simple faster rcnn pytorch
1.0.0
[UPDATE:] Saya lebih jauh menyederhanakan kode ke Pytorch 1.5, TorchVision 0.6, dan mengganti OPS Roipool dan NMS yang disesuaikan dengan yang dari TorchVision. Jika Anda menginginkan kode versi lama, silakan checkout cabang v1.0
Proyek ini adalah implementasi R-CNN yang lebih cepat disederhanakan berdasarkan rantai dan proyek lainnya. Saya berharap ini dapat berfungsi sebagai kode awal bagi mereka yang ingin mengetahui detail R-CNN lebih cepat. Itu bertujuan untuk:
Dan memiliki fitur berikut:
VGG16 berlatih di trainval dan tes pada test split.
Catatan : Pelatihan menunjukkan keacakan yang hebat, Anda mungkin perlu sedikit keberuntungan dan lebih banyak zaman pelatihan untuk mencapai peta tertinggi. Namun, harus mudah untuk melampaui batas bawah.
| Pelaksanaan | peta |
|---|---|
| kertas asal | 0.699 |
| berlatih dengan model pretrained caffe | 0.700-0.712 |
| Latih dengan model pretrained torchvision | 0.685-0.701 |
| Model dikonversi dari rantai (dilaporkan 0,706) | 0.7053 |
| Pelaksanaan | GPU | Kesimpulan | Pelatihan |
|---|---|---|---|
| kertas asal | K40 | 5 fps | Na |
| Ini [1] | Titan XP | 14-15 fps | 6 fps |
| Pytorch-Faster-RCNN | Titan XP | 15-17fps | 6fps |
[1]: Pastikan Anda menginstal Cupy dengan benar dan hanya satu program yang dijalankan di GPU. Kecepatan pelatihan peka terhadap status GPU Anda. Lihat Pemecahan Masalah untuk info lebih lanjut. Lebih lambat di awal program - perlu waktu untuk melakukan pemanasan.
Ini bisa lebih cepat dengan menghapus visualisasi, penebangan, kerugian rata -rata dll.
Berikut adalah contoh Create Environ From Scratch dengan anaconda
# create conda env
conda create --name simp python=3.7
conda activate simp
# install pytorch
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# install other dependancy
pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
# start visdom
nohup python -m visdom.server &
Jika Anda tidak menggunakan Anaconda, maka:
Instal Pytorch dengan GPU (kode hanya GPU), lihat situs web resmi
Instal Ketergantungan Lainnya: pip install visdom scikit-image tqdm fire ipdb pprint matplotlib torchnet
Mulailah Visdom untuk Visualisasi
nohup python -m visdom.server & Unduh model pretrained dari Google Drive atau Baidu Netdisk (Passwd: SCXN)
Lihat demo.ipynb untuk lebih detail.
Unduh pelatihan, validasi, data uji dan vocdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar Ekstrak semua tar ini ke dalam satu direktori bernama VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tarItu harus memiliki struktur dasar ini
$VOCdevkit / # development kit
$VOCdevkit /VOCcode/ # VOC utility code
$VOCdevkit /VOC2007 # image sets, annotations, etc.
# ... and several other directories ... Modifikasi item CFG voc_data_dir di utils/config.py , atau lewati untuk program menggunakan argumen seperti --voc-data-dir=/path/to/VOCdevkit/VOC2007/ .
Jika Anda ingin menggunakan model caffe-pretrain sebagai bobot awal, Anda dapat menjalankan di bawah ini untuk mendapatkan bobot VGG16 yang dikonversi dari caffe, yang sama dengan penggunaan kertas asal.
python misc/convert_caffe_pretrain.pyScript ini akan mengunduh model pretrained dan mengonversinya ke format yang kompatibel dengan TorchVision. Jika Anda berada di China dan tidak dapat mengunduh model pretrain, Anda dapat merujuk pada masalah ini
Kemudian Anda dapat menentukan di mana model Caffe-Pretraind vgg16_caffe.pth disimpan di utils/config.py dengan mengatur caffe_pretrain_path . Jalur defaultnya ok.
Jika Anda ingin menggunakan model pretrained dari TorchVision, Anda dapat melewatkan langkah ini.
Catatan , model pretrained caffe telah menunjukkan sedikit kinerja yang lebih baik.
Catatan : Model Caffe memerlukan gambar dalam BGR 0-255, sedangkan model TorchVision memerlukan gambar dalam RGB dan 0-1. Lihat data/dataset.py untuk lebih detail.
python train.py train --env= ' fasterrcnn ' --plot-every=100 Anda dapat merujuk ke utils/config.py untuk argumen lebih lanjut.
Beberapa argumen utama:
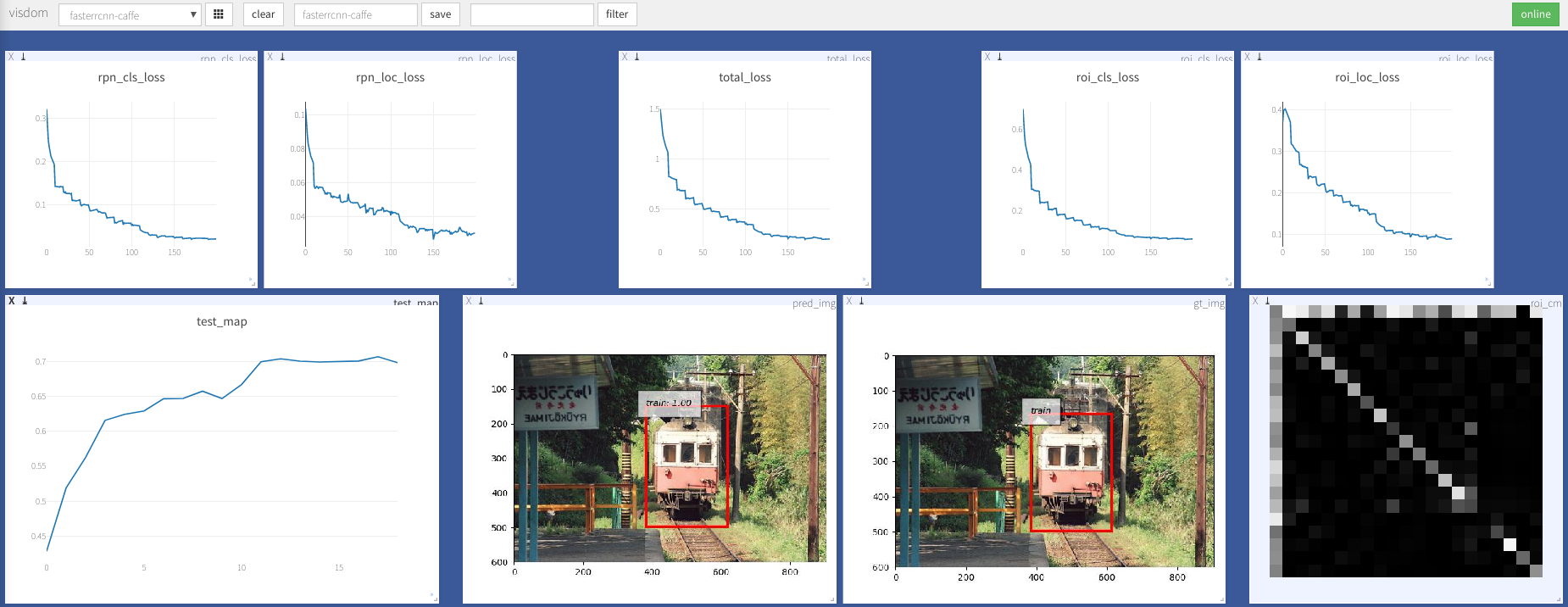
--caffe-pretrain=False : Gunakan model pretrain dari caffe atau torchvision (default: torchvison)--plot-every=n : Visualisasikan prediksi, kehilangan dll setiap n batch.--env : visdom env untuk visualisasi--voc_data_dir : di mana data VOC disimpan--use-drop : Gunakan dropout di kepala ROI, default false--use-Adam : Gunakan Adam bukan SGD, SGD default. (Anda perlu mengatur lr yang sangat rendah untuk Adam)--load-path : jalur model pretrained, None default, jika ditentukan, itu akan dimuat. Anda dapat membuka browser, kunjungi http://<ip>:8097 dan lihat visualisasi prosedur pelatihan seperti di bawah ini:
Dataloader: received 0 items of ancdata
Lihat diskusi, itu benar -benar diperbaiki di train.py. Jadi saya pikir Anda bebas dari masalah ini.
Dukungan Windows
Saya tidak memiliki mesin windows dengan GPU untuk men -debug dan mengujinya. Disambut jika ada yang bisa membuat permintaan tarik dan mengujinya.
Pekerjaan ini dibangun di atas banyak karya luar biasa, yang meliputi:
Lisensi di bawah MIT, lihat lisensi untuk lebih detail.
Kontribusi Selamat Datang.
Jika Anda mengalami masalah, jangan ragu untuk membuka masalah, tetapi akhir -akhir ini terlalu sibuk.
Koreksi saya jika ada yang salah atau tidak jelas.
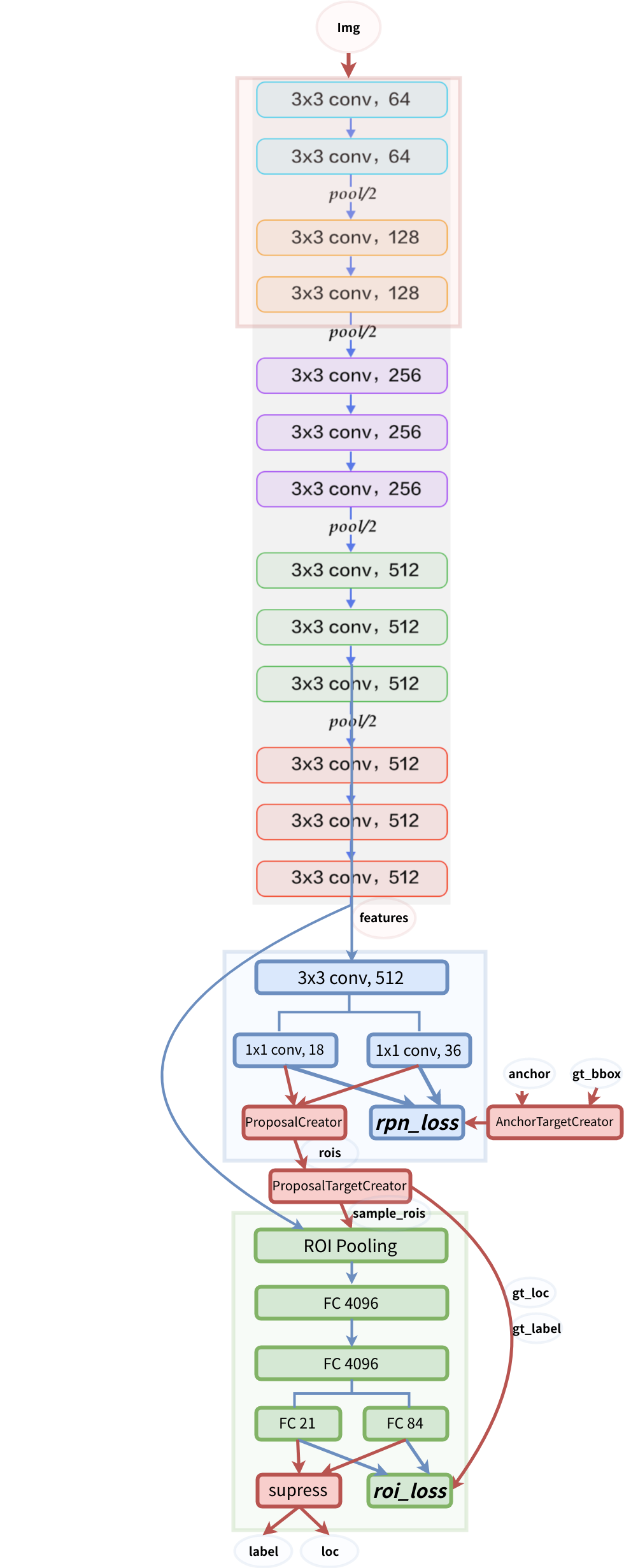
struktur model