GPT2 NewsTitle
1.0.0
Projet de génération de titres de nouvelles GPT2 avec des annotations super détaillées
Exécuter le code
streamlit run app.py
or
streamlit run app.py --server.port your_port
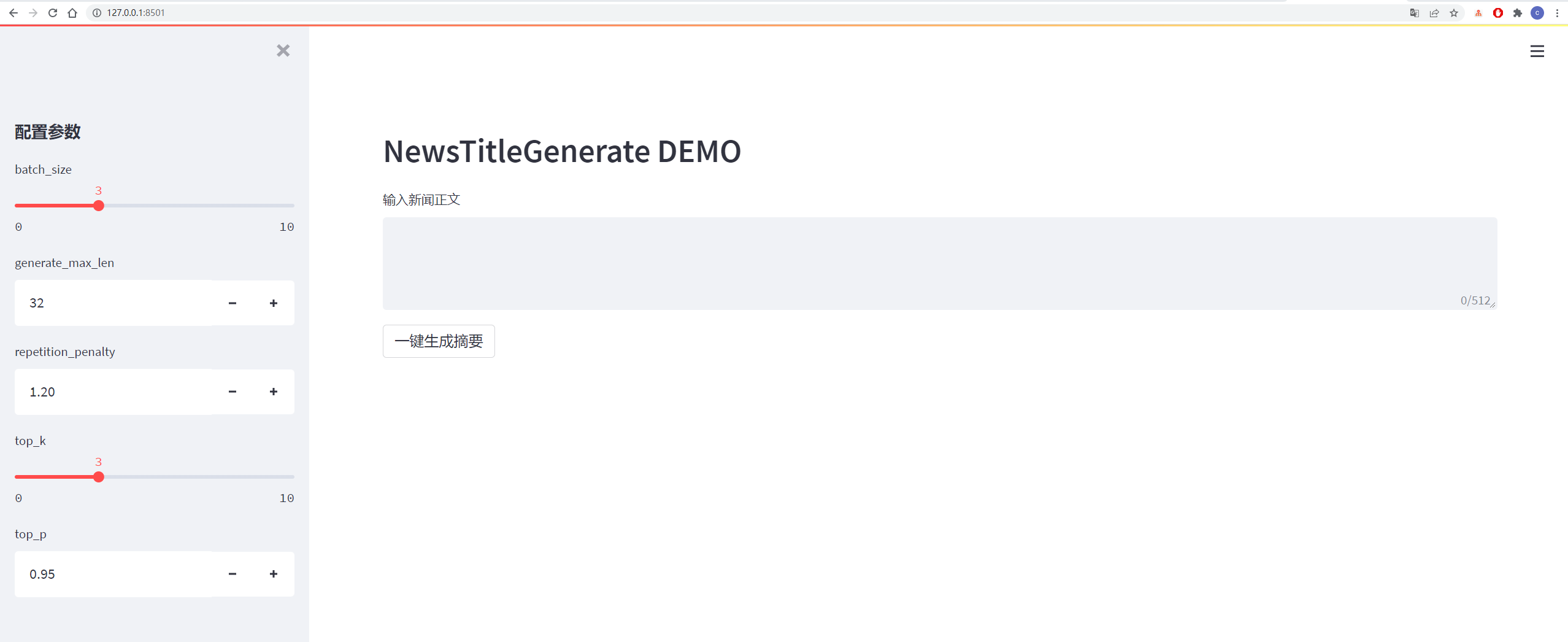
Les détails sont indiqués dans la figure ci-dessous:
| données | Adresse de données / projet d'origine | Adresse de téléchargement de fichiers après traitement |
|---|---|---|
| Tsinghua News Data | adresse | Baidu Cloud Disk Extraction Code: VHOL |
| Données de nouvelles de Sogou | adresse | Baidu Cloud Disk Extraction Code: Ode6 |
| NLPCC2017 Données de résumé | adresse | Baidu Cloud Disk Extraction Code: E0ZQ |
| Données de résumé CSL | adresse | Baidu Cloud Disk Extraction Code: 0Qot |
| Données de résumé de l'industrie de l'éducation et de la formation | adresse | Baidu Cloud Disk Extraction Code: KJZ3 |
| Données de résumé LCSS | adresse | Baidu Cloud Disk Extraction Code: Bzov |
| Shence Cup 2018 Résumé Données | adresse | Baidu Cloud Disk Extraction Code: 6f4f |
| Données de résumé de Wanfang | adresse | Baidu Cloud Disk Extraction Code: P69G |
| Données de résumé du compte officiel de WeChat | adresse | Baidu Cloud Disk Extraction Code: 5Has |
| Données de Weibo | adresse | Baidu Cloud Disk Extraction Code: 85T5 |
| NEWS2016ZH DONNÉES NOUVELLES | adresse | Baidu Cloud Disk Extraction Code: QSJ1 |
Collection d'ensemble de données: Baidu Cloud Disk Extraction Code: 7h88
Voir le fichier exigence.txt pour plus de détails
Les données proviennent de Sina Weibo, lien de données: https://www.jianshu.com/p/8f52352f0748?tdsourcetag=s_pcqq_aiomsg
| Description des données | Adresse de téléchargement |
|---|---|
| Données brutes | Baidu Netdisk, Code d'extrait: NQZI |
| Données traitées | Baidu Netdisk, Extrait Code: Duba |
Les données originales sont des données d'actualités téléchargées directement à partir d'Internet. Après le traitement, les données sont traitées à l'aide de données_helper.py et peuvent être directement utilisées pour la formation.
Voir le fichier config / config.json pour plus de détails
| paramètre | valeur |
|---|---|
| Initializer_Range | 0,02 |
| couche_norm_epsilon | 1E-05 |
| n_ctx | 512 |
| n_embd | 768 |
| n_head | 12 |
| n_layer | 6 |
| n_positions | 512 |
| vocab_size | 13317 |
Remarque: En plus de la représentation vectorielle de chaque mot, l'entrée du modèle comprend également la représentation du vecteur de paragraphe de texte et la représentation des vecteurs de position. 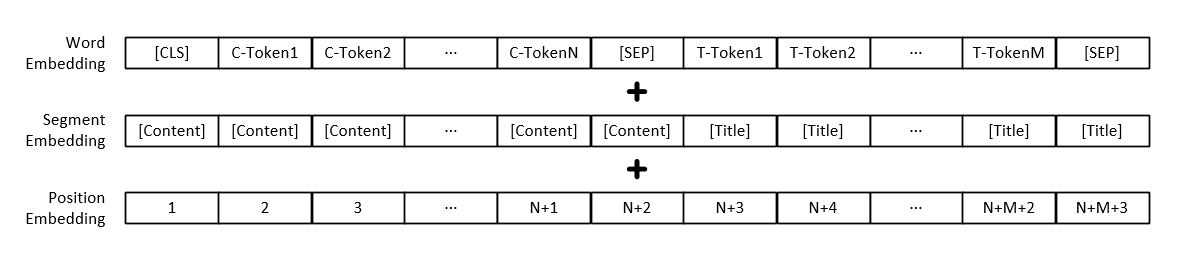
| Modèle | Adresse de téléchargement |
|---|---|
| Modèle GPT2 | Baidu Netdisk, Code d'extraction: 165b |
python3 train.py
或
python3 train.py --output_dir output_dir/(自定义保存模型路径)
Les paramètres de formation peuvent être ajoutés par vous-même, y compris les paramètres comme suit:
| paramètre | taper | valeur par défaut | décrire |
|---|---|---|---|
| appareil | Str | "0" | Configurez la carte graphique utilisée pour la formation ou les tests |
| config_path | Str | "config / config.json" | Informations sur la configuration des paramètres du modèle |
| vocab_path | Str | "Vocab / vocab.txt" | La liste des mots est une petite liste de mots et a ajouté de nouvelles marques |
| Train_file_path | Str | "data_dir / train_data.json" | Données de formation générées par les titres d'actualités |
| test_file_path | Str | "data_dir / test_data.json" | Test des données générées par les titres d'actualités |
| Pretrained_Model_path | Str | Aucun | Chemin vers le modèle GPT2 pré-formé |
| data_dir | Str | "data_dir" | Générer le chemin de stockage des données en cache |
| num_train_epochs | int | 5 | Nombre de tours pour la formation des modèles |
| Train_batch_size | int | 16 | La taille de chaque lot pendant l'entraînement |
| test_batch_size | int | 8 | La taille de chaque lot pendant les tests |
| apprentissage_rate | flotter | 1E-4 | Taux d'apprentissage pendant la formation du modèle |
| warmup_proportion | flotter | 0.1 | La probabilité d'échauffement, c'est-à-dire le pourcentage de la taille totale de l'étape d'entraînement, effectuer l'opération d'échauffement |
| Adam_epsilon | flotter | 1E-8 | Valeur d'Epsilon d'Adam Optimizer |
| logging_steps | int | 20 | Nombre d'étapes pour enregistrer le journal de formation |
| EVAL_STEPS | int | 4000 | Combien d'étapes seront effectuées pendant l'entraînement? |
| gradient_accumulation_steps | int | 1 | Accumulation de gradient |
| max_grad_norm | flotter | 1.0 | |
| output_dir | Str | "output_dir /" | Chemin de sortie du modèle |
| graine | int | 2020 | Graines aléatoires |
| max_len | int | 512 | La longueur maximale du modèle d'entrée est inférieure à N_CTX dans la configuration |
Ou modifiez le contenu de la fonction set_args dans le fichier Train.py pour modifier la valeur par défaut.
Les modèles fournis par ce projet ont formé 5 époques, et la perte de formation du modèle et la perte de tests sont les suivantes: 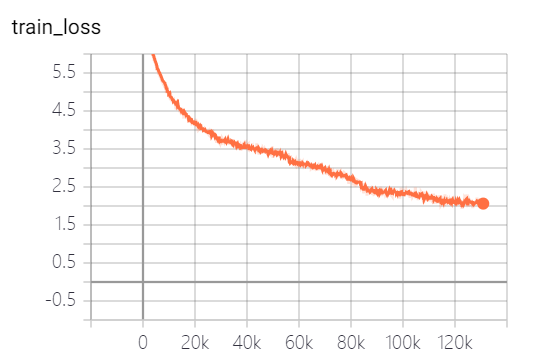
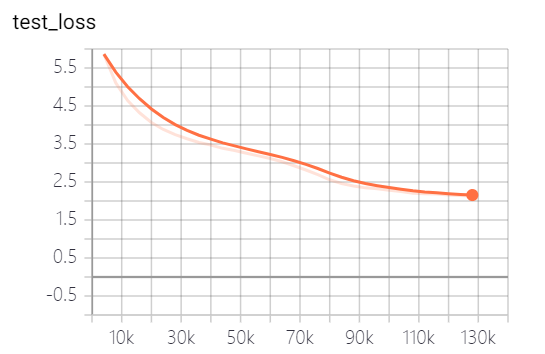
Le modèle n'a pas encore été entièrement formé. Selon la tendance des pertes, vous pouvez continuer à vous entraîner.
python3 generate_title.py
或
python3 generate_title.py --top_k 3 --top_p 0.9999 --generate_max_len 32
Les paramètres peuvent être ajoutés par vous-même, y compris les paramètres comme suit:
| paramètre | taper | valeur par défaut | décrire |
|---|---|---|---|
| appareil | Str | "0" | Configurez la carte graphique utilisée pour la formation ou les tests |
| modèle_path | Str | "output_dir / checkpoint-139805" | Chemin de fichier modèle |
| vocab_path | Str | "Vocab / vocab.txt" | La liste des mots est une petite liste de mots et a ajouté de nouvelles marques |
| batch_size | int | 3 | Nombre de titres générés |
| générer_max_len | int | 32 | Longueur maximale du titre généré |
| répétition_penalty | flotter | 1.2 | Taux de pénalité répété |
| top_k | int | 5 | Combien d'étiquettes avec la plus grande probabilité de conservation pendant le décodage |
| top_p | flotter | 0,95 | Marqueurs dont la probabilité de rétention est supérieure à ce qui est la probabilité de rétention accumulée pendant le décodage |
| max_len | int | 512 | La longueur maximale du modèle d'entrée est inférieure à N_CTX dans la configuration |
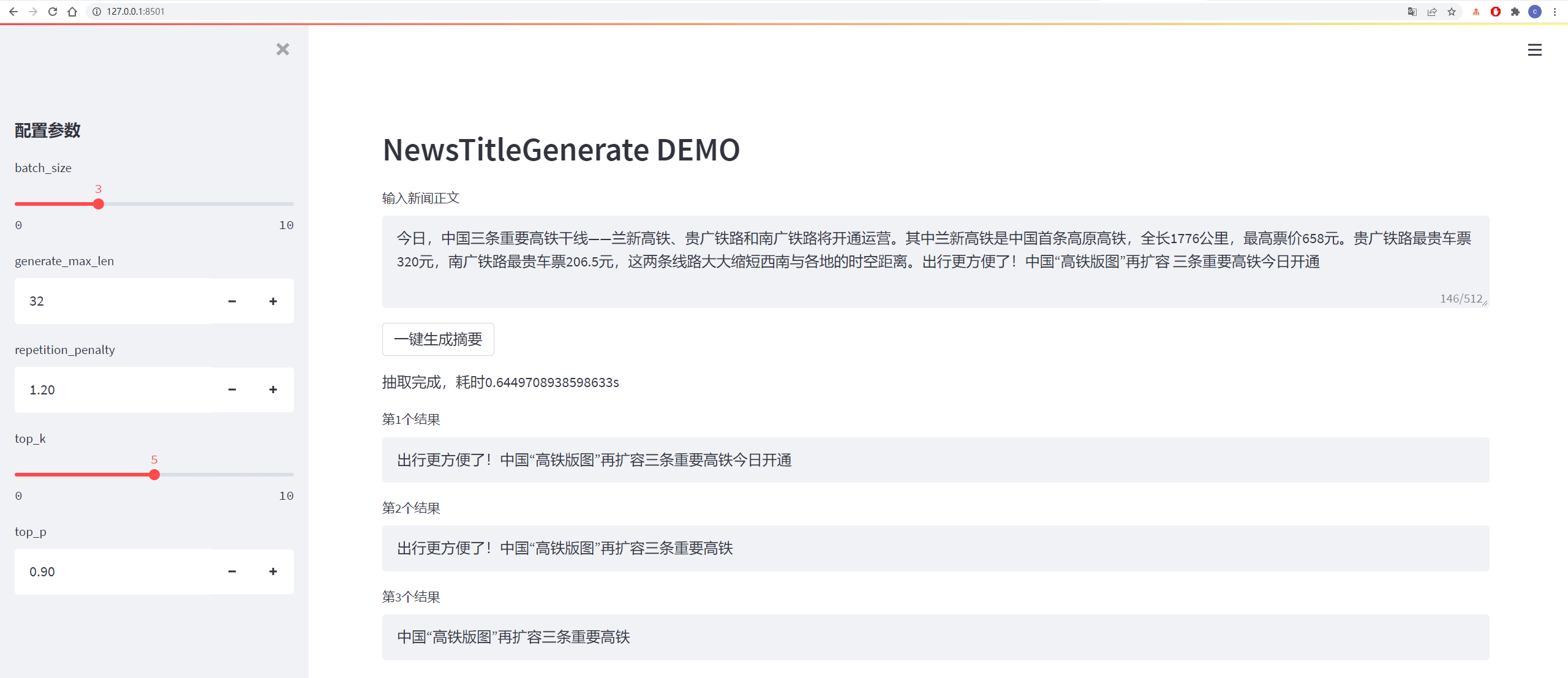
Les résultats des tests sont les suivants:
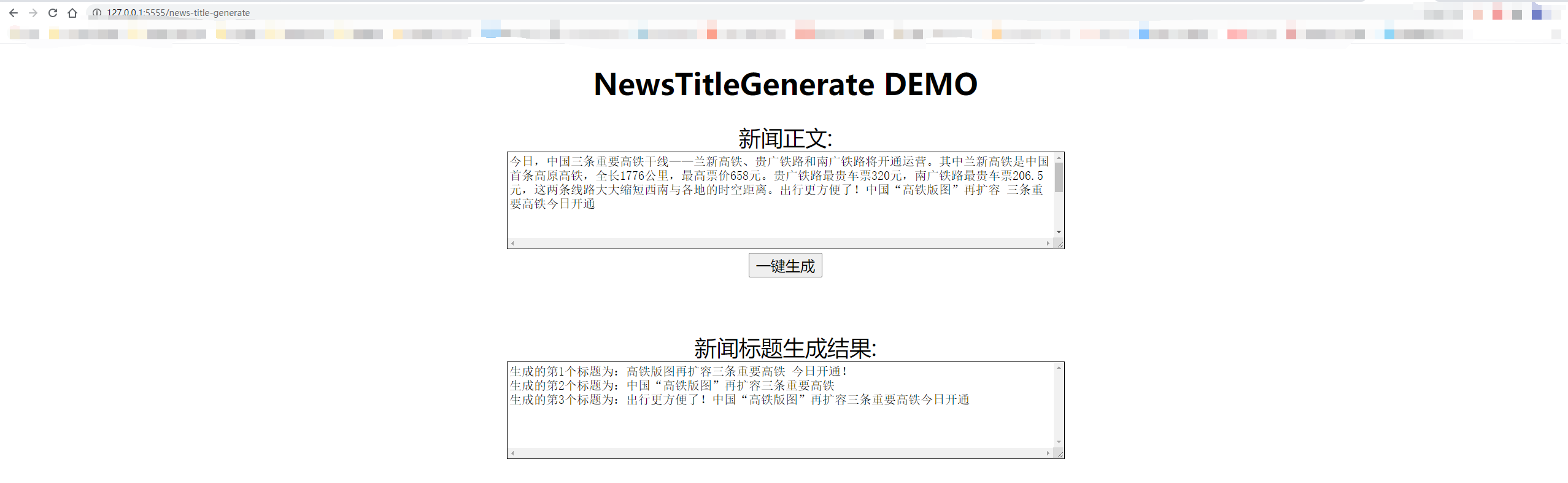
从测试集中抽一篇
content:
今日,中国三条重要高铁干线——兰新高铁、贵广铁路和南广铁路将开通运营。其中兰新高铁是中国首条高原高铁,全长1776公里,最高票价658元。贵广铁路最贵车票320元,南广铁路最贵车票206.5元,这两条线路大大缩短西南与各地的时空距离。出行更方便了!中国“高铁版图”再扩容 三条重要高铁今日开通
title:
生成的第1个标题为:中国“高铁版图”再扩容 三条重要高铁今日开通
生成的第2个标题为:贵广铁路最高铁版图
生成的第3个标题为:出行更方便了!中国“高铁版图”再扩容三条重要高铁今日开通
从网上随便找一篇新闻
content:
值岁末,一年一度的中央经济工作会议牵动全球目光。今年的会议,背景特殊、节点关键、意义重大。12月16日至18日。北京,京西宾馆。站在“两个一百年”奋斗目标的历史交汇点上,2020年中央经济工作会议谋划着中国经济发展大计。习近平总书记在会上发表了重要讲话,深刻分析国内外经济形势,提出2021年经济工作总体要求和政策取向,部署重点任务,为开局“十四五”、开启全面建设社会主义现代化国家新征程定向领航。
title:
生成的第1个标题为:习近平总书记在京会上发表重大计划 提出2025年经济工作总体要求和政策
生成的第2个标题为:习近平总书记在会上发表重要讲话
生成的第3个标题为:习近平总书记在会上发表重要讲话,深刻分析国内外经济形势
Le décodage adopte les stratégies de décodage TOP_K et TOP_P, qui ont une certaine aléatoire et peuvent être générées à plusieurs reprises.
python3 http_server.py
或
python3 http_server.py --http_id "0.0.0.0" --port 5555
Les tests locaux utilisent "127.0.0.1:5555/news-title-genereate". Si vous donnez aux autres un accès, il vous suffit de remplacer "127.0.0.1" par l'adresse IP de l'ordinateur.
Les détails sont indiqués dans la figure ci-dessous:
@misc{GPT2-NewsTitle,
author = {Cong Liu},
title = {Chinese NewsTitle Generation Project by GPT2},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
url="https://github.com/liucongg/GPT2-NewsTitle",
}
Courriel: [email protected]
Zhihu: liu cong nlp
Compte officiel: NLP Workstation



