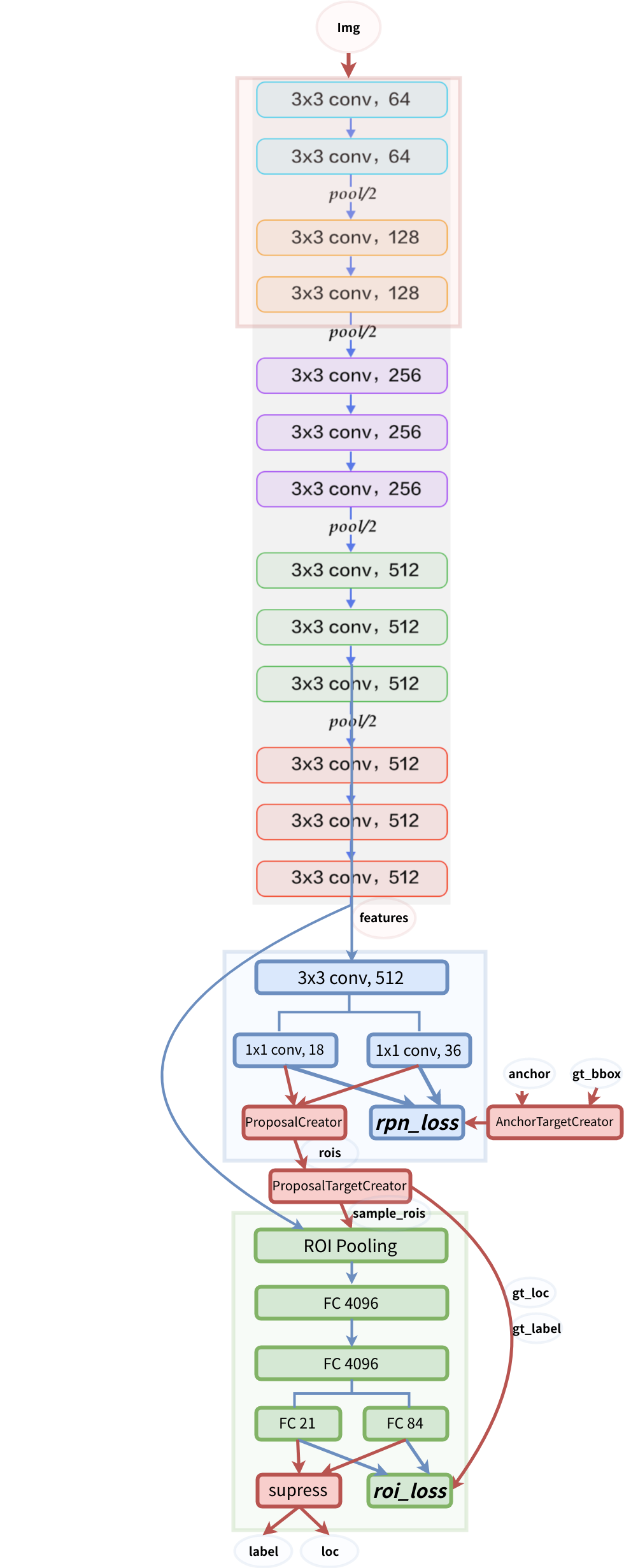
Modellstruktur