GPT2 NewsTitle
1.0.0
帶有超詳細註釋的GPT2新聞標題生成項目
運行代碼
streamlit run app.py
or
streamlit run app.py --server.port your_port
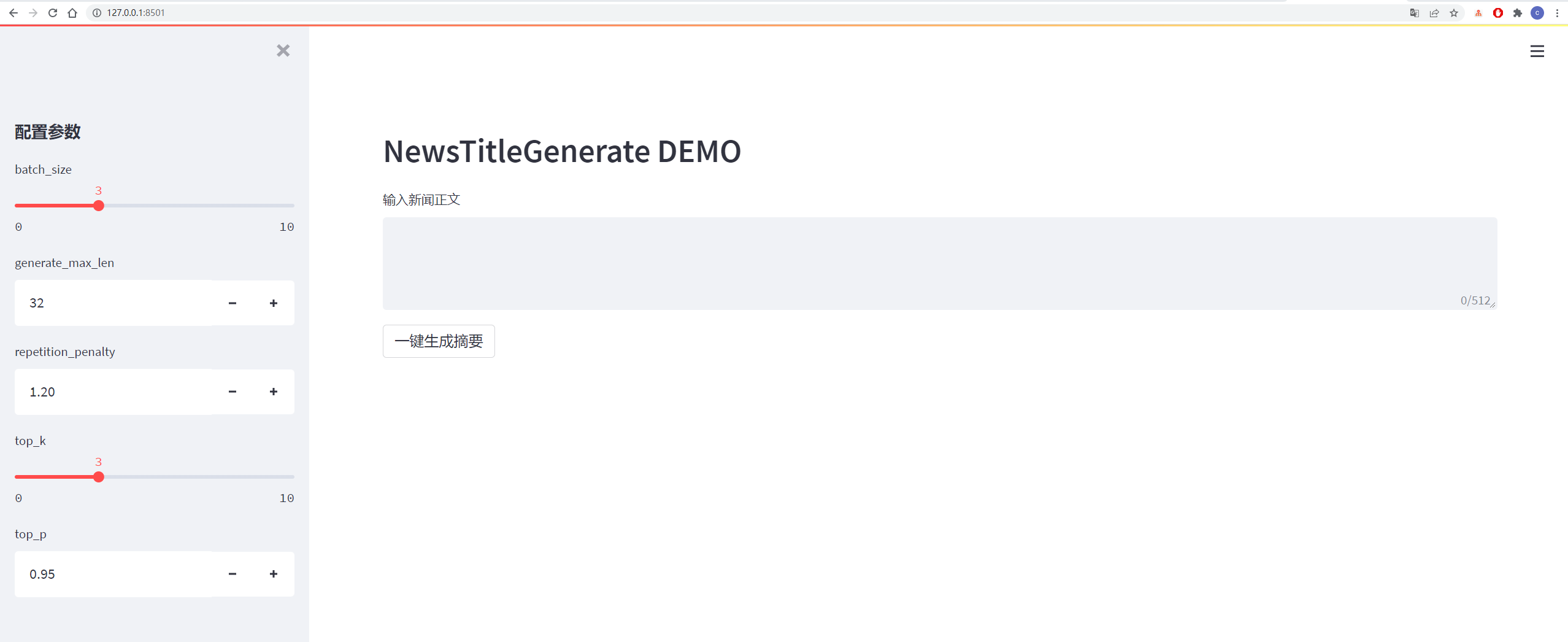
具體如下圖所示:
| 數據 | 原始數據/項目地址 | 處理後文件下載地址 |
|---|---|---|
| 清華新聞數據 | 地址 | 百度雲盤提取碼: vhol |
| 搜狗新聞數據 | 地址 | 百度雲盤提取碼:ode6 |
| nlpcc2017摘要數據 | 地址 | 百度雲盤提取碼:e0zq |
| csl摘要數據 | 地址 | 百度雲盤提取碼:0qot |
| 教育培訓行業摘要數據 | 地址 | 百度雲盤提取碼:kjz3 |
| lcsts摘要數據 | 地址 | 百度雲盤提取碼:bzov |
| 神策杯2018摘要數據 | 地址 | 百度雲盤提取碼:6f4f |
| 萬方摘要數據 | 地址 | 百度雲盤提取碼: p69g |
| 微信公眾號摘要數據 | 地址 | 百度雲盤提取碼: 5has |
| 微博數據 | 地址 | 百度雲盤提取碼: 85t5 |
| news2016zh新聞數據 | 地址 | 百度雲盤提取碼: qsj1 |
數據集集合:百度雲盤提取碼: 7am8
詳細見requirements.txt文件
數據來源於新浪微博,數據鏈接:https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcqq_aiomsg
| 數據描述 | 下載地址 |
|---|---|
| 原始數據 | 百度網盤,提取碼: nqzi |
| 處理後數據 | 百度網盤,提取碼: duba |
原始數據為直接從網上下載的新聞數據,處理後數據為使用data_helper.py處理過的數據,可直接用於訓練。
詳細見config/config.json文件
| 參數 | 值 |
|---|---|
| initializer_range | 0.02 |
| layer_norm_epsilon | 1e-05 |
| n_ctx | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| n_positions | 512 |
| vocab_size | 13317 |
注意:模型輸入除了各個詞的向量表示外,還包括文字段落向量表示和位置向量表示。 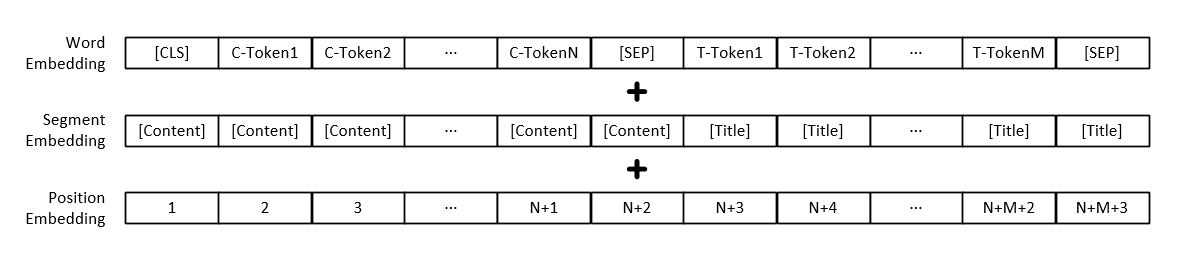
| 模型 | 下載地址 |
|---|---|
| GPT2模型 | 百度網盤,提取碼: 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
訓練參數可自行添加,包含參數具體如下:
| 參數 | 類型 | 預設值 | 描述 |
|---|---|---|---|
| device | str | "0" | 設置訓練或測試時使用的顯卡 |
| config_path | str | "config/config.json" | 模型參數配置信息 |
| vocab_path | str | "vocab/vocab.txt" | 詞表,該詞表為小詞表,並增加了一些新的標記 |
| train_file_path | str | "data_dir/train_data.json" | 新聞標題生成的訓練數據 |
| test_file_path | str | "data_dir/test_data.json" | 新聞標題生成的測試數據 |
| pretrained_model_path | str | None | 預訓練的GPT2模型的路徑 |
| data_dir | str | "data_dir" | 生成緩存數據的存放路徑 |
| num_train_epochs | int | 5 | 模型訓練的輪數 |
| train_batch_size | int | 16 | 訓練時每個batch的大小 |
| test_batch_size | int | 8 | 測試時每個batch的大小 |
| learning_rate | float | 1e-4 | 模型訓練時的學習率 |
| warmup_proportion | float | 0.1 | warm up概率,即訓練總步長的百分之多少,進行warm up操作 |
| adam_epsilon | float | 1e-8 | Adam優化器的epsilon值 |
| logging_steps | int | 20 | 保存訓練日誌的步數 |
| eval_steps | int | 4000 | 訓練時,多少步進行一次測試 |
| gradient_accumulation_steps | int | 1 | 梯度積累 |
| max_grad_norm | float | 1.0 | |
| output_dir | str | "output_dir/" | 模型輸出路徑 |
| seed | int | 2020 | 隨機種子 |
| max_len | int | 512 | 輸入模型的最大長度,要比config中n_ctx小 |
或者修改train.py文件中的set_args函數內容,可修改默認值。
本項目提供的模型,共訓練了5個epoch,模型訓練損失和測試集損失分別如下: 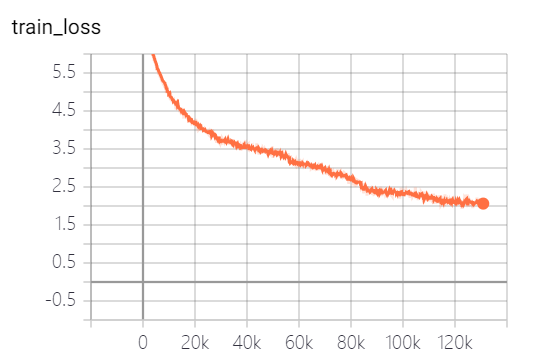
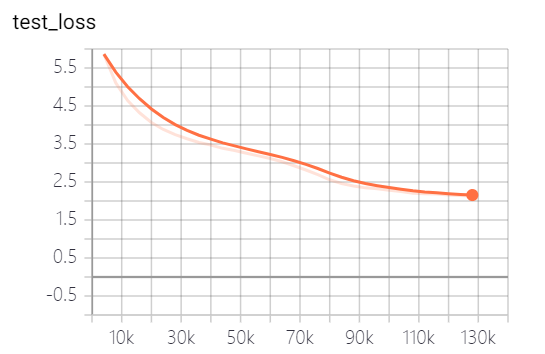
模型其實還沒有訓練完全,按照loss走勢,還可以繼續訓練。
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
參數可自行添加,包含參數具體如下:
| 參數 | 類型 | 預設值 | 描述 |
|---|---|---|---|
| device | str | "0" | 設置訓練或測試時使用的顯卡 |
| model_path | str | "output_dir/checkpoint-139805" | 模型文件路徑 |
| vocab_path | str | "vocab/vocab.txt" | 詞表,該詞表為小詞表,並增加了一些新的標記 |
| batch_size | int | 3 | 生成標題的個數 |
| generate_max_len | int | 32 | 生成標題的最大長度 |
| repetition_penalty | float | 1.2 | 重複處罰率 |
| top_k | int | 5 | 解碼時保留概率最高的多少個標記 |
| top_p | float | 0.95 | 解碼時保留概率累加大於多少的標記 |
| max_len | int | 512 | 輸入模型的最大長度,要比config中n_ctx小 |
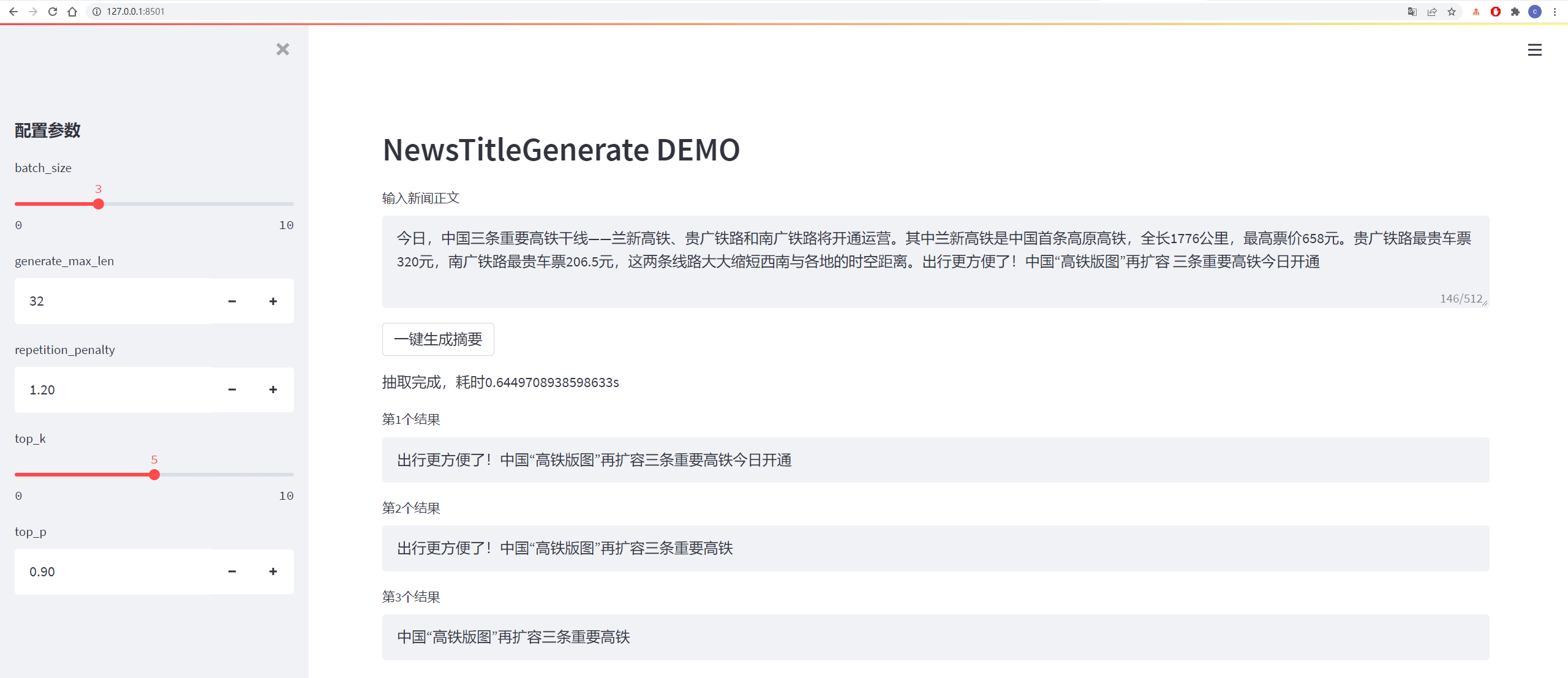
測試結果如下:
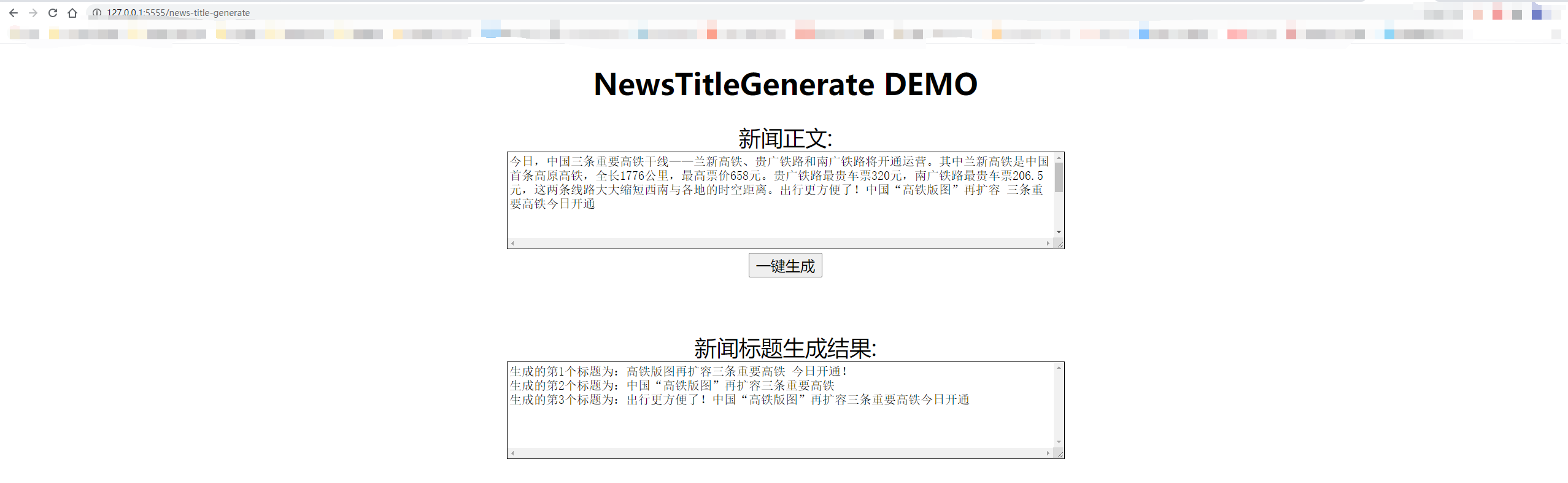
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
解碼採用top_k和top_p解碼策略,有一定的隨機性,可重複生成。
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
本地測試直接使用"127.0.0.1:5555/news-title-generate",如果給他人訪問,只需將"127.0.0.1"替換成的電腦的IP地址即可。
具體如下圖所示:
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
e-mail:[email protected]
知乎:劉聰NLP
公眾號:NLP工作站



