GPT2 NewsTitle
1.0.0
GPT2 News Title Generation Project com anotações super detalhadas
Execute o código
streamlit run app.py
or
streamlit run app.py --server.port your_port
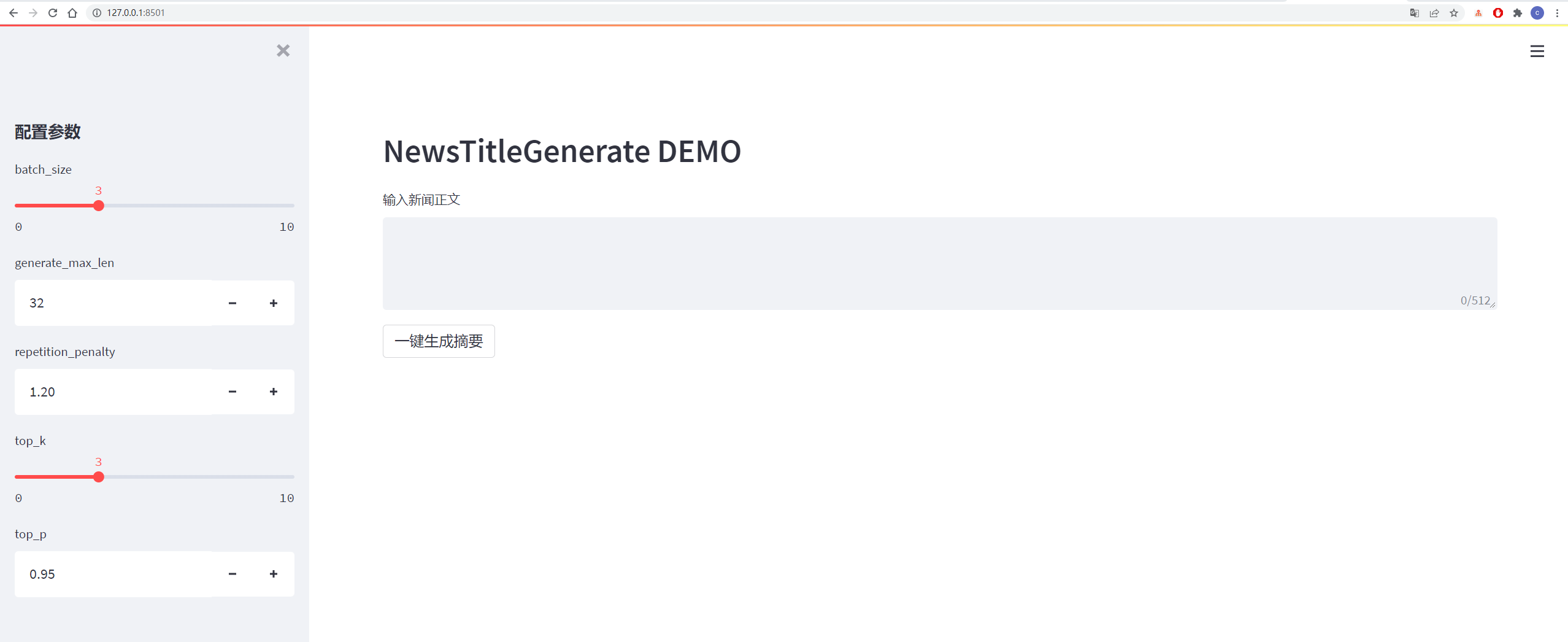
Os detalhes são mostrados na figura abaixo:
| dados | Dados originais/endereço do projeto | Endereço de download do arquivo após o processamento |
|---|---|---|
| Dados de notícias de Tsinghua | endereço | Baidu Cloud Disk Extração Código: Vhol |
| Dados de notícias SOGOU | endereço | Baidu Cloud Disk Extração Código: Ode6 |
| Dados de resumo do NLPCC2017 | endereço | Código de extração de disco em nuvem Baidu: E0ZQ |
| Dados de resumo do CSL | endereço | Baidu Cloud Disk Extração Código: 0QOT |
| Dados de resumo da indústria de educação e treinamento | endereço | Baidu Cloud Disk Extração Código: KJZ3 |
| Dados de resumo do LCSS | endereço | Código de extração de disco em nuvem Baidu: BZOV |
| Dados de resumo de Shence Cup 2018 | endereço | Baidu Cloud Disk Extração Código: 6F4F |
| Dados de resumo de Wanfang | endereço | Baidu Cloud Disk Extração Código: P69G |
| Dados de resumo da conta oficial do WeChat | endereço | Código de extração de disco em nuvem Baidu: 5Has |
| Dados do Weibo | endereço | Baidu Cloud Disk Extração Código: 85T5 |
| Dados de notícias da News2016ZH | endereço | Baidu Cloud Disk Extração Código: QSJ1 |
Coleção do conjunto de dados: Baidu Cloud Disk Extração Código: 7am8
Consulte o arquivo requisitos.txt para obter detalhes
Os dados vêm de Sina Weibo, Link de dados: https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcqq_aiomsg
| Descrição dos dados | Endereço para download |
|---|---|
| Dados brutos | Baidu NetDisk, Código de Extrato: NQZI |
| Dados processados | Baidu NetDisk, Código de Extrato: Duba |
Os dados originais são dados de notícias baixados diretamente da Internet. Após o processamento, os dados são processados usando o data_helper.py e podem ser usados diretamente para treinamento.
Consulte o arquivo config/config.json para obter detalhes
| parâmetro | valor |
|---|---|
| Initializer_Range | 0,02 |
| camada_norm_epsilon | 1E-05 |
| n_ctx | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| N_POSIÇÕES | 512 |
| vocab_size | 13317 |
Nota: Além da representação vetorial de cada palavra, a entrada do modelo também inclui representação do vetor de parágrafo de texto e representação do vetor de posição. 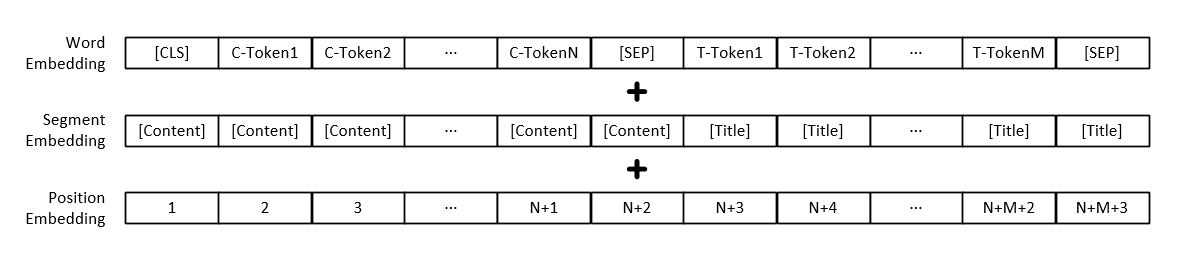
| Modelo | Endereço para download |
|---|---|
| Modelo GPT2 | Baidu NetDisk, Código de extração: 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
Os parâmetros de treinamento podem ser adicionados por você, incluindo os parâmetros da seguinte forma:
| parâmetro | tipo | valor padrão | descrever |
|---|---|---|---|
| dispositivo | str | "0" | Configure a placa gráfica usada para treinamento ou teste |
| config_path | str | "Config/config.json" | Modelo Informações de configuração de parâmetros |
| vocab_path | str | "Vocab/vocab.txt" | A lista de palavras é uma pequena lista de palavras e adicionou algumas novas marcas |
| TRIN_FILE_PATH | str | "Data_Dir/Train_Data.json" | Dados de treinamento gerados por títulos de notícias |
| test_file_path | str | "Data_Dir/test_data.json" | Dados de teste gerados por títulos de notícias |
| pré -tereado_model_path | str | Nenhum | Caminho para o modelo GPT2 pré-treinado |
| data_dir | str | "Data_dir" | Gerar caminho de armazenamento de dados em cache |
| NUM_TRAIN_EPOCHS | int | 5 | Número de rodadas para treinamento de modelo |
| TRIN_BATCH_SIZE | int | 16 | O tamanho de cada lote durante o treinamento |
| test_batch_size | int | 8 | O tamanho de cada lote durante o teste |
| Aprendizagem_rate | flutuador | 1e-4 | Taxa de aprendizado durante o treinamento do modelo |
| warmup_proporção | flutuador | 0.1 | A probabilidade de aquecimento, ou seja, a porcentagem do tamanho total da etapa de treinamento, execute a operação de aquecimento |
| Adam_epsilon | flutuador | 1e-8 | Valor Epsilon do Adam Optimizer |
| logging_steps | int | 20 | Número de etapas para salvar o registro de treinamento |
| EVAL_STEPS | int | 4000 | Quantas etapas serão executadas durante o treinamento? |
| gradiente_accumulation_steps | int | 1 | Acumulação de gradiente |
| max_grad_norm | flutuador | 1.0 | |
| output_dir | str | "Output_dir/" | Caminho de saída do modelo |
| semente | int | 2020 | Sementes aleatórias |
| max_len | int | 512 | O comprimento máximo do modelo de entrada é menor que o N_CTX na configuração |
Ou modifique o conteúdo da função set_args no arquivo Train.py para modificar o valor padrão.
Os modelos fornecidos por este projeto treinaram 5 épocas, e a perda de treinamento de modelos e a perda de conjunto de testes são os seguintes: 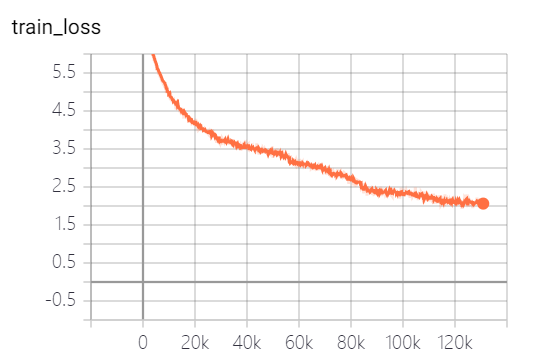
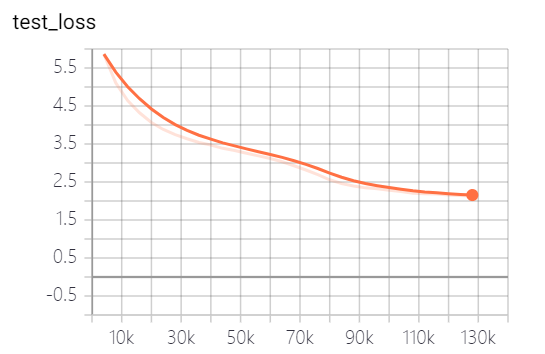
O modelo ainda não foi totalmente treinado. De acordo com a tendência de perda, você pode continuar treinando.
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
Os parâmetros podem ser adicionados por você, incluindo parâmetros da seguinte forma:
| parâmetro | tipo | valor padrão | descrever |
|---|---|---|---|
| dispositivo | str | "0" | Configure a placa gráfica usada para treinamento ou teste |
| Model_Path | str | "Output_dir/Checkpoint-139805" | Caminho do arquivo de modelo |
| vocab_path | str | "Vocab/vocab.txt" | A lista de palavras é uma pequena lista de palavras e adicionou algumas novas marcas |
| batch_size | int | 3 | Número de títulos gerados |
| generate_max_len | int | 32 | Comprimento máximo do título gerado |
| Repetition_peNalty | flutuador | 1.2 | Taxa de penalidade repetida |
| top_k | int | 5 | Quantas tags com a maior probabilidade de reter durante a decodificação |
| top_p | flutuador | 0,95 | Marcadores cuja probabilidade de retenção é maior do que a probabilidade de retenção acumulada durante a decodificação |
| max_len | int | 512 | O comprimento máximo do modelo de entrada é menor que o N_CTX na configuração |
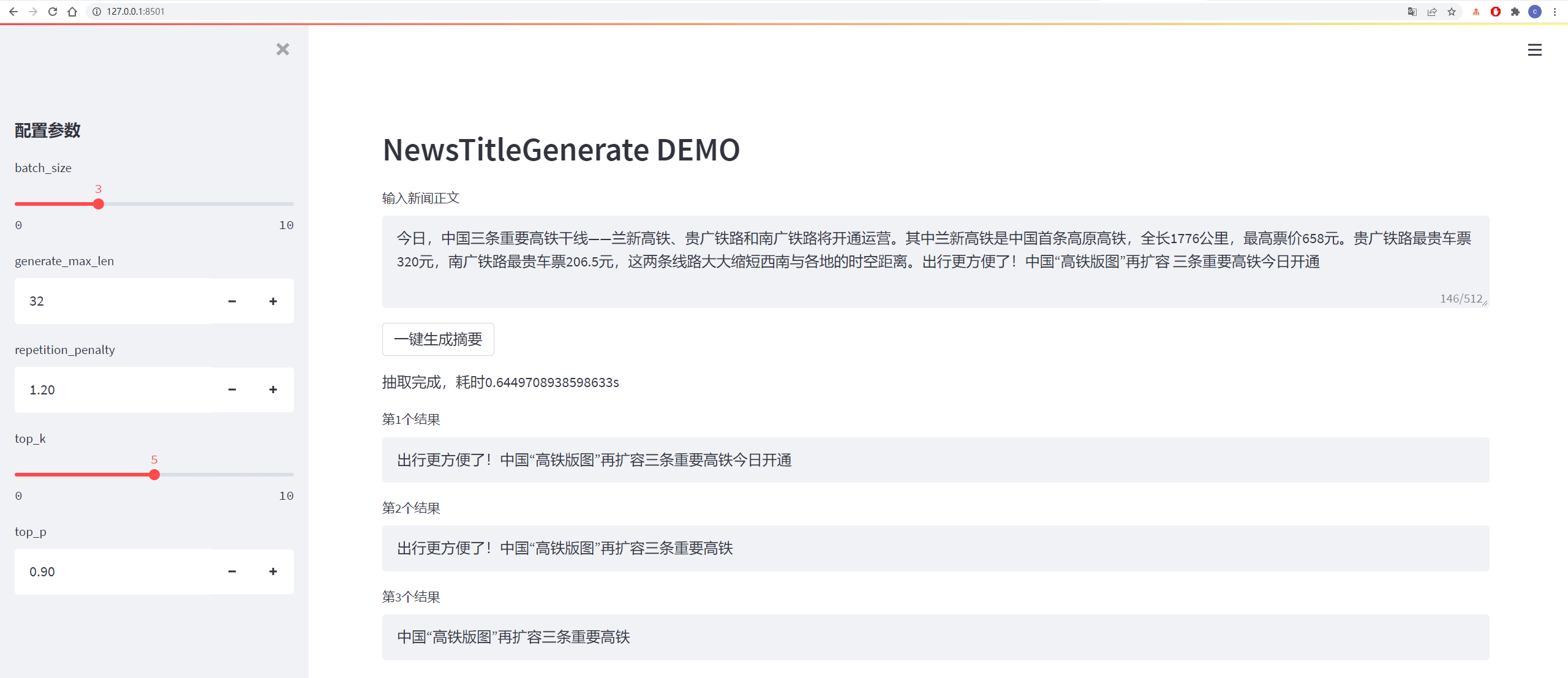
Os resultados dos testes são os seguintes:
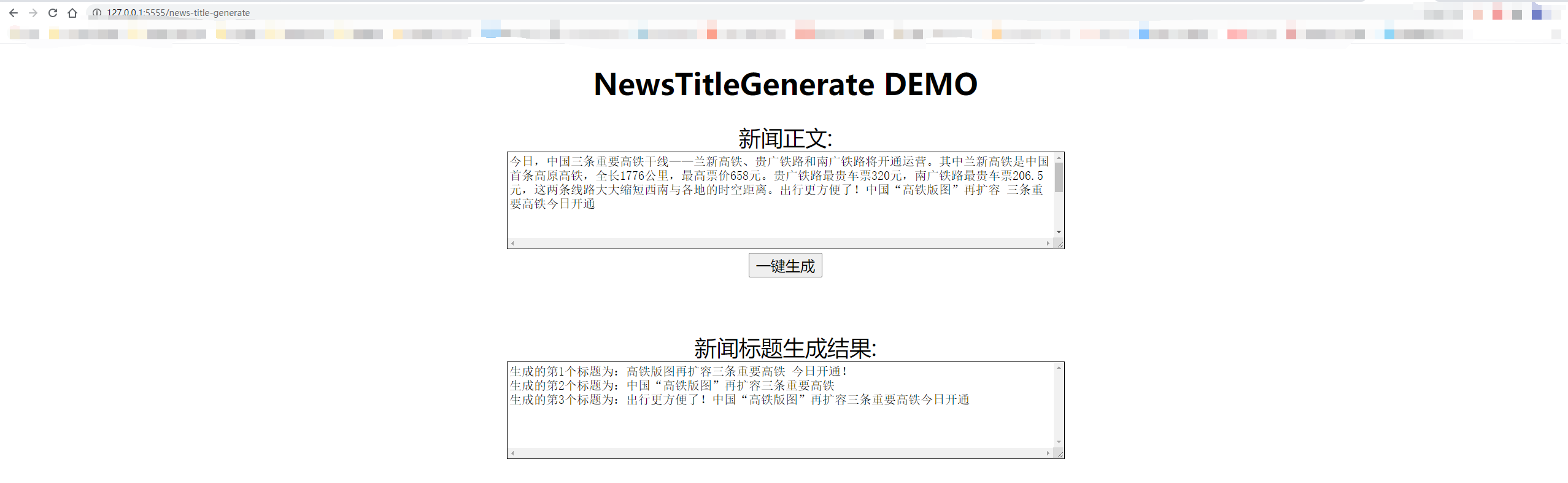
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
A decodificação adota estratégias de decodificação TOP_K e TOP_P, que têm certa aleatoriedade e podem ser geradas repetidamente.
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
Os testes locais usam "127.0.0.1:5555/news-title-generate". Se você fornecer acesso aos outros, precisará apenas substituir "127.0.0.1" pelo endereço IP do computador.
Os detalhes são mostrados na figura abaixo:
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
E-mail: [email protected]
Zhihu: Liu Cong NLP
Conta oficial: estação de trabalho da PNL



