GPT2 NewsTitle
1.0.0
GPT2ニュースタイトル生成プロジェクトは、非常に詳細な注釈を備えています
コードを実行します
streamlit run app.py
or
streamlit run app.py --server.port your_port
詳細については、以下の図に示します。
| データ | 元のデータ/プロジェクトアドレス | 処理後に住所をダウンロードします |
|---|---|---|
| Tsinghuaニュースデータ | 住所 | Baiduクラウドディスク抽出コード:Vhol |
| Sogouニュースデータ | 住所 | Baiduクラウドディスク抽出コード:ODE6 |
| NLPCC2017要約データ | 住所 | Baiduクラウドディスク抽出コード:E0ZQ |
| CSLサマリーデータ | 住所 | Baiduクラウドディスク抽出コード:0qot |
| 教育およびトレーニング業界の概要データ | 住所 | Baiduクラウドディスク抽出コード:KJZ3 |
| LCSSサマリーデータ | 住所 | Baiduクラウドディスク抽出コード:BZOV |
| Shence Cup 2018要約データ | 住所 | Baiduクラウドディスク抽出コード:6F4F |
| Wanfangサマリーデータ | 住所 | Baiduクラウドディスク抽出コード:P69G |
| WeChat公式アカウントの概要データ | 住所 | Baiduクラウドディスク抽出コード:5has |
| Weiboデータ | 住所 | Baiduクラウドディスク抽出コード:85T5 |
| News2016ZHニュースデータ | 住所 | Baiduクラウドディスク抽出コード:QSJ1 |
データセットコレクション:Baiduクラウドディスク抽出コード:7am8
詳細については、requincement.txtファイルを参照してください
データは、Sina Weiboからのものです。データリンク:https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcq_aiomsg
| データの説明 | アドレスをダウンロードしてください |
|---|---|
| 生データ | Baidu netdisk、抽出コード:nqzi |
| 処理されたデータ | Baidu Netdisk、抽出コード:Duba |
元のデータは、インターネットから直接ダウンロードされたニュースデータです。処理後、データはdata_helper.pyを使用して処理され、トレーニングに直接使用できます。
詳細については、config/config.jsonファイルを参照してください
| パラメーター | 価値 |
|---|---|
| initializer_range | 0.02 |
| layer_norm_epsilon | 1E-05 |
| N_CTX | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| n_positions | 512 |
| vocab_size | 13317 |
注:各単語のベクトル表現に加えて、モデル入力にはテキスト段落ベクトル表現と位置ベクトル表現も含まれます。 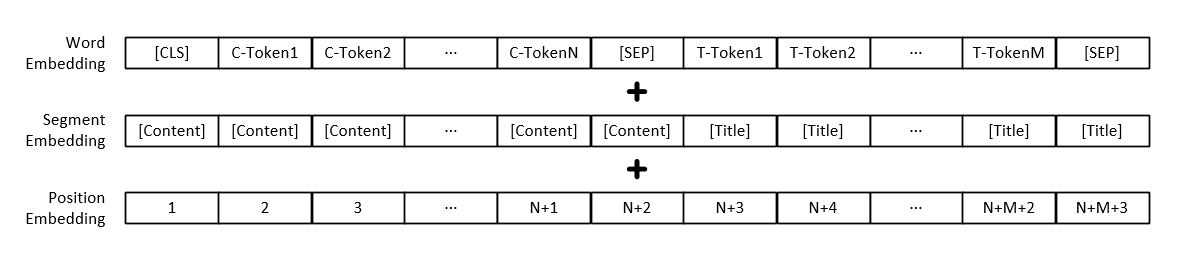
| モデル | アドレスをダウンロードしてください |
|---|---|
| GPT2モデル | Baidu Netdisk、抽出コード:165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
トレーニングパラメーターは、次のようなパラメーターを含め、自分で追加できます。
| パラメーター | タイプ | デフォルト値 | 説明する |
|---|---|---|---|
| デバイス | str | 「0」 | トレーニングやテストに使用されるグラフィックカードをセットアップする |
| config_path | str | 「config/config.json」 | モデルパラメーター構成情報 |
| vocab_path | str | 「vocab/vocab.txt」 | 単語リストは小さな単語リストであり、いくつかの新しいマークを追加しました |
| train_file_path | str | 「data_dir/train_data.json」 | ニュースタイトルによって生成されたトレーニングデータ |
| test_file_path | str | 「data_dir/test_data.json」 | ニュースタイトルによって生成されたテストデータ |
| retrained_model_path | str | なし | 事前に訓練されたGPT2モデルへのパス |
| data_dir | str | 「data_dir」 | キャッシュされたデータストレージパスを生成します |
| num_train_epochs | int | 5 | モデルトレーニングのラウンド数 |
| train_batch_size | int | 16 | トレーニング中の各バッチのサイズ |
| test_batch_size | int | 8 | テスト中の各バッチのサイズ |
| Learning_rate | フロート | 1E-4 | モデルトレーニング中の学習率 |
| warmup_proporther | フロート | 0.1 | ウォームアップの確率、つまり、トレーニングの合計ステップサイズの割合は、ウォームアップ操作を実行します |
| Adam_epsilon | フロート | 1E-8 | Adam OptimizerのEpsilon価値 |
| logging_steps | int | 20 | トレーニングログを保存する手順数 |
| eval_steps | int | 4000 | トレーニング中にいくつのステップが実行されますか? |
| gradient_accumulation_steps | int | 1 | 勾配蓄積 |
| max_grad_norm | フロート | 1.0 | |
| output_dir | str | 「output_dir/」 | モデル出力パス |
| シード | int | 2020 | ランダムシード |
| max_len | int | 512 | 入力モデルの最大長は、configのn_ctxよりも小さい |
または、train.pyファイルのset_args関数のコンテンツを変更して、デフォルト値を変更します。
このプロジェクトが提供するモデルは5つのエポックをトレーニングしており、モデルトレーニングの損失とテストセットの損失は次のとおりです。 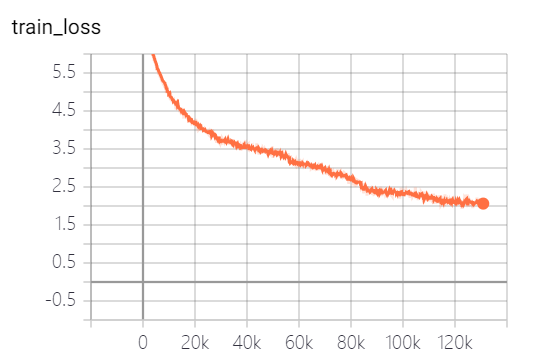
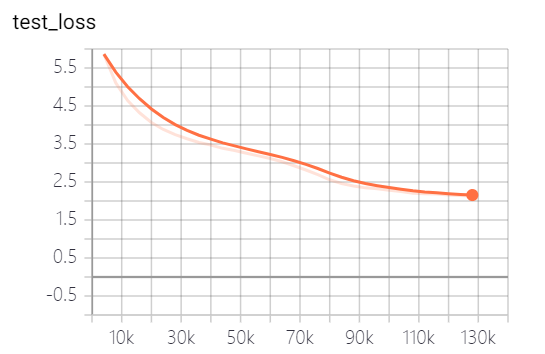
モデルはまだ完全に訓練されていません。損失の傾向によれば、あなたは引き続きトレーニングを続けることができます。
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
パラメーターを含むパラメーターは、次のようなパラメーターを含めて追加できます。
| パラメーター | タイプ | デフォルト値 | 説明する |
|---|---|---|---|
| デバイス | str | 「0」 | トレーニングやテストに使用されるグラフィックカードをセットアップする |
| model_path | str | 「output_dir/checkpoint-139805」 | モデルファイルパス |
| vocab_path | str | 「vocab/vocab.txt」 | 単語リストは小さな単語リストであり、いくつかの新しいマークを追加しました |
| batch_size | int | 3 | 生成されたタイトルの数 |
| Generate_max_len | int | 32 | 生成されたタイトルの最大長 |
| Repetition_Penalty | フロート | 1.2 | 繰り返しペナルティ率 |
| TOP_K | int | 5 | デコード中に保持される可能性が最も高いタグの数 |
| TOP_P | フロート | 0.95 | 保持確率がデコード中の累積保持確率よりも大きいマーカー |
| max_len | int | 512 | 入力モデルの最大長は、configのn_ctxよりも小さい |
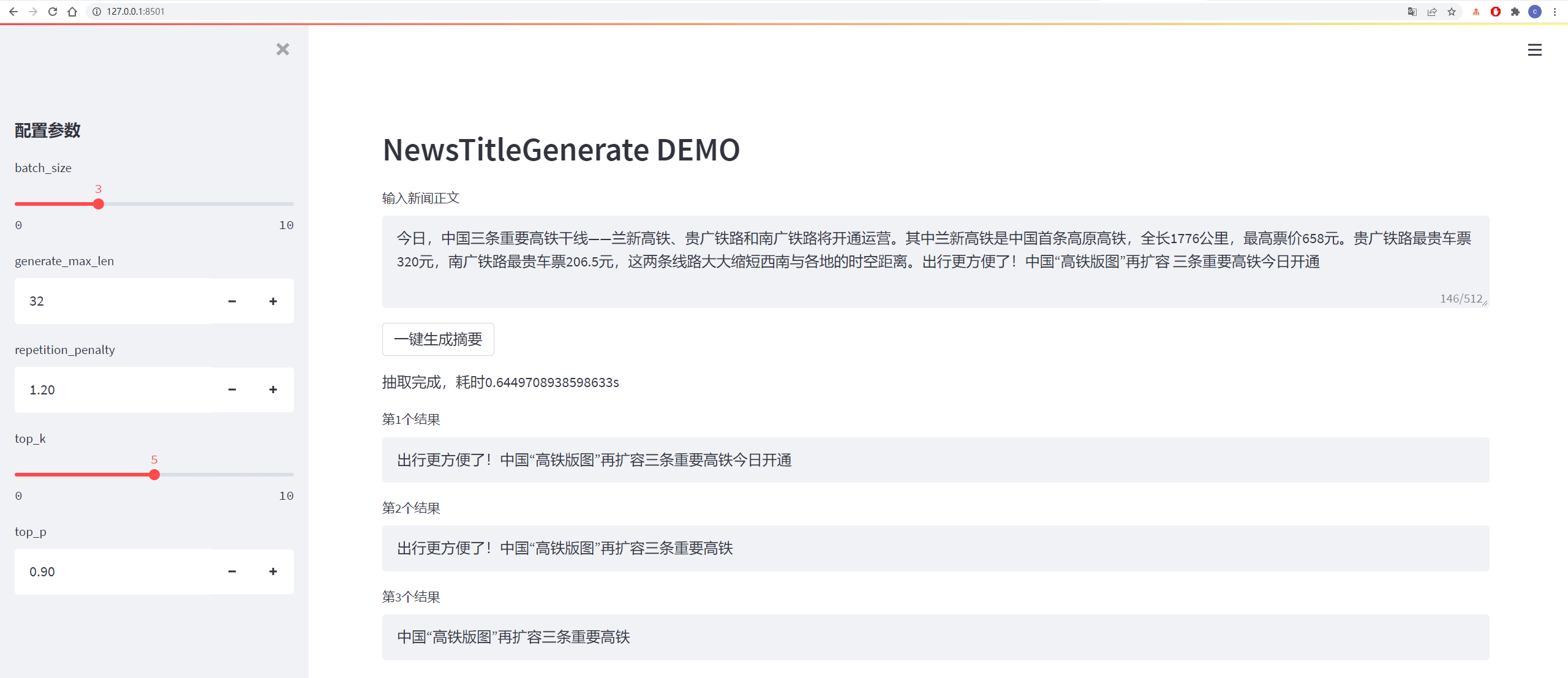
テスト結果は次のとおりです。
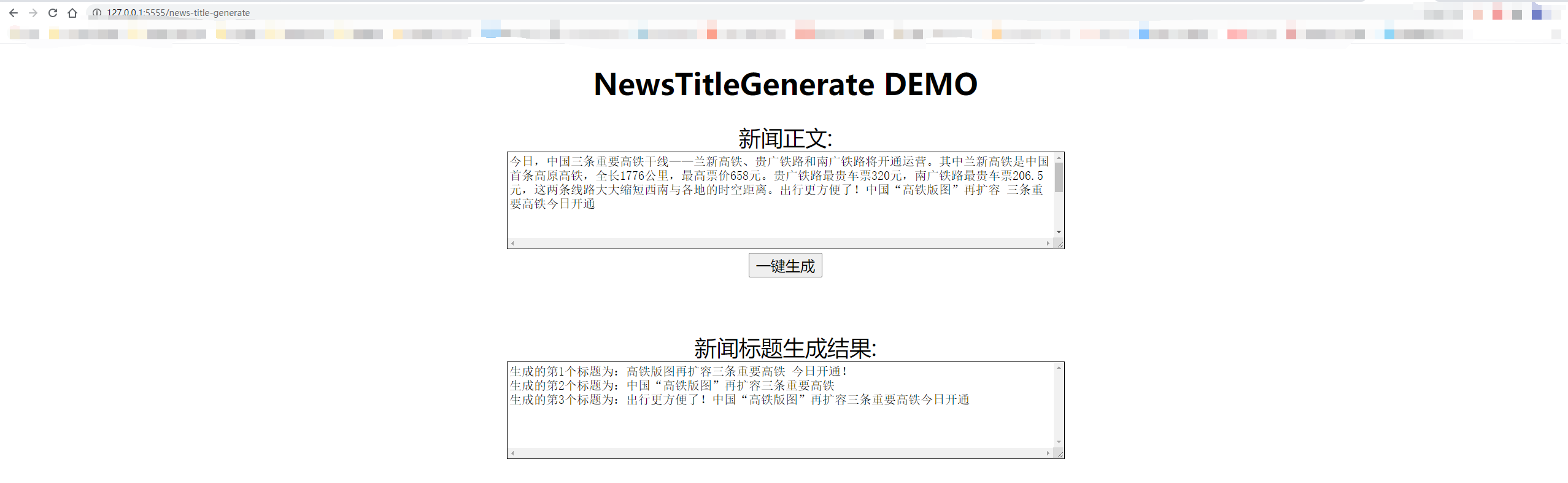
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
デコードは、特定のランダム性を持ち、繰り返し生成できるTOP_KおよびTOP_Pデコード戦略を採用しています。
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
ローカルテストでは「127.0.0.1:5555/News-Title-Generate」が使用されます。他の人にアクセスを提供する場合は、「127.0.0.1」をコンピューターのIPアドレスに置き換えるだけです。
詳細については、以下の図に示します。
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
電子メール:[email protected]
Zhihu:Liu Cong NLP
公式アカウント:NLPワークステーション



