GPT2 NewsTitle
1.0.0
โครงการสร้างชื่อเรื่องข่าว GPT2 ด้วยคำอธิบายประกอบรายละเอียดสุดยอด
เรียกใช้รหัส
streamlit run app.py
or
streamlit run app.py --server.port your_port
รายละเอียดจะแสดงในรูปด้านล่าง:
| ข้อมูล | ข้อมูลต้นฉบับ/ที่อยู่โครงการ | ที่อยู่ดาวน์โหลดไฟล์หลังจากการประมวลผล |
|---|---|---|
| ข้อมูลข่าว Tsinghua | ที่อยู่ | Baidu Cloud Disk Extraction Code: Vhol |
| ข้อมูลข่าวของ Sogou | ที่อยู่ | Baidu Cloud Disk Extraction Code: ODE6 |
| ข้อมูลสรุป NLPCC2017 | ที่อยู่ | Baidu Cloud Disk Extraction Code: E0ZQ |
| ข้อมูลสรุป CSL | ที่อยู่ | Baidu Cloud Disk Extraction Code: 0qot |
| ข้อมูลสรุปอุตสาหกรรมการศึกษาและการฝึกอบรม | ที่อยู่ | Baidu Cloud Disk Extraction Code: KJZ3 |
| ข้อมูลสรุป LCSS | ที่อยู่ | Baidu Cloud Disk Extraction Code: BZOV |
| ข้อมูลสรุป Shence Cup 2018 | ที่อยู่ | Baidu Cloud Disk Extraction Code: 6F4F |
| ข้อมูลสรุป Wanfang | ที่อยู่ | Baidu Cloud Disk Extraction Code: P69G |
| ข้อมูลสรุปบัญชีอย่างเป็นทางการของ WeChat | ที่อยู่ | Baidu Cloud Disk Extraction Code: 5has |
| ข้อมูล Weibo | ที่อยู่ | Baidu Cloud Disk Extraction Code: 85T5 |
| news2016ZH ข้อมูลข่าว | ที่อยู่ | Baidu Cloud Disk Extraction Code: QSJ1 |
ชุดข้อมูล: Baidu Cloud Disk Extraction Code: 7AM8
ดูไฟล์ข้อกำหนดสำหรับรายละเอียด
ข้อมูลมาจาก Sina Weibo ลิงค์ข้อมูล: https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcq_aiomsg
| คำอธิบายข้อมูล | ดาวน์โหลดที่อยู่ |
|---|---|
| ข้อมูลดิบ | Baidu Netdisk, สกัดรหัส: nqzi |
| ข้อมูลที่ประมวลผล | Baidu Netdisk, Extract Code: Duba |
ข้อมูลต้นฉบับคือข้อมูลข่าวที่ดาวน์โหลดโดยตรงจากอินเทอร์เน็ต หลังจากการประมวลผลข้อมูลจะถูกประมวลผลข้อมูลโดยใช้ data_helper.py และสามารถใช้สำหรับการฝึกอบรมโดยตรง
ดูไฟล์ config/config.json สำหรับรายละเอียด
| พารามิเตอร์ | ค่า |
|---|---|
| initializer_range | 0.02 |
| layer_norm_epsilon | 1E-05 |
| n_ctx | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| n_positions | 512 |
| คำศัพท์ | 13317 |
หมายเหตุ: นอกเหนือจากการเป็นตัวแทนเวกเตอร์ของแต่ละคำแล้วอินพุตแบบจำลองยังรวมถึงการแสดงเวกเตอร์ย่อหน้าข้อความและการเป็นตัวแทนของเวกเตอร์ตำแหน่ง 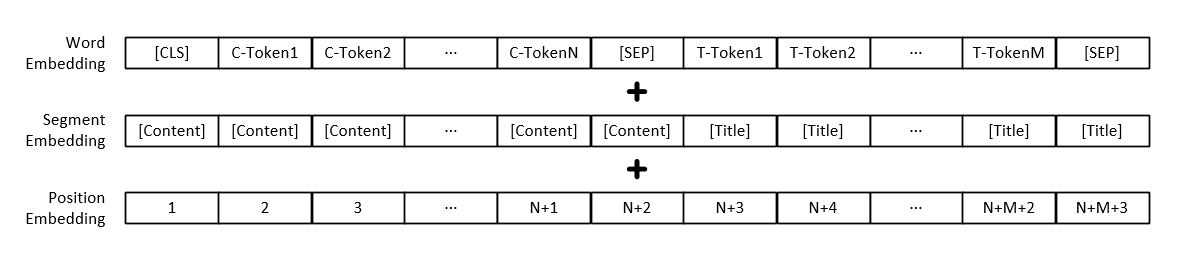
| แบบอย่าง | ดาวน์โหลดที่อยู่ |
|---|---|
| รุ่น GPT2 | Baidu Netdisk, รหัสการสกัด: 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
สามารถเพิ่มพารามิเตอร์การฝึกอบรมได้ด้วยตัวเองรวมถึงพารามิเตอร์ดังนี้:
| พารามิเตอร์ | พิมพ์ | ค่าเริ่มต้น | อธิบาย |
|---|---|---|---|
| อุปกรณ์ | str | "0" | ตั้งค่าการ์ดกราฟิกที่ใช้สำหรับการฝึกอบรมหรือการทดสอบ |
| config_path | str | "config/config.json" | ข้อมูลการกำหนดค่าพารามิเตอร์แบบจำลอง |
| คำศัพท์ | str | "Vocab/Vocab.txt" | รายการคำเป็นรายการคำเล็ก ๆ และได้เพิ่มเครื่องหมายใหม่บางส่วน |
| train_file_path | str | "data_dir/train_data.json" | ข้อมูลการฝึกอบรมที่สร้างโดยชื่อข่าว |
| test_file_path | str | "data_dir/test_data.json" | ข้อมูลทดสอบที่สร้างโดยชื่อข่าว |
| pretrained_model_path | str | ไม่มี | เส้นทางสู่รุ่น GPT2 ที่ผ่านการฝึกอบรมมาก่อน |
| data_dir | str | "data_dir" | สร้างเส้นทางการจัดเก็บข้อมูลที่แคช |
| num_train_epochs | int | 5 | จำนวนรอบสำหรับการฝึกอบรมแบบจำลอง |
| train_batch_size | int | 16 | ขนาดของแต่ละชุดในระหว่างการฝึกอบรม |
| test_batch_size | int | 8 | ขนาดของแต่ละชุดในระหว่างการทดสอบ |
| การเรียนรู้ _Rate | ลอย | 1E-4 | อัตราการเรียนรู้ระหว่างการฝึกอบรมแบบจำลอง |
| warmup_proportion | ลอย | 0.1 | ความน่าจะเป็นที่อุ่นเครื่องคือเปอร์เซ็นต์ของขนาดขั้นตอนการฝึกอบรมทั้งหมดดำเนินการอุ่นเครื่อง |
| Adam_epsilon | ลอย | 1e-8 | ค่า Epsilon ของ Adam Optimizer |
| logging_steps | int | 20 | จำนวนขั้นตอนในการบันทึกบันทึกการฝึกอบรม |
| eval_steps | int | 4000 | จะทำกี่ขั้นตอนในระหว่างการฝึกอบรม? |
| การไล่ระดับ | int | 1 | การสะสมการไล่ระดับสี |
| max_grad_norm | ลอย | 1.0 | |
| output_dir | str | "output_dir/" | เส้นทางเอาต์พุตแบบจำลอง |
| เมล็ด | int | 2020 | เมล็ดสุ่ม |
| max_len | int | 512 | ความยาวสูงสุดของโมเดลอินพุตนั้นเล็กกว่า N_CTX ในการกำหนดค่า |
หรือแก้ไขเนื้อหาของฟังก์ชัน set_args ในไฟล์ train.py เพื่อแก้ไขค่าเริ่มต้น
แบบจำลองที่จัดทำโดยโครงการนี้ได้ฝึกอบรม 5 EPOCHS และการสูญเสียการฝึกอบรมแบบจำลองและการสูญเสียชุดทดสอบมีดังนี้: 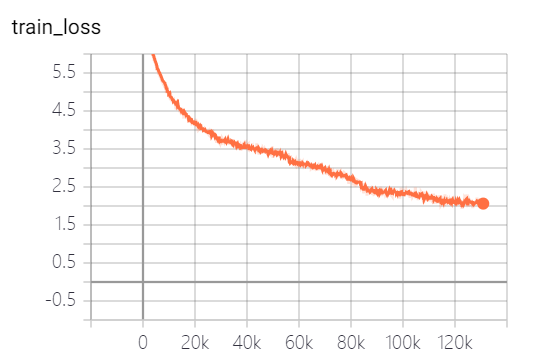
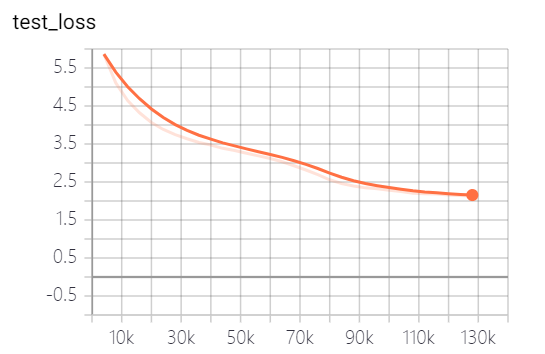
แบบจำลองยังไม่ได้รับการฝึกฝนอย่างเต็มที่ ตามแนวโน้มการสูญเสียคุณสามารถฝึกอบรมต่อไป
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
พารามิเตอร์สามารถเพิ่มด้วยตัวเองรวมถึงพารามิเตอร์ดังนี้:
| พารามิเตอร์ | พิมพ์ | ค่าเริ่มต้น | อธิบาย |
|---|---|---|---|
| อุปกรณ์ | str | "0" | ตั้งค่าการ์ดกราฟิกที่ใช้สำหรับการฝึกอบรมหรือการทดสอบ |
| model_path | str | "output_dir/checkpoint-139805" | เส้นทางไฟล์รุ่น |
| คำศัพท์ | str | "Vocab/Vocab.txt" | รายการคำเป็นรายการคำเล็ก ๆ และได้เพิ่มเครื่องหมายใหม่บางส่วน |
| batch_size | int | 3 | จำนวนชื่อที่สร้างขึ้น |
| generate_max_len | int | 32 | ความยาวสูงสุดของชื่อที่สร้างขึ้น |
| repetition_penalty | ลอย | 1.2 | อัตราการลงโทษซ้ำ ๆ |
| top_k | int | 5 | จำนวนแท็กที่มีความน่าจะเป็นสูงสุดในการรักษาระหว่างการถอดรหัส |
| top_p | ลอย | 0.95 | เครื่องหมายที่มีความน่าจะเป็นในการเก็บรักษาสูงกว่าความน่าจะเป็นของการเก็บรักษาสะสมในระหว่างการถอดรหัส |
| max_len | int | 512 | ความยาวสูงสุดของโมเดลอินพุตนั้นเล็กกว่า N_CTX ในการกำหนดค่า |
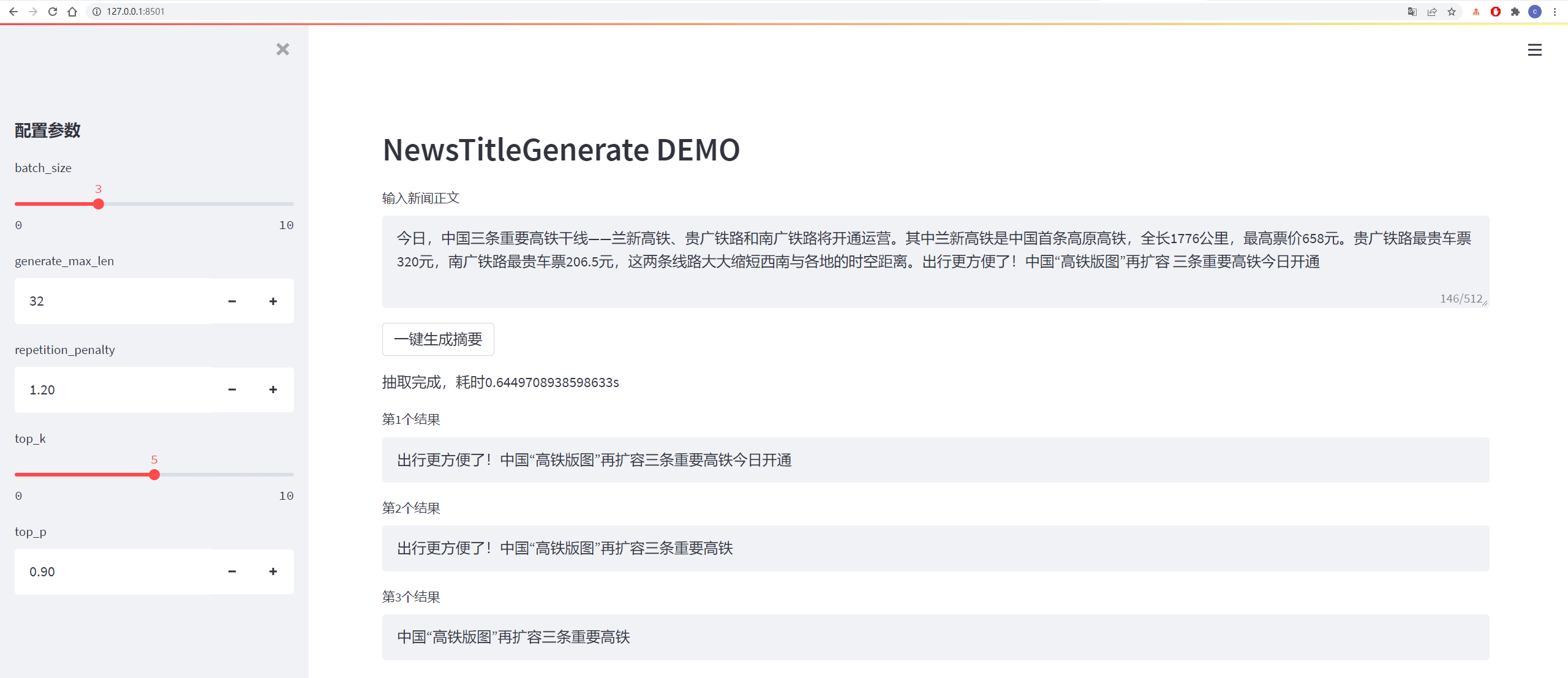
ผลการทดสอบมีดังนี้:
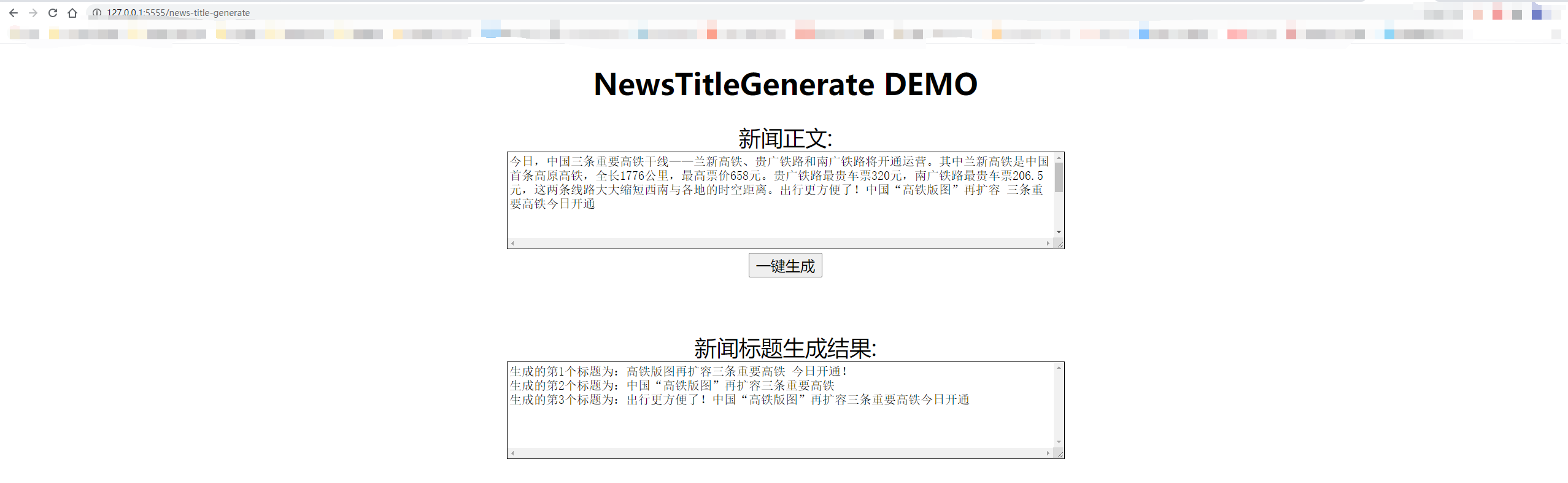
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
การถอดรหัสใช้กลยุทธ์การถอดรหัส TOP_K และ TOP_P ซึ่งมีการสุ่มบางอย่างและสามารถสร้างได้ซ้ำ ๆ
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
การทดสอบในท้องถิ่นใช้ "127.0.0.1:5555/News-title-generate" หากคุณให้ผู้อื่นเข้าถึงได้คุณจะต้องแทนที่ "127.0.0.1" ด้วยที่อยู่ IP ของคอมพิวเตอร์
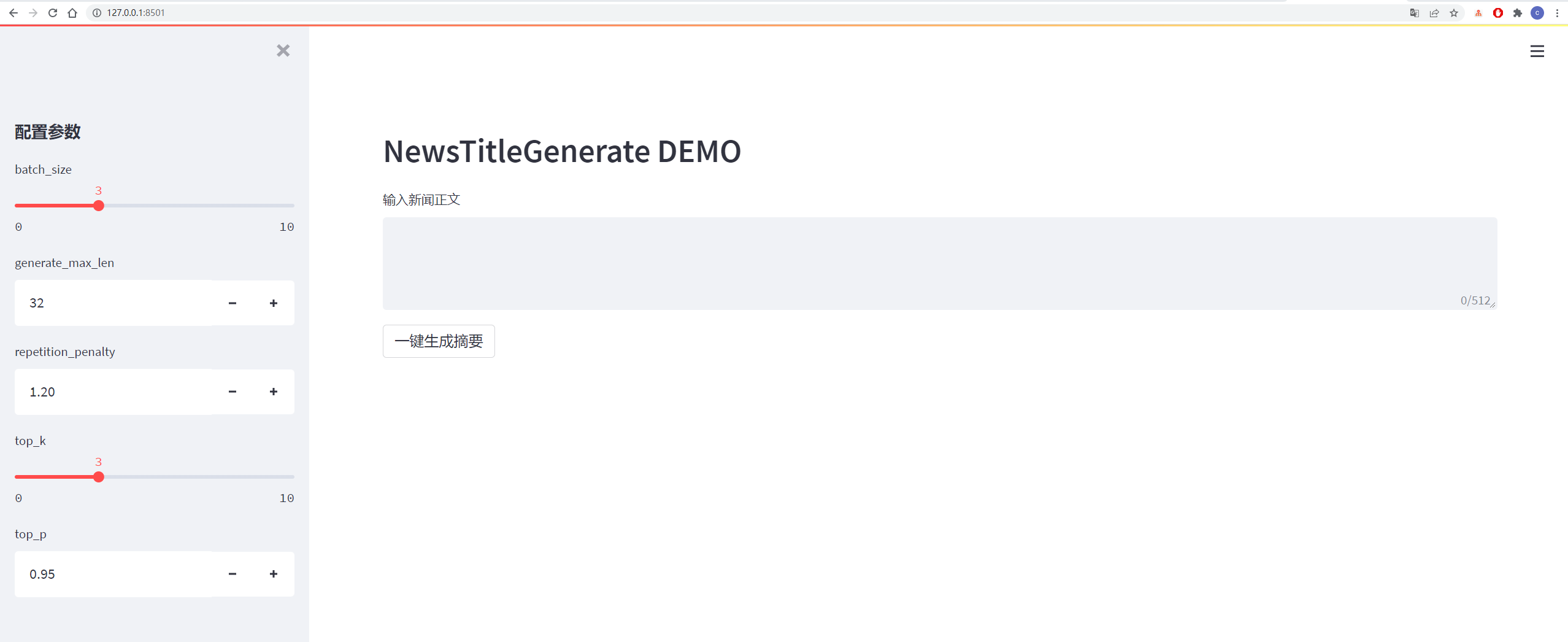
รายละเอียดจะแสดงในรูปด้านล่าง:
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
อีเมล: [email protected]
Zhihu: Liu Cong NLP
บัญชีอย่างเป็นทางการ: เวิร์กสเตชัน NLP



